


AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


 |
こんにちは、白鳥です。 |
|---|
AWSのアーキテクチャを設計する際に、アベイラビリティゾーンの利用数について検討することが多くあるかと思います。多くの場合は2つにすべきか、3つにすべきか、ということが論点になりますが、アベイラビリティゾーンの利用数の検討の仕方について、最新の事例やベストプラクティスを踏まえて少し考察してみたいと思います。
想定する読者
AWSの可用性設計やアベイラビリティゾーン構成に関するご相談について、NTT東日本のクラウドエンジニアがお応えします。お気軽にご連絡ください。

いきなりですが、本コラムの結論を書きます。
では、なぜ3アベイラビリティゾーン利用が推奨されるか、2以下にできるケースとその際の考慮事項をまとめていきたいと思います。
AWSの可用性設計やアベイラビリティゾーン構成に関するご相談について、NTT東日本のクラウドエンジニアがお応えします。お気軽にご連絡ください。
基本的には複数のアベイラビリティゾーン利用が推奨されることは、AWS Well-Architected Frameworkの可用性の柱にも記載されています。
Distribute workload data and resources across multiple Availability Zones or, where necessary, across AWS Regions.
(日本語訳:ワークロードのデータとリソースは複数のアベイラビリティゾーン、または必要に応じてAWSリージョンをまたいで分散させましょう)
ここには3つか2つかは明記されていませんが、複数使うことが示されています。「キャパシティ」「静的安定性」「SLA設計」「マネージドサービス利用」「最近の大規模障害事例」の観点で2アベイラビリティゾーン利用より3アベイラビリティゾーン利用を推奨できます。
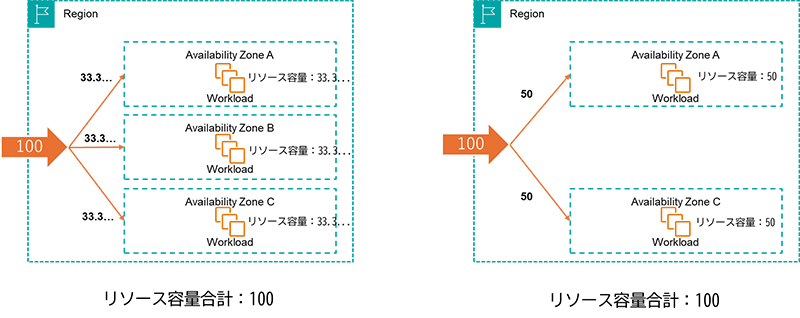
平常時はそれぞれのトラフィックが各アベイラビリティゾーンで均等に分散され処理しています。この時に必要なリソースのサイズも、それぞれ分散されたトラフィックを処理できるサイズがあれば賄うことができます。100のトラフィックを処理するワークロードで考えると、平常時は3アベイラビリティゾーンの場合は33.3…、2アベイラビリティゾーン利用の場合は50の容量をプロビジョンニングすればよいとします
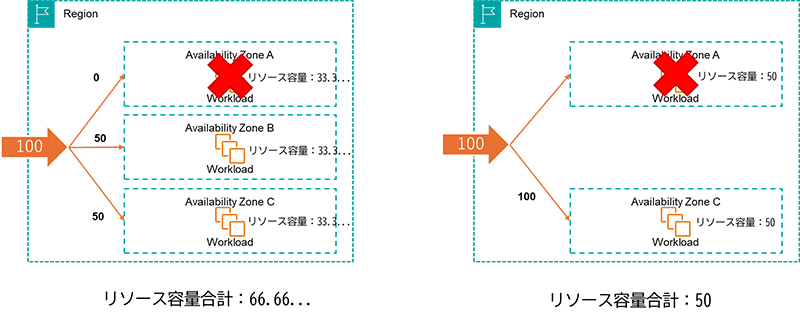
この時に、アベイラビリティゾーンAに障害が起きたとします。アベイラビリティゾーンAに立てられたリソースは使うことができません。すると、処理できるトラフィックが残ったアベイラビリティゾーンに分散することになり、すべてのトラフィックを処理することができなくなります。3アベイラビリティゾーン利用の場合は、33.3...、2アベイラビリティゾーンの場合は50の容量が足りなくなります。
この時に、いずれか1つのアベイラビリティゾーン障害が起きてもすべてのトラフィックを処理できるようにするには3アベイラビリティゾーン利用の場合は各50、2アベイラビリティゾーンの場合は各100を割り当てる必要があります。
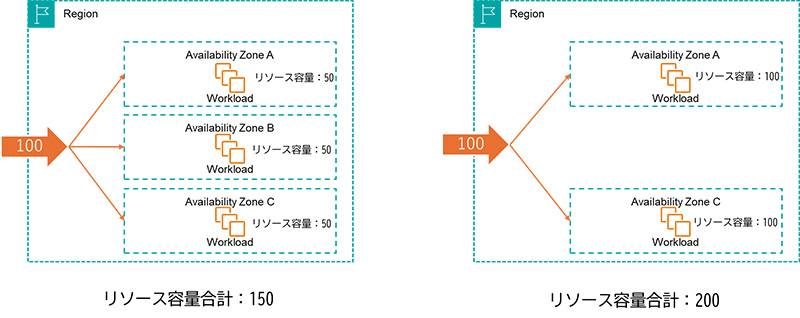
すると、平常時には利用しない余剰リソースが生まれることになり、このケースでは2アベイラビリティゾーン利用のほうが高コストになることになります。
前述のキャパシティ設計のところで、こう思われた方がいらっしゃるかもしれません。
「アベイラビリティゾーン障害の時にAuto ScalingやAWSの設定変更で対応すればコスト最適化されるのではないか?」
実は、ここに落とし穴があります。
AWSには「コントロールプレーン」と「データプレーン」の2つがあり、コントロールプレーンでリソースの作成や削除といった機能を、データプレーンで処理や保存といった機能を担っています。コントロールプレーンはデータプレーンより複雑な処理を行うため、データプレーンより可用性が低くなっており、基本的にはコントロールプレーンに依存しない設計を行うことがベストプラクティスとされています。このことを静的安定性といいます。詳しくは下記のホワイトペーパーも参照いただければと思います。
AWS障害分離境界
アベイラビリティゾーン障害の際にこうした操作が輻輳する可能性もあり、いざというときに障害復旧手順がうまくいかない、という可能性を下げること目的としています。
各サービスにはSLAが定められており、たとえばALBは99.99%、Amazon EC2は99.99%(リージョンレベル)、マルチAZのRDSの稼働率は99.95%となります。これらを直列に並べた場合のSLAは約99.93%となります。並列に並べると2アベイラビリティゾーン利用で99.9995%となります。平常時では十分な稼働率を出すことができますが、1つのアベイラビリティゾーンに障害が起き使えなくなっても安全な稼働率でいるためには、3アベイラビリティゾーンの利用が推奨されます。
昨今のマネージドサービスは3アベイラビリティゾーン利用が前提になっています。たとえば、Amazon Auroraではライターインスタンス1つ+リーダーインスタンスを別アベイラビリティゾーンに配置し、ストレージは6コピーを3つアベイラビリティゾーンに2つずつ分散するような設計がなされています。
ほかにもAmazon S3やDynamoDBも複数のアベイラビリティゾーンに自動的に分散されることや、EKSはワーカーノードを3アベイラビリティゾーンに分散させることが通常の推奨動作となっています。
2026年3月にAWSのUAEリージョン及びバーレーンリージョンでのアベイラビリティゾーン障害が起き、執筆日(2026年5月上旬)時点では復旧に至っていません。
引用:https://health.aws.amazon.com/health/status(本ページは随時変更されるため、同内容が表示されないこともあります。)
本コラムでは障害の原因や詳細についての言及は避けますが、この障害で特徴的なのは、3つのうち2つのアベイラビリティゾーンに障害が起きたということです。つまり、複合的な要因によって複数のアベイラビリティゾーンに障害が起きる可能性はあるため、できるだけ多くのアベイラビリティゾーンに分散しておく必要があります。
AWSの可用性設計やアベイラビリティゾーン構成に関するご相談について、NTT東日本のクラウドエンジニアがお応えします。お気軽にご連絡ください。
ここまでで、3アベイラビリティゾーン利用の推奨理由について考察してきましたが、2アベイラビリティゾーン以下の利用を検討する場合は、どのような観点が必要でしょうか?
さきほど、99.99%のSLAを保つためには3アベイラビリティゾーン利用が必要としましたが、SLAが99.9%以下であれば2アベイラビリティゾーン以下の構成でも成立します。可用性のそれほど高くない(99.9%以下)ワークロードや、開発・ステージング環境では、2アベイラビリティゾーン以下の構成でもよいでしょう。
ただし、SLAの計算は「各アベイラビリティゾーンが独立して障害を起こすこと」が前提です。ソフトウェアのバグや複数アベイラビリティゾーンの同時障害、上位ネットワーク障害(Route 53の設定ミスやTransit Gatewayなど)によるリージョンレベルの障害は別で考える必要があります。
小規模構成や、予算の少ないワークロードではアベイラビリティゾーンごとに必要となるNATゲートウェイ(1つあたり月50ドル程度)やインターフェースVPCエンドポイント(1つあたり10ドル程度)が重荷になることもあります。可用性とコストをトレードオフして、アベイラビリティゾーン数を減らす検討を行うことができます。
AWSの可用性設計やアベイラビリティゾーン構成に関するご相談について、NTT東日本のクラウドエンジニアがお応えします。お気軽にご連絡ください。
また、障害に備えてテストを行っておくことが必要です。しかし、AWSにアベイラビリティゾーンを止めてくれというお願いはできないため、シミュレーションによる実行を行うことが現実になります。
AWSではFISというサービスを使って、アベイラビリティゾーンの電源断をシミュレーションするテストが行えるようになっています。これによって、これらの項目をテストしていくことが大事になります。
AWSの可用性設計やアベイラビリティゾーン構成に関するご相談について、NTT東日本のクラウドエンジニアがお応えします。お気軽にご連絡ください。
今回はアベイラビリティゾーンの利用数についての考察を行いました。必要キャパシティの観点、静的安定性の観点、SLAの観点、マネージドサービスの設計の観点、複数アベイラビリティゾーンの同時障害の観点から3アベイラビリティゾーンの利用を推奨し、SLAとコストのトレードオフで99.9%以下のワークロードであれば2アベイラビリティゾーンまたはシングル構成も検討できるので、要件に合わせて設計いただければと思います。
NTT 東日本では、AWSの構築保守だけではなく、ネットワーク設計なども含めたエンドツーエンドでのソリューション提供を行っております。
経験値豊かなメンバーがご担当させていただきますので、是非お気軽にお問い合わせください!





相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

