
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()

 |
こんにちは、データサイエンティストの本堂です。 今年から後天的な花粉症になってしまい、この苦しみと戦い続けてきた人々への尊敬と鼻水が止まらない日々を過ごしています。 今回は、生成AIを誰でも使えるようになったから今だからこそ陥りやすいデータ分析の注意点をご紹介します。 |
|---|
近年、生成AIの進化によって、エクセルをはじめとするさまざまなデータソースから、誰でも手軽にデータ分析ができるようになりました。売上データの集計、アンケートの要約、施策効果の比較など、これまで専門知識が必要だった作業も短時間でこなせるようになり、ビジネスのスピードはこれまで以上に加速しています。
一方で、生成AIは便利で強力なツールですが、外れ値・相関と因果・サンプルサイズ・サンプリングバイアスなど、データ分析が本来抱える落とし穴まですべて見抜けるわけではありません。
これらは本来人間が確認して気を付けるべきポイントですが、AIが分析を“それっぽく整えた文章”で返してくれるために、かえって見落とされやすくなるという新しいリスクも生まれています。
本記事では、
をビジネス担当者向けにもわかりやすく解説します。
この記事のゴールは、読者が生成AIの分析結果を“正しく疑い”、自信を持って意思決定できるようになることです。章の最後では、正しくデータ分析をするためのチェックリストも記載していますので、AIを使った分析機会が増えてきた方や、「分析結果が直感とズレることが増えた」という方は、ぜひ参考にしてください。
生成AIを活用したデータ分析についてNTT東日本のデータサイエンティストがご相談にお応えします!お気軽にお問い合わせください。

社内で社員のエンゲージメントを把握するために、Teamsやgoogle formなどでアンケートを作成・配布し、回答してもらった結果から調査をするような場面を想定します。
アンケート結果として以下のような仮のデータを作成し、生成AIとしてCopilotを使って分析をしてみます。
Copilotには「エンゲージメントの可視化をしてください。」と指示を投げます。
アンケートデータの一部:
| 社員ID | 所属部門 | 勤務地 | エンゲージメント自己評価_1to5 |
|---|---|---|---|
| E002 | コーポレート | 東京 | 4 |
| E004 | 開発 | 東京 | 4 |
| E006 | 営業 | 名古屋 | 4 |
| E009 | 開発 | 大阪 | 4 |
| E012 | 営業 | 東京 | 4 |
| E013 | コーポレート | 東京 | 3 |
| E014 | コーポレート | 東京 | 3 |
| E015 | 開発 | 名古屋 | 3 |
Copilotからの回答の一部:
対象は 119名、全体平均は 3.73 / 5、中央値は 4.0でした。4〜5評価は63.9%、1〜2評価は4.2% です。
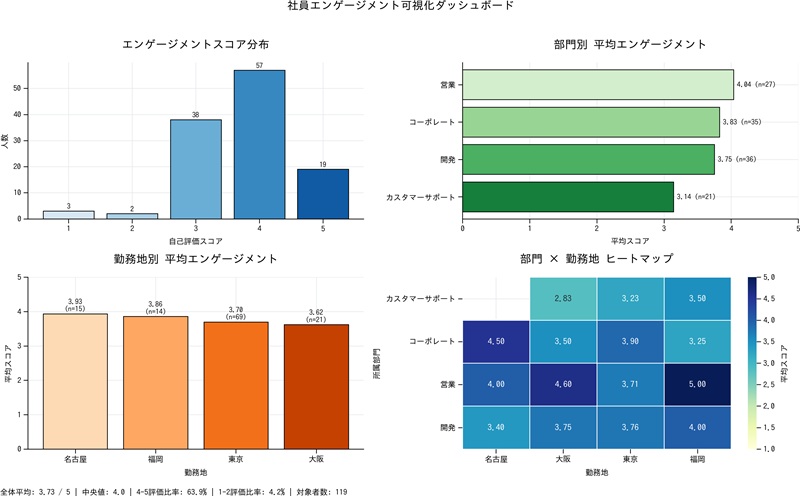
データと簡単な指示を投げるだけで、Copilotからはエンゲージメントに関する示唆と可視化結果が得られました。この示唆とグラフを見る限り、多くの社員がやりがいをもって働いてくれているように見えます。
ただし、この結果だけで「社員のエンゲージメントに問題はない」と結論づけるのは早計です。そもそも、誰が回答していないのか、回答者に偏りがないかまでは、この時点ではわかりません。
続いて、社内で「人事評価が高い人」の分析を行うことになった場面を考えてみます。
以下のような仮データを作成し、Copilotに「人事評価が高い人の傾向を教えて」という指示文を投げることで分析を実施しました。
人事評価データの一部:
| 社員ID | 所属部門 | 勤務地 | 職位 | 勤続年数帯 | 月間労働時間 | 残業時間 | 1on1回数 | 有給取得日数 | 人事評価スコア_5段階 |
|---|---|---|---|---|---|---|---|---|---|
| P001 | 営業 | 名古屋 | 主任 | 1-3年 | 177 | 17 | 3 | 0 | 4.2 |
| P002 | 営業 | 東京 | 主任 | 4-7年 | 204 | 44 | 4 | 0 | 4.3 |
| P003 | コーポレート | 東京 | メンバー | 4-7年 | 171 | 11 | 3 | 1 | 3.0 |
| P004 | 開発 | 東京 | 主任 | 8年以上 | 161 | 1 | 3 | 0 | 2.8 |
| P005 | 開発 | 東京 | メンバー | 8年以上 | 170 | 10 | 1 | 0 | 3.2 |
| P006 | 営業 | 東京 | メンバー | 4-7年 | 164 | 4 | 1 | 1 | 2.8 |
| P007 | 開発 | 東京 | メンバー | 1-3年 | 172 | 12 | 2 | 0 | 3.3 |
| P008 | 開発 | 東京 | 主任 | 4-7年 | 162 | 2 | 2 | 2 | 3.4 |
| P009 | 開発 | 名古屋 | 主任 | 8年以上 | 183 | 23 | 2 | 0 | 3.6 |
Copilotからの回答の一部:
労働時間が長いほど評価が高い傾向が強いです。評価との相関は0.842と最も強く、時間帯別平均でも149時間以下: 2.66 → 150–169時間: 3.19 → 170–189時間: 3.63 → 190時間以上: 4.22と、かなりはっきり右肩上がりです。
残業時間も多いほど高評価寄りで、相関は0.772です。残業帯別平均は0時間: 2.83、1–10時間: 3.32、11–20時間: 3.58、21時間以上: 4.01でした。
1on1回数は「強い要因ではないが、ややプラス」です。相関は0.192で、平均スコアは0–1回: 3.16、2回: 3.29、3回以上: 3.43でした。
…
結論として、「労働時間や残業時間が長いと、人事評価も高い傾向がある」と分析をしてくれました。
一見すると説得力のある分析ですが、ここで示されているのはあくまで「相関」であり、長時間労働が高評価の直接の原因であるとは限りません。(後ほど詳しく説明します)
生成AIを活用したデータ分析についてNTT東日本のデータサイエンティストがご相談にお応えします!お気軽にお問い合わせください。
生成AIは「まとめ」「整形」「説明」が得意です。先ほどの例のように、データを読みこませれば、説得力のある要約を生成してくれます。しかし、たとえ データの前提や品質が曖昧なままでも、生成AIは“もっともらしい答え”を返してしまいます。
たとえば、他のデータとは極端にずれているデータ(外れ値)が混ざっていたり、サンプルが偏っていたりしていても、その問題点を指摘せずに、きれいに整った結論をつくり上げてしまいます。
本来、これらの「データの前提」「データ品質」「指標の定義」などは、人間が確認しながら分析し、意思決定に反映すべき部分です。しかし、前提やデータ品質の点検を人が担保しないと、ズレを見落としやすくなります。
以下では、データ分析における落とし穴として「外れ値」「相関と因果」「サンプルサイズ不足」「サンプリングバイアス」の4つについて紹介します。
外れ値とは、「他と比べて極端に小さな値、あるいは極端に大きな値」のことを指します。わかりやすい例でいうと、例えば営業組織の売上分析で、通常は月商100万円前後の担当者が多い中、特定の大型案件を担当した1名だけが月商1億円だった場合、その1名の数値が平均を大きく押し上げます。
このように、外れ値の存在に気付かないまま出力される値をうのみにしてしまうことで、誤った意思決定につながってしまう可能性があります。
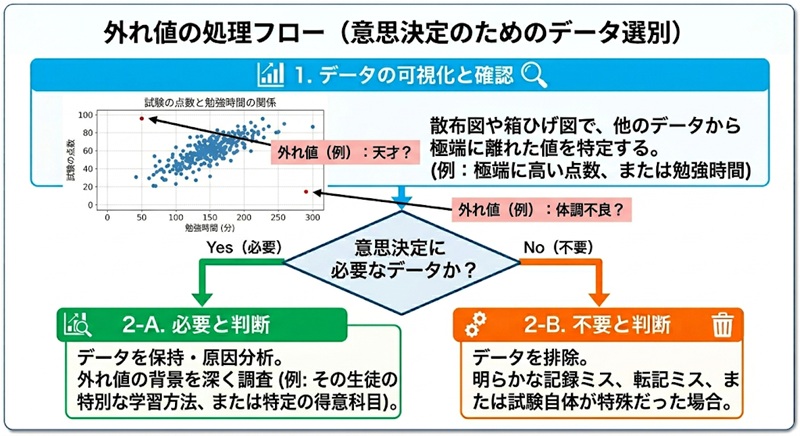
外れ値に関しては実際に得られたデータを以下のように散布図、もしくはヒストグラムなどで可視化したうえで、そのデータが「意思決定をするうえで必要なデータなのか」を判断し、必要でなければ排除するなど、適切な対処が必要です。
特に、人手で入力するようなデータの場合は入力ミスなどが外れ値の要因になりうるため、注意が必要です。
また、逆に外れ値が貴重な分析サンプルとなる可能性もあります。
下記の図のような、勉強時間と試験の点数の関係を分析する際に、少ない勉強時間で高い点数を取れているようなサンプルが得られた場合、効率的な学習方法の調査として、貴重な分析対象となる可能性があります。
このように、外れ値はその背景までを調査したうえで適切に処理する必要があります。
第1章では、Copilotを活用して「人事評価が高い人の傾向」を分析し、労働時間や残業時間と人事評価の間に一定の関係が見られることを確認しました。ここでは、そのような分析結果を解釈するうえで重要となる「相関」と「因果」の違いについて説明します。
相関関係とは「AとBは同時に増えてる、減ってるなど、2つの事象が連動して変化する関係」のことを言います。第一章の分析では、労働時間や残業時間が多い人ほど評価も高い傾向があることが確認されました。そのため、「労働時間の長さ」や「残業時間の長さ」と、「人事評価の高さ」は相関していると言えます。
それに対して因果関係とは「一方が原因となり、もう一方が結果として生じる関係」のことを言います。
つまり、仮に「人事評価が高いのは、労働時間の長さによるもの」という関係性がある場合に、「労働時間」と「人事評価」の間に因果関係がある ということができます。
因果関係が認められた場合は、人事評価を高くするためにより長く働こう といった施策を打ち出すことができます。
注意が必要なのは、第一章で分析できた傾向はあくまで「相関関係」であり、「因果関係」ではない点です。例えば、「労働時間」と「人事評価」という2つの要素の相関は、「対応する案件の大きさ」という第三の事象によって引き起こされている可能性があります。図に示すと、これらの関係は以下の右図のような関係性になっていると考えられます。
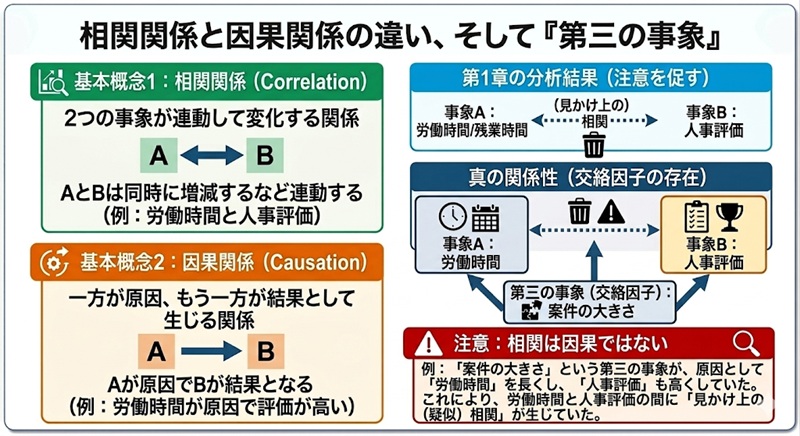
正しい因果関係としては、「より大きい規模の案件を持つ人が、高い人事評価を受ける」ですが、大きい案件を持つ人は自然と労働時間も長くなるため、労働時間と人事評価の間に相関関係が見られたというわけです。このように、第三の要因(交絡因子)によって生じる見かけ上の相関を疑似相関といいます。
データ分析では、分析の手がかりとして相関を見つけること自体は重要ですが、それをそのまま因果関係とみなさないことが大切です。
実際に因果関係を見つけるのは、そのドメインに関する深い知識と、データサイエンスの手法(A/Bテストを含むランダム化比較実験など)が必要になるため、いきなりそこまで学んで意識する必要はありませんが、データの背景の関係性を全く考えずに分析をしてしまうと、誤った傾向を導き出してしまう可能性があるため、注意が必要です。そのため、まずは以下のような事象の関係図(DAG: 因果ダイアグラム)を仮説をたてながらデータ収集前に描いてみることで頭の整理ができ、収集の抜け漏れや、誤った結論を導いてしまうことを防げる可能性が大きくなります。
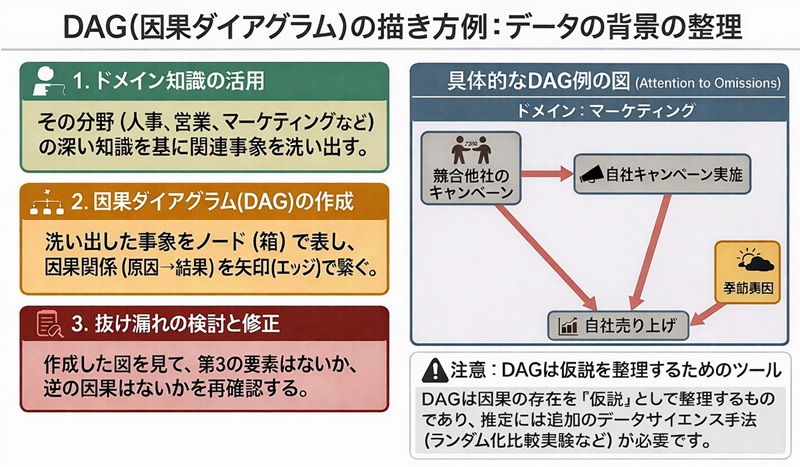
分析を行うために集めたデータ数のことをサンプルサイズと言います。また、調査をしたい対象の集団のことを母集団と言います。先ほどのデータ分析事例(1-1)で、アンケートで社員の調査を行う場面を想定しましたが、この場合は、会社の社員全員が母集団になり、アンケートに回答してくれた人数がサンプルサイズとなります。
当たり前な話ですが、サンプルサイズが少なすぎると母集団との乖離が大きくなってしまい、調査結果に対する信頼性が低下してしまいます。とはいえ、サンプルサイズを多く集めるためにはコストもかかります。
どれくらいのサンプルを集めれば信頼性のある示唆になるかについては、色々と議論があり、詳細の説明は割愛しますが、データ収集の前段階で、「行いたい意思決定」に対して「データ数が明らかに足りていないようなデータ収集を検討していないか」を確認しておくべきです。
先ほどの話はサンプルサイズの話でしたが、サンプルサイズが十分であれば安心というわけではありません。たとえサンプル数が多くても、回答している人の“偏り”があると結果がゆがむことがあります。この偏りのことを サンプリングバイアス と言います。
例えば、先ほどの社内アンケートの分析例だと、社員のエンゲージメントを把握するために、アンケートを作成・配布し、調査するような場面を想定しました。分析結果としては、「多くの社員が高いエンゲージメントで働けていそう」と示唆が出ましたが、本当にそうでしょうか?
例えば、日中の業務が忙しく通知を見逃してしまった人や、日々の活力がなくアンケートにも回答する気力がない人 なども社員の中にいて、回答してくれたのは、比較的業務に余裕があったり、もともと活力的な人たちが多く、それによってエンゲージメントが本来より高く集計されてしまっていた可能性もあります。
このように、回答しやすい人・積極的な人だけがサンプルに集まってしまうと、たとえサンプルサイズが大きくても、母集団とは違う“偏った一部の声”だけを集めた調査になってしまいます。
その結果、「ポジティブ意見が増えた」「満足度が向上した」といった“良い数字”が出てしまい、本来把握したかったはずのものとは異なる結論につながることがあります。
また、注意すべきは属性的な観点だけでなく時系列的な観点も重要です。キャンペーン効果の分析などを行うときに、1年間のデータだけを分析対象としてしまうと売り上げの増減がキャンペーンの効果なのか、季節性によるものなのか などの判別がつきにくくなってしまいます。
サンプルサイズの問題と同様ですが、データを収集・生成AIへ分析をお願いする前に、検討したデータの収集方法によって、「分析したい対象」から満遍なくデータを集められるのかも検討が必要です。
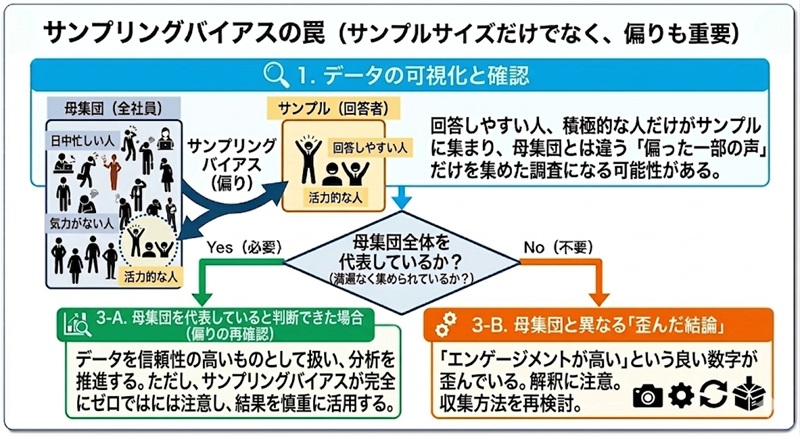
ここまでのデータ分析の落とし穴を整理しつつ、生成AIが得意なことと不得意なことについても説明をしていきます。
生成AIは以下のような項目が得意です。既にあるものに対して示唆を出すといったことに対しては非常に高いレベルでアウトプットをしてくれます。
一方で、先ほどの落とし穴で説明したように、以下のような項目は苦手です。
生成AIに投げる指示文を工夫することで、生成AIが持ち合わせている知識からある程度の対処はしてくれますが、それでも注意は必要です。
特に、サンプリングバイアスがあるようなデータを収集してしまい、かつ、収集したデータ内の情報ではバイアスが確認しようがないようなケースの場合、誤った結論に至る可能性が非常に高いので、データ収集の前提には特に注意が必要です。
(例:幅広い世代からデータを収集したいのに、無意識に40代以上のデータが多く集まるような収集方法を取ってしまった。さらに、年齢の情報をデータとして取得していない など。こういった場合、データ収集後にサンプリングバイアスに気づける可能性は小さくなってしまう。)
これらを踏まえ、データの背景などについては人間側が事前に考慮していくことが必要です。
生成AIへの指示文を工夫することで落とし穴を避けられたとしても、足りていないデータを収集しなおすことが必要になるので、その分コストがかかってしまいます。
そのため、どんな意思決定をしたいか から逆算し、その意思決定をするためにはどんな分析が必要か、分析に必要な事象やデータは何か、そのデータを偏りなく集めるためにはどうしたらよいか、といった部分までを考えた状態で取得したデータであれば、生成AIに分析させても正しい示唆を導き出しやすく、出戻りも少なくなるということです。
また、指示文は恣意的なものにならないように注意が必要です。「~という結論にしたいから、そのための分析をして」のような指示をしてしまうと、その結論に至るように生成AIが分析をゆがめてしまう可能性もあるので、そのあたりも意識するようにしましょう。
生成AIを活用したデータ分析についてNTT東日本のデータサイエンティストがご相談にお応えします!お気軽にお問い合わせください。
ここまで見てきた通り、生成AIは分析結果を素早く整理し、わかりやすく示してくれる一方で、データの偏りや前提の妥当性まで自動で保証してくれるわけではありません。
そのため、生成AIを活用した分析では、「AIにうまく聞くこと」以上に、「人間側が前提を確認すること」が重要です。
以下では、実務で最低限確認しておきたいポイントをチェックリストとして整理します。
| □ |
何の意思決定に使う分析なのかが明確か 例:施策を継続するか、中止するか、対象を拡大するか |
| □ |
見たい指標が明確か 例:売上、継続率、満足度、離職率など |
| □ |
必要なデータがそろっているか 例:施策前後の比較に必要な期間データ、属性情報、比較対象データ |
| □ |
データの収集対象は適切か 例:特定の部署・勤務地・役職に偏っていないか、回答しやすい人だけが集まる設計になっていないか |
ここまでをDAGを書きながら整理できると、後からデータを収集しなおすことも少なくなるはずです。
| □ |
外れ値が含まれていないか 例:一部の極端に大きい値・小さい値によって、平均値や傾向が大きくゆがめられていないか。外れ値がある場合は実施したい意思決定・分析によって外れ値の取り扱い方法を決める |
| □ |
欠損値や入力ミスがないか 例:未回答が特定の部署に集中していないか、年齢や売上などに明らかに不自然な値が入っていないか |
| □ |
サンプルサイズは十分か 例:数十人しか回答していないのに、全社員の傾向として結論づけようとしていないか |
| □ |
回答者や対象者に偏りがないか 例:回答しやすい人、参加しやすい人だけが集まっていないか、時系列的な観点でも確認を実施する |
| □ |
比較対象の条件がそろっているか 例:部署、役職、勤務地、時期などの条件が大きく異なるものを、そのまま単純比較していないか |
| □ | いきなり結論を出させるのではなく、まずデータの特徴を確認させる |
| □ | 外れ値・欠損値・サンプリングの偏りがある可能性を考慮するよう指示する |
| □ | 収集されたデータの背後にある因果関係も考慮するよう指示する |
| □ | 追加で必要になりそうなデータを挙げさせる |
| □ | 恣意的な指示文になっていないか確認する |
例えば、次のように依頼すると、単なる要約だけでなく、前提の確認も含めた分析になりやすくなります。
このデータを分析してください。ただし、いきなり結論を出すのではなく、まず基本集計を行い、件数、分布、平均値、中央値などの特徴を整理し、分布などの可視化をしてください。
次に、外れ値、欠損値、サンプルサイズ不足、サンプリングバイアスの可能性を確認し、それらが分析結果に与えうる影響を説明してください。
その後、見られた傾向について示唆を出力してください。
ただし、示唆については相関と因果を区別して整理してください。必要に応じて、交絡因子や疑似相関の可能性も示してください。
最後に、この分析結果をより信頼できるものにするために、追加で必要なデータや確認事項を列挙してください。
| □ | その結論は、単なる相関ではないか |
| □ | 第三の要因(交絡因子)がありえないか |
| □ |
現場の実感や業務知識と大きくズレていないか 現場の実感とズレるかどうかの確認は非常に重要です。実感とズレた結論になる場合は、サンプリングバイアスや、交絡因子が背後に隠れている可能性もあるため、慎重にデータを見直すことが必要です。 |
生成AIは、分析の出発点を作るには非常に有効です。
しかし、最終的に意思決定につなげるためには、「AIが出した結論」ではなく、「その結論がどの前提のうえに成り立っているか」を人間が確認する必要があります。
生成AIを活用したデータ分析についてNTT東日本のデータサイエンティストがご相談にお応えします!お気軽にお問い合わせください。
生成AIは、データ分析のスピードを大きく高めてくれる強力なツールです。
一方で、外れ値、サンプルの偏り、相関と因果の取り違えといった、分析の前提に関わる問題まで自動で解決してくれるわけではありません。
だからこそ重要なのは、AIに分析を任せることではなく、人間が前提を点検しながらAIを使うことです。
生成AIは「考えることを代替する存在」ではなく、「考えるための材料を早く整理してくれる存在」と捉えるのがよいでしょう。
データ分析にAIを活用する機会が増えている今こそ、便利さだけでなく、前提を確認する姿勢もあわせて持つことが、より良い意思決定につながります。
生成AIを活用したデータ分析についてNTT東日本のデータサイエンティストがご相談にお応えします!お気軽にお問い合わせください。





相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

