
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


 |
こんにちは、白鳥です。 |
|---|
「AWSにつながらない」というシチュエーションや利用者からの申告に悩まされたことはありませんか?トラブルが起きていることはわかるのですが、どのように特定していったらよいでしょうか?AIやサポート窓口にすべてをゆだねる前に、効率的に解決していくためまず自身でトラブルの調査を行うことが大事になってきます。本コラムでは、トラブルの原因調査と情報収集の作業の考え方をまとめていきたいと思います。余談ですが、こうした原因となっている箇所の調査や特定のことを「切り分け作業」と呼んだりもしますが、本コラムではなるべくこの言葉を使わないように心がけて一般的な用語で解説したいと思います。
想定する読者
AWSのネットワーク設計や日々の運用に関するお悩みについて、NTT東日本のクラウドエンジニアがご相談を承っております。どうぞお気軽にお問い合わせください

「AWSにつながらない」という申告や状態というのはどういう状態でしょうか?この言葉の解像度を少し上げていきたいと思います。たとえば、このような状態が挙げられます。
ほかにも症状や状況はありますが、基本的には発生しているトラブルの情報解像度を上げていくことになります。
情報解像度が低いままAIやサポート窓口に問い合わせても、適切な回答を得ることは困難です。AIの場合はハルシネーションを起こし、サポート窓口の場合はこうした原因特定のためのやり取りが複数回続いた後、サポート範囲外とわかると別のサポート窓口に問い合わせを行い、最初から同じやり取りを繰り返すことになります。
それではどのように原因を特定していくとよいでしょうか?これには、ちょっとしたコツがあります。
AWSのネットワーク設計や日々の運用に関するお悩みについて、NTT東日本のクラウドエンジニアがご相談を承っております。どうぞお気軽にお問い合わせください
トラブル申告から原因の特定や現在の状態の情報収集作業を行っていきますが、私の場合は次のような順序で行っていきます。
まずは、影響範囲を確認します。ここでは「送信元」と「送信先」の確認を行います。
送信元:特定の端末か、知りうるすべての端末か、など
送信先:特定のアプリケーションやシステムや経路に限るのか、AWSの外部やほかのシステムにも影響があるかどうか
送信元が手元の端末だけとは限りません。端末からは通信できるがAWSのリソースから通信できないということもあるので、必ず両方向からの状態を確認します。
影響範囲が確認できたら、影響を受けている送信元と送信先までの経路を整理します。既存のネットワーク構成図や機器、プロトコルなどをできるだけ詳しく記載していきます。
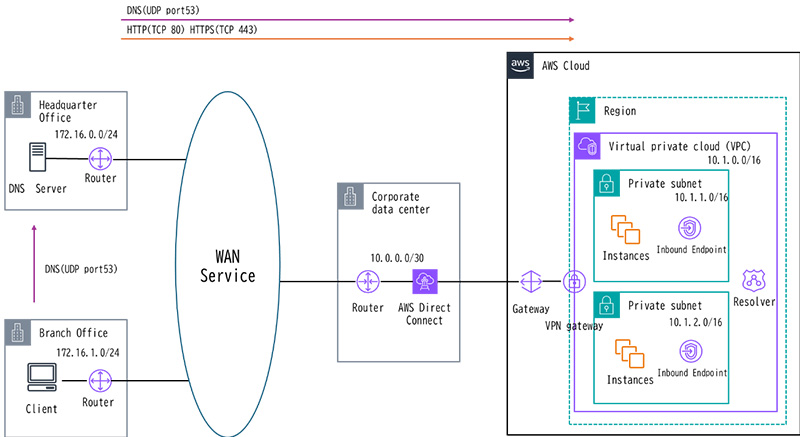
これらは手書きのメモやホワイトボードでも構いません。関連する機器やネットワークサービス、プロトコルと事象が理解できるものであればきれいさは問いません。
送信元と送信先の経路の整理ができたら、次はトラブルの原因となっている場所の特定を行います。
特定は次のように行います。好みが分かれるところではありますが、順序を決めておくことで、被疑範囲を狭めていくことができます。
(参考)OSI参照モデル

レイヤーの低いところからの確認になりますので、まずは物理層の確認からとなります。当たり前に見えるかもしれませんが、意外とシンプルな原因であったりすることもあるので、まずは下記のようなポイントを確認してみます。
また、AWSだけでなく、使用しているプロバイダーやネットワーク事業者において大規模障害が発生していないかを確認します。大規模障害の確認は各事業者の公式情報を確認します。
【各種サービス運営情報の例】
パケットキャプチャを使ったトラブルシューティングもありますが、ここではいったん割愛します。
次にネットワーク層・トランスポート層の確認をします。ネットワーク層の確認には一般的にはICMPを使います。Windowsの端末の場合はコマンドプロンプトで”ping”コマンドを使用します。問題がない場合はこのように応答があります。
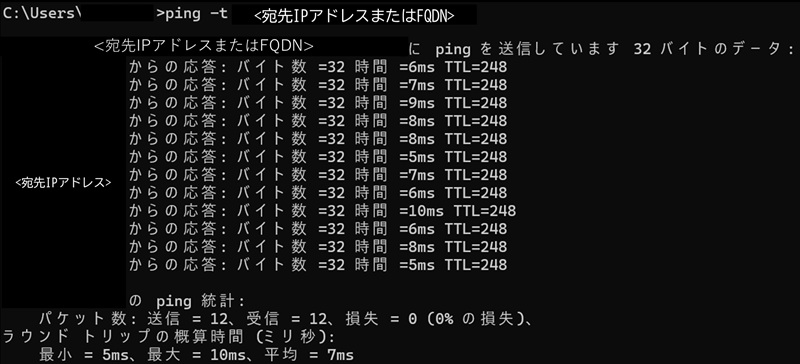
もし到達できない場合は「要求がタイムアウトしました」「宛先ホストに到達できません」などの回答が返ってきます。
その場合は、Trace Routeというツールを使ってどこまで到達しているかの調査を行います。
Windowsの場合は”tracert”というコマンドを使用します。本コマンドを使用することでどのIPアドレスまで到達しているかを確認することができます。

単純にICMPをファイヤーウォールで拒否している場合もあるので、ICMPの到達性だけではネットワーク層の到達性を担保することができない場合もあります。したがって、その場合はレイヤー4以上でも確認を行います。
レイヤー4での調査を行う場合はTelnetコマンドやncコマンドといったコマンドを使用します。
TelnetコマンドはWindows 11ではデフォルトでは無効化されていますので、「Windowsの機能の有効化または無効化」でTelnet Clientにチェックを入れます。

つながらない場合は、次のような表示になります。

接続可能な場合は入力を受け付ける画面に行きますので、そこまでいけばレイヤー4としては正常性を確認できています。
アプリケーション層や、セッション層の確認を行います。このレイヤーの確認は名前解決と具体的なプロトコルの接続確認となります。
名前解決の確認
DNSの名前解決でトラブルが出ていないかを確認します。Windowsの標準ツールではnslookupコマンドを使うことができます。こちらの回答が想定するIPアドレス範囲になっていることを確認します。

具体的なプロトコルでの確認
ここから先は、具体的なプロトコルでの確認を行います。
例えば、HTTP/HTTPSでの接続確認はWebブラウザの確認やコマンドプロンプトでcurlコマンドを使用します。
この確認ができればレイヤー7までの疎通性を確認できていますので、アプリケーション内部の確認を行っていく形になります。
ここまでの調査の結果、AWSのリソースやインフラストラクチャーに問題がありそうというところまでできたとします。
AWSのリソースやインフラストラクチャーの問題の調査について、EC2インスタンスや接続可能なリソースがあればここまでと同様にpingなどのツールを活用することもできますが、マネージドサービスなどで個別のリソースのOSレベルでの操作が難しいこともありますので、効率的な調査方法はAWSのサービスを使って行う必要があります。
AWSのインフラストラクチャーの確認は次の箇所を中心に行います。これは、オンプレミス側でいう物理層の確認にあたります
AWS上のネットワークの確認を行う場合はどのようにすればよいでしょうか?
送信先のEC2インスタンスにログインできる場合は、これまでご紹介したPingやTrace Routeといった手法は使えますが、マネージドサービスに対してはOSレベルのログインがAWSユーザーには許可されていないため、別の手法をとる必要があります。この際に使える方法をご紹介します。
ネットワークレベルのトラブルの確認の場合は、VPC Reachability Analyzerを使うことをお勧めします。
インスタンス間だけではなく、次のようなリソース間の到達可能性を確認することができます。
到達可能性の確認には、ネットワークパスを作成し、検査を行います。
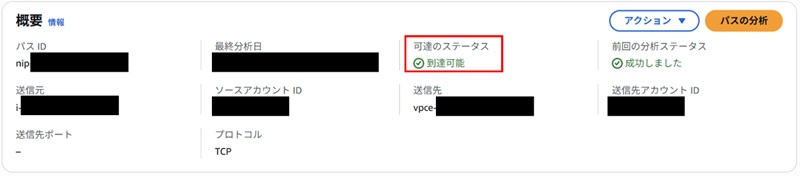
VPC内部や、VPCエンドポイント経由のマネージドサービスの場合、ENIへの疎通確認を行います。正しい結果の場合、このように「到達可能」と表示されます。
しかし、途中経路で到達できないリソースがある場合は、「到達不可能」と表示され、この原因を探ることができるようになっています。
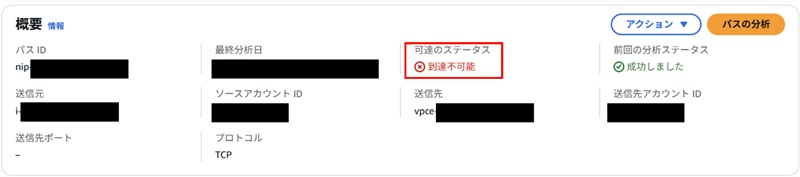
セキュリティグループの設定にミスがある場合の例
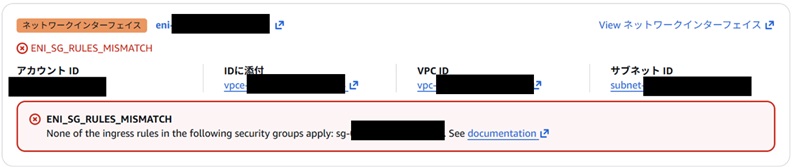
ネットワーク起因のトラブル原因箇所が特定できたら、次に下記の項目を行います。
原因と思われる箇所のみでも構いませんが、いったん取得できる情報はすべて取得することをお勧めします。
これらの情報を取得したら、わかる範囲で意図した設定どおりになっているかを確認します。
ここまで確認できて、もし解決できない場合であればアプリケーションのレイヤーの問題や、不具合の可能性がありますので、その情報をもとにAWSサポートやほかのサポート窓口への問い合わせを行うことが必要です。サポート窓口への問い合わせ時には、ここまでの情報のほかに、下記のような情報を追加で伝えておくとスムーズに進みます。
ここまでの原因の特定と調査に結構な時間を使ったと思います。こうしたオンプレミス環境とのネットワークレベルにおいてもネットワーク監視を実装することが考えられるかもしれません。その場合は、Network Synthetic Monitorを利用することもできます。対象の送信元と送信先とプロトコルを設定することでネットワークレベルの監視が可能となります。
詳しくは下記のドキュメントをご覧ください。
Using Network Synthetic Monitor
AWSのネットワーク設計や日々の運用に関するお悩みについて、NTT東日本のクラウドエンジニアがご相談を承っております。どうぞお気軽にお問い合わせください
今回は、AWSに関連するネットワークトラブルの原因の特定と調査を中心に行っていきました。もっとトラブルシューティングに有用なツールも多数ありますが、標準ツールの中でできることでも原因の特定と起きている事象の解像度を上げてからサポートに連絡することで、迅速な問題解決を行うことができるようになります。この調査と情報収集自体をAIに任せることもできるかもしれませんが、その場合でも具体的な情報を取得することでより精微な情報を知ることができますので、各レイヤーと管理しているリソースの情報は事前に取得しておくことをお勧めします。
NTT 東日本では、AWSの構築保守だけではなく、ネットワーク設計なども含めたエンドツーエンドでのソリューション提供を行っております。
経験値豊かなメンバーがご担当させていただきますので、是非お気軽にお問い合わせください!





相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

