
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


こんにちは!NTT東日本 セキュリティエンジニアのイタガキです。
本コラムでは、Zscaler Internet Access(ZIA)のログをMicrosoft Sentinelに取り込む際に直面した課題と、その解決策について技術的な観点から詳しく解説します。
実際の対応プロセスや検証結果を交え、現場で役立つノウハウをお届けします。
以下が過去のコラムになっております。まだご覧になっていない方は、是非ご覧ください。
SIEMを導入したいが、何からはじめたらよいかわからない、最適なソリューションがわからないなどNTT東日本のセキュリティエンジニアが無料でご相談をおうけいたします。ぜひ、お気軽にお問い合わせください。

ZIAログをMicrosoft Sentinelで分析する際、ログ転送の仕組みや欠損のリスクを理解することは重要です。過去のコラムで軽く触れましたが、本章ではその背景と実際に発生した事象をより具体的に説明します。
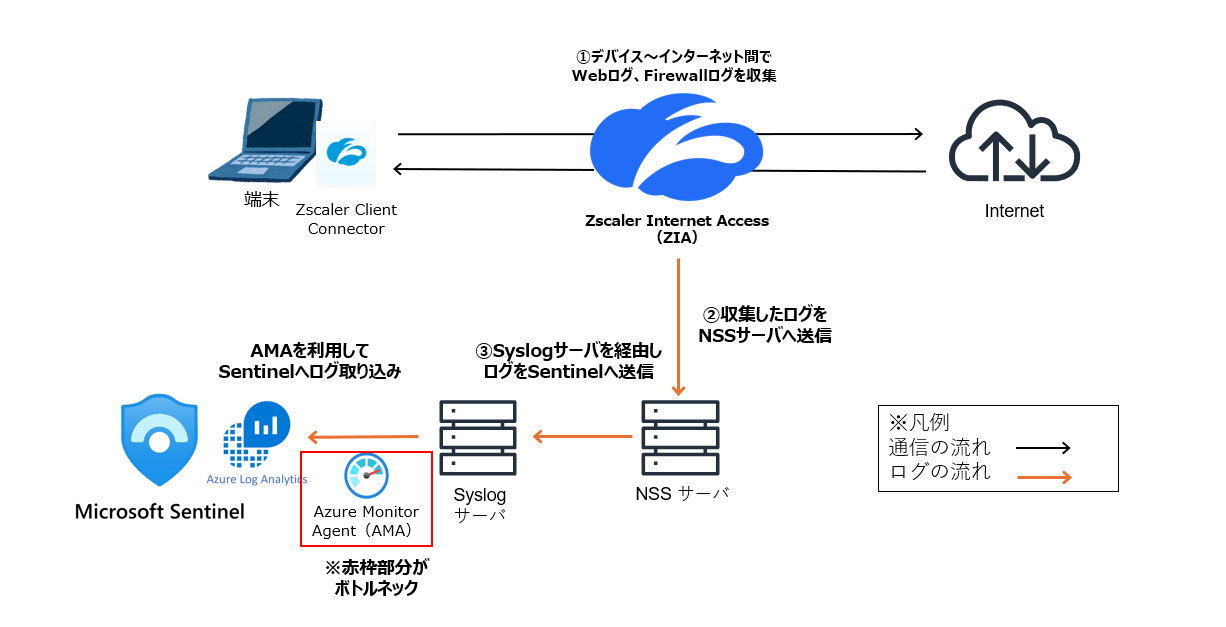
NTT東日本では、ZIAを活用し、WebログおよびFirewallログをLog Analyticsワークスペースに取り込み、Sentinelで可視化・分析を行っています。この環境を構築するにあたり、一般的な構成をベースに以下の図のようなログ転送の仕組みを検討しました。
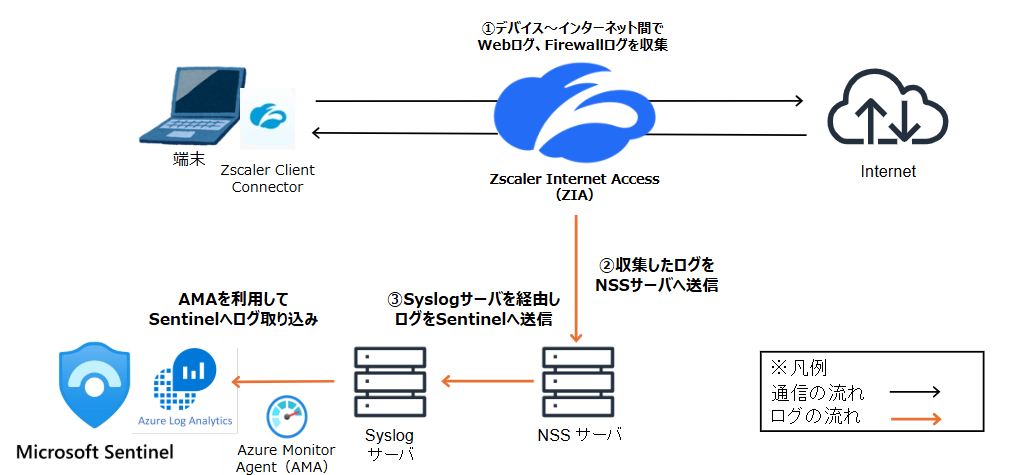
しかし検証の結果、一部のログがSentinelに反映されない事象が発生しました。このままでは監視において重要なログを見落とすリスクがあり、原因究明と改善が急務となりました。
SIEMを導入したいが、何からはじめたらよいかわからない、最適なソリューションがわからないなどNTT東日本のセキュリティエンジニアが無料でご相談をおうけいたします。ぜひ、お気軽にお問い合わせください。
第1章では、Sentinelへのログ転送フローの構築とログ欠損の発生について説明しました。本章では原因調査と改善手法について、順を追って解説します。
大部分のログが正常に転送できていることから、転送経路そのものには問題がないと考えられました。したがって、転送の過程で何らかの問題が発生し、一部ログが欠損した状態でSentinelに送信されている可能性があると推察しました。ここから、より詳細な原因追及を開始しました。
まず、NSSサーバーに問題がないかを確認しました。
NSS(Nanolog Streaming Service)サーバーは、ZIAで収集されたログを外部のSIEMやログ管理システムへリアルタイムに転送するための仮想アプライアンスです。ZIAはクラウドサービスとして提供されるため、企業の分析基盤にログを取り込むには、この仕組みが必要となります。検証のため、既存のSyslogサーバーとは別に新しいSyslogサーバーを用意し、WebログとFirewallログをすべて保存したうえで、ZIAポータルのログと突合しました。その結果、ログ欠損は一切発生せず、正常に保存されていることが確認できました。このことから、Sentinelへのログ連携に使用していたSyslogサーバーやログ送信に必要なアプリケーションに問題があると判断し、さらに調査を進めました。最初にリソース状況を確認したところ、メモリ使用量には問題がなかったものの、CPU使用率が特定の値で高止まりしている状態であることが判明しました。
本来CPU使用率は負荷に応じて波形を描くはずであるため、なんらかの処理性能に問題があると考えられます。
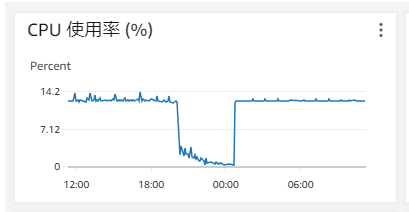
さらに、サーバーにログインし、以下のコマンドを使用してrsyslogのプロセス(rsyslogd)とZIAのログ送信に必要なエージェントであるAzure Monitor Agent(以降AMA)のプロセス(mdsd)のCPU使用率を調査しました。
pidstat -u -t | grep mdsd
pidstat -u -t | grep rsyslogd
調査の結果、mdsdプロセスはマルチスレッドで動作しており、特定のスレッドにCPU負荷が集中していることが確認できました。この状況から、CPUの性能またはmdsdプロセス自体に何らかの問題が存在している可能性が高いと考えました。
そこで、まずCPUリソースの増強(スケールアップ)を実施したところ、グラフの波形に見られた直線的な高止まりが改善され、下図のような正常な波形が得られました。この状態でログを再送信した結果、以前より多くのログが送信されていることを確認できました。
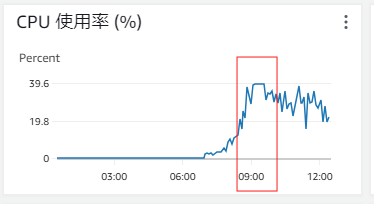
検証の結果、CPU性能を強化することで一定の改善が確認できました。次にどのようにスケールアップを実施したのか、その手順を説明します。
リソース増強による機器性能の向上は「スケールアップ」と呼ばれます。本環境はAWS上に構築されているため、インスタンスタイプの変更によるスケールアップ手順について解説します。
AWSコンソールで、アクション → インスタンスの設定 → インスタンスタイプの変更を選択します。新しいインスタンスタイプを指定し、変更を適用します。
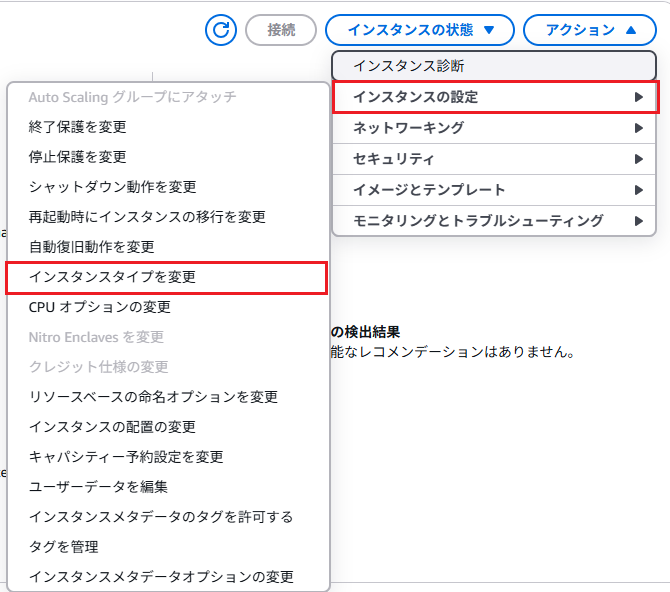
次の画面で以下のようにインスタンスタイプを変更できるので適切なものに変更してください。
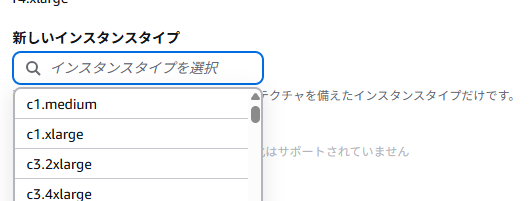
今回はCPUのスペック不足がボトルネックとなっていたので、コンピューティング最適化というインスタンスから選択しました。
しかし、継続的に監視したところ一部の時間帯でCPU使用率の波形が上限に張り付く状態が確認されました。これを受けて、さらにCPU性能をスケールアップしましたが改善は見られず、これ以上のリソース増強では効果がないことが分かりました。そのため、別のアプローチを検討する必要がありました。
2-1章での対策により、事象は一定程度改善されましたが、ログ欠損を完全に解消することはできませんでした。CPU性能をさらに引き上げても改善が見られなかったことから、サーバーにインストールされているAMAプロセス側に問題がある可能性を仮定し、再度調査を行いました。
AMAはZIAのログ送信に必要なエージェントですが、CPUスペックを引き上げても特定スレッドにCPU使用率が偏っていたため、単純なリソース不足ではないと考えました。
まず、以下のMicrosoft公式ドキュメントを参考に、AMAのパフォーマンスに関する情報を確認しました。
Azure Monitor エージェントへの転送のパフォーマンス - Azure Monitor | Microsoft Learn
このナレッジによると、AMAの処理性能はスペックに依存するものの、トラフィック量の目安として10,000 EPS(Events Per Second)を設定する必要があると記載されています。この情報を基に、社内のトラフィック量の推移を分析しました。その結果、始業時間である午前9時前後にトラフィックがピークを迎え、そのタイミングで10,000 EPSを大幅に超えるログが送信されていることが判明しました。これにより、ログ欠損のもう一つの原因がAMAの処理能力の限界にあることを特定できました。
AMAの処理能力が限られているのであれば、処理能力内に収める必要があります。次にどのように改善をしたかを説明します。
ZIAのすべてのログを送信することは必須要件であるため、ログ量を適切に分散させる必要があります。ログ分散の方法はいくつかありますが、私たちは以下のように構成を変更しました。
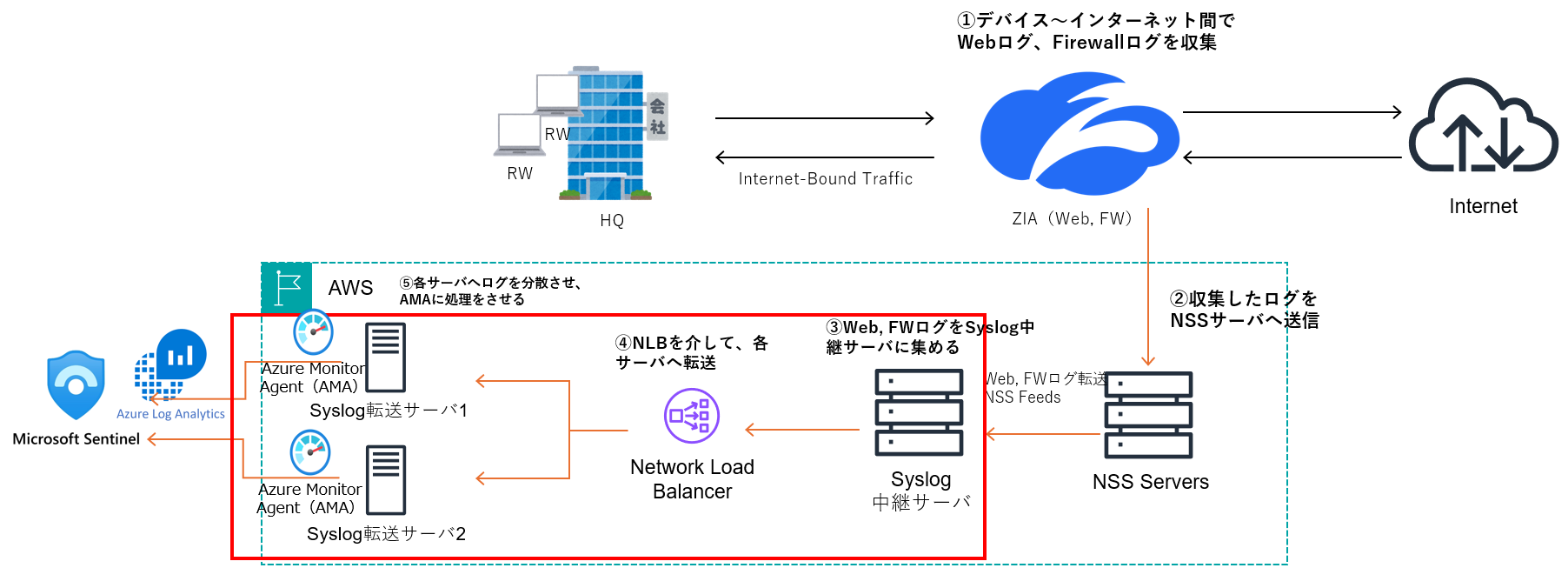
図中の①と②は従来の構成と同じです。③は通常のSyslogサーバーで、AMAはインストールされていません。このサーバーにZIAのログをすべて収集し、その後④のNLB(Network Load Balancer)宛てに送信します。NLBからは⑤のAMAを搭載した複数のサーバーにログを分散する構成としました。理論上、この構成により複数のサーバー(AMA)にログが分散されるはずです。
このように複数のサーバーを用いて処理能力を向上させる方法を「スケールアウト」と呼びます。
しかし、構成変更後に実際に動作を確認したところ、片側のSyslog転送サーバーにしかログが送信されず、ログ分散が正常に機能しないという課題に直面しました。
2-2章の対策を行いましたが、ログが片側のサーバーにしか送信されないという問題が発生しました(図中の緑矢印部分)。
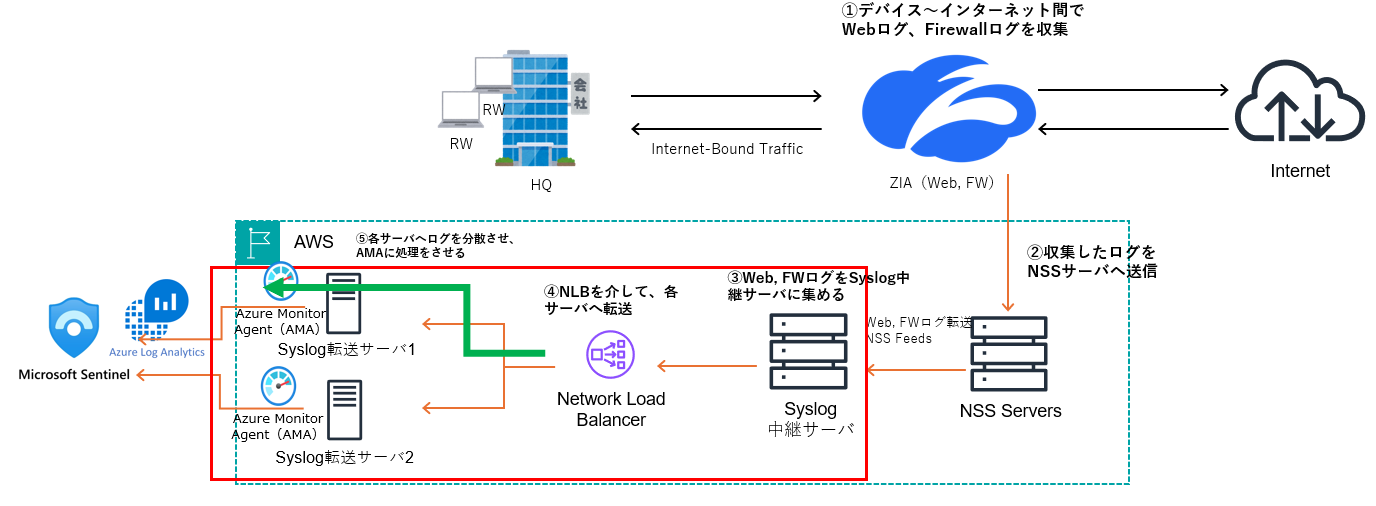
機器構成自体には問題がないことを確認できたため、次にNetwork Load Balancer(以下、NLB)の仕様、rsyslogの設定およびログ送信方式の仕様を詳細に確認することにしました。
まず、NLBの仕様を確認しました。公式情報によると、NLBはOSI参照モデルの第4層で動作し、TCP・UDP・TLS・TCP_UDPのプロトコルとポート番号を利用します。ログはTCPまたはUDPで送信されるため、それぞれのルーティング挙動を調べました。
TCP通信は3ウェイハンドシェイク後、同一コネクションを維持するため、この挙動が片側サーバーへの集中を引き起こしている可能性があると考えました。
参考:Network Load Balancer とは? - エラスティックロードバランシング
次に、中継Syslogサーバーでrsyslogがどのようにログを送信しているかを確認しました。rsyslogの設定は/etc/rsyslog.confに記載されており、以下の内容になっていました。
$ModLoad imtcp
$InputTCPServerRun 514
このことから、rsyslogによるログ送信はTCPで行っており、NLBによりTCP接続後は同一のターゲットにルーティングするという仕様により片側のサーバーにログが寄っていたことが分かりました。
ロードバランスされない原因が特定できたので、次に必要な設定について説明します。
TCP接続が同一ターゲットに維持されるのであれば、意図的にセッションを切断・再確立させれば分散を促せます。rsyslog の公式ドキュメント(omfwd モジュール)には、送信セッションの再確立間隔を制御する RebindIntervalパラメータが用意されています。
ロードバランサ補助用途として推奨されている挙動で、今回の要件に合致します。
参考:omfwd: syslog Forwarding Output Module - rsyslog 8.2510.0 documentation
したがって、/etc/rsyslog.confに以下の設定を追加しました。
xxx.info action(type="omfwd" target="nlbのドメイン" port="514" protocol="tcp" RebindInterval="5000")
RebindIntervalの値は環境により異なりますが、NTT東日本では5000を採用しました。結果として、複数のSyslogサーバーへのログ分散が実現し、Sentinelへの安定したログ送信が可能になりました。
SIEMを導入したいが、何からはじめたらよいかわからない、最適なソリューションがわからないなどNTT東日本のセキュリティエンジニアが無料でご相談をおうけいたします。ぜひ、お気軽にお問い合わせください。
今回の検証を通じて、ログ欠損の原因は単なるリソース不足ではなく、複数の要因が複合的に影響していることが明らかとなりました。特に、AMA(Azure Monitor Agent)の処理性能には10,000 EPSという制約があり、CPUリソースの強化によって一部改善は見られたものの、根本的な解決には至りませんでした。また、NLB(Network Load Balancer)による分散構成では、トラフィックの集中による片側サーバーへの負荷偏在が発生するケースが確認されました。さらに、NLBおよびrsyslogにおけるTCPの仕様により、ロードバランスが十分に機能しない場合がありました。
これらの結果から得られた教訓は、以下の通りです。
本コラムでご紹介した知見や改善策が、皆さまのシステム設計や運用の一助となれば幸いです。今後も現場で得られた実践的なノウハウを発信してまいりますので、ぜひご活用ください。
SIEMを導入したいが、何からはじめたらよいかわからない、最適なソリューションがわからないなどNTT東日本のセキュリティエンジニアが無料でご相談をおうけいたします。ぜひ、お気軽にお問い合わせください。





相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

