
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


こんにちは、豊岡です。
本記事ではAWS OSS(オープンソースソフトウェア)とLambdaを用いたスピードAPI開発術についてご紹介します。
機能開発の際にすでに似たような要件でAWS OSSで提供されている場合に遭遇することもあると思います。一方で、READMEにインストールやコンパイル方法が提示されており、Linux上でのコマンド提供になっていることもあり、既存ツールへのマージは難しい場面があると思います。
今回はそのようなケースにおいて、AWS OSSが実施する機能をAPI形式で提供することをゴールにします。また運用を考慮して、サーバーレス構成のLambdaのFunction URLでのサンプルをご提示します。

AWSのサービスリソースを一覧で詳細までリソース作成や各種パラメータレベルで取得したいユースケースを考えます。各種リソースの詳細情報を取得しようとする場合、AWSサービスをまたぐ場合は、各種サービスでdescribe関連のAPIでそれなりのコード量が必要になります。
サービスをまたいでリソースを出力するresourcegroupstaggingapiは、ARNやタグ情報レベルにとどまってしまいます。
#!/bin/bash
service='ec2:instance'
aws resourcegroupstaggingapi get-resources --resource-type-filters ${service}
>> {
>> "ResourceARN": "arn:aws:ec2:ap-northeast-1:ACCOUNT_ID:instance/INSTANCE_ID",
>> "Tags": [
>> {
>> "Key": "Name",
>> "Value": "Instance"
>> }
>> ]
>> :
>> }
実際に各サービスの詳細(インスタンスIDやその関連情報)まで分かるSDK for Pythonは下記のようになります。各サービスや新しいサービスが増えるたびにコードをメンテンスする必要するがあります。
import boto3
ec2_client = boto3.client('ec2')
rds_client = boto3.client('rds')
s3_client = boto3.client('s3')
:
ec2_client.describe_instances()
rds_client.describe_db_clusters()
s3_client.list_buckets()
:
:
これらの問題点を解決してくれるのが、各種サービスのdescribeをラッパーしているAWS OSSのawsetsになります。
https://github.com/trek10inc/awsets上述したresourcegroupstaggingapiとほぼ同じスクリプトですが、返却される情報は裏でdescrive系のAPIが走っているため、豊富な情報量になります。また引数を変えるだけで、AWSサービスの多くに対応しています。
※更新が2022年2月に止まってしまっているので、OSSなのでBedRock更新周りで貢献したいですね、、!
#!/bin/bash
service='ec2/instance'
awsets list --include ${service}
>> [{
>> "Account": "XXXXXXXXXXXX",
>> "Region": "ap-northeast-1",
>> "Id": "i-xxxxxxxxxxxxxxx",
>> "Version": "",
>> "Type": "ec2/instance",
>> "Name": "i-xxxxxxxxxxxxxxx",
>> "Attributes": {
>> "AmiLaunchIndex": 0,
>> "Architecture": "x86_64",
>> "BlockDeviceMappings": [
>> {
>> "DeviceName": "/dev/xvda",
>> "Ebs": {
>> "AttachTime": "202X-XX-XXTXX:XX:XXZ",
>> "DeleteOnTermination": true,
>> "Status": "attached",
>> "VolumeId": "vol-xxxxxxxxxxxxxxx"
>> }
>> }
>> ],
>> :
>> }]
このOSSもREAEDMEには、インストールやコンパイルをしたLinuxコマンド提供になっています。
Installation
From source
git clone https://github.com/trek10inc/awsets.git
cd awsets/cmd/awsets
go build && go install
Homebrew
brew tap trek10inc/tap
brew install awsets
From binaries
Binaries are available here
この内容を機能開発が必要なツールに盛り込んでいくために、API形式で提供を考えます。今回はサーバーレス構成で実現したい条件で、AWS Lambdaのエンドポイントでデプロイをして下記の構成で各サービスの詳細が取得できるようにします。
curl -X POST ${url} -H "Content-Type: application/json" -d '{"prefix": “Service Name"}'
AWS LambdaでLinuxコマンド、ランタイムBashを実施するためには2つの方法があります。まずはじめにawsetsではなくて、Lambda上でAWS CLIの実施を確かめます。
Tutorial: Building a custom runtime
下記2つのスクリプト(`function.sh, bootstrap`)を用意してzipファイル化して、Lambda関数のランタイムをAmazon Linux2023 (provided.al2023)に指定します。
#!/bin/bash
function handler () {
EVENT_DATA=$1
echo `aws --version` 1>&2
RESPONSE="'${EVENT_DATA}'"
echo $RESPONSE
}
ここで、1>&2は標準出力をCloudWatch Logsに出力します。
#!/bin/sh
set -euo pipefail
# Initialization - load function handler
source $LAMBDA_TASK_ROOT/"$(echo $_HANDLER | cut -d. -f1).sh"
# Processing
while true
do
HEADERS="$(mktemp)"
# Get an event. The HTTP request will block until one is received
EVENT_DATA=$(curl -sS -LD "$HEADERS" "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/next")
# Extract request ID by scraping response headers received above
REQUEST_ID=$(grep -Fi Lambda-Runtime-Aws-Request-Id "$HEADERS" | tr -d '[:space:]' | cut -d: -f2)
# Run the handler function from the script
RESPONSE=$($(echo "$_HANDLER" | cut -d. -f2) "$EVENT_DATA")
# Send the response
curl "http://${AWS_LAMBDA_RUNTIME_API}/2018-06-01/runtime/invocation/$REQUEST_ID/response" -d "$RESPONSE"
done
aws lambda create-function \
--function-name ${function_name} \
--runtime provided.al2023 \
--handler function.handler \
--role arn:aws:iam::${AWS_ACCOUNT_ID}:role/${lambda_role} \
--zip-file fileb://function.zip
できあがったLambdaをデフォルトのテストで実施すると、下記のレスポンスが確認できます。ここで、注目すべき結果は2つあります。
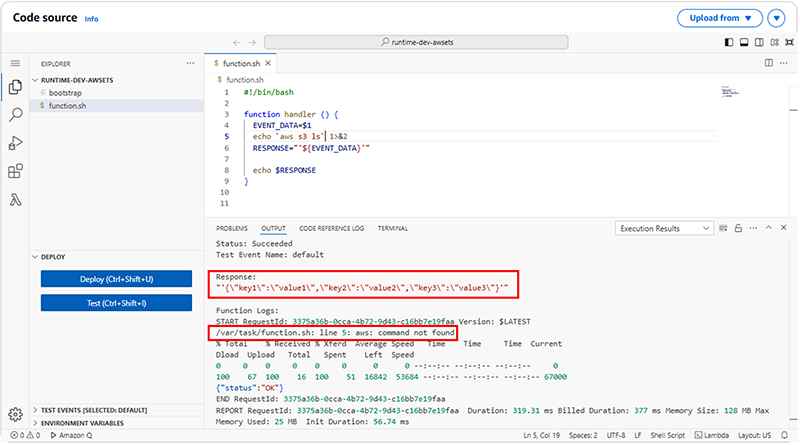
1点目は、レスポンスが文字列になっているので、APIで期待されるJSON形式で返却するようにするには`jq`コマンドで整形する必要があります。
"'{\"key1\":\"value1\",\"key2\":\"value2\",\"key3\":\"value3\"}'”
2点目は、`provided.al2023`はデフォルトでは`aws cli`がインストールされていないことが確認できます。そのため、コマンドをLambdaレイヤーとして登録する必要があります。この時、Lambdaレイヤーに直接アップロードするzipファイルは容量制限があり、`aws cli`もそれに該当したためにS3経由で登録します。
For files larger than 10 MB, consider uploading using Amazon S3.
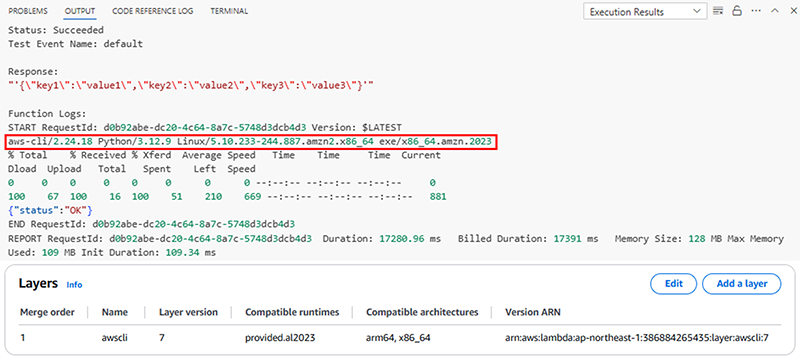
AWS Lambdaレイヤーに登録する方法は次の通りです。Lambda上を下記のコマンドを実施すると、下記の結果が返ってきます。
Lambda は、関数の実行環境を設定する際に、レイヤーの内容を /opt ディレクトリに抽出します。
$ echo ${PATH}
> /usr/local/bin:/usr/bin/:/bin:/opt/bin
/optにレイヤーが追加されることと、/opt/binはPATHが通っていることから、zipファイルの中身は`./bin/`にコマンドが来ることを意識して固めます。
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
$ unzip awscliv2.zip
$ ./aws/install -i 任意のフォルダ
$ ./aws/bin/v2/2.24.18/bin/aws
> usage: aws [options] <command> <subcommand> [<subcommand> ...] [parameters]
$ cd ./aws/bin/v2/2.24.18
$ zip -r awscli.zip bin dist
$ aws s3 cp awscli.zip s3://toyooka-s3
$ aws lambda publish-layer-version --layer-name awscli \
--content S3Bucket=${Bucket},S3Key=awscli.zip \
--compatible-runtimes "provided.al2023" \
--compatible-architectures "arm64" "x86_64"
レイヤーを追加したことで、上手くAWS CLIが動いていることが確認できました。
APIとして機能を考えた際に必須な`jq`コマンドも同じくレイヤーとして登録していく必要があります。そのため、Custom Runtimeは、開発フェーズでは新しいコマンドが追加されるたびにコマンドをレイヤーに登録する必要があるので、少しトライ&エラーの効率は悪いかなと個人的に思いました。
※bootstrapにインストールを埋め込んでレイヤーに登録するアプローチ場合だと、後述するContainer Runtimeと同じ考え方で少し楽になるかもしれません。
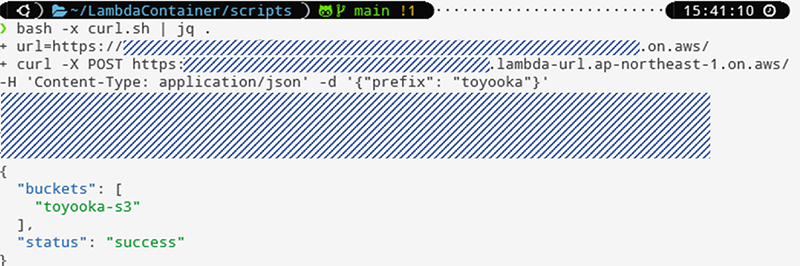
最終的にs3のprefixを指定した`aws s3 ls`でリストを返却するAPIを想定すると、下記のスクリプトができ、Function URLで発行させます。RuntimeがBashのLambdaで、API形式で発行させることができました(awkやjqを利用したシェルで組み合わせました)。
#!/bin/bash
function handler () {
EVENT=$1
echo "${EVENT}" >&2
if echo "$EVENT" | jq -e 'has("body")' > /dev/null; then
BODY=$(echo "$EVENT" | jq -r '.body')
else
BODY="$EVENT"
fi
BUCKET_PREFIX=$(echo ${BODY} | jq -r '.prefix')
BUCKETS=$(aws s3 ls | grep ${BUCKET_PREFIX} | awk '{print $3}' | jq -R . | jq -s .)
RESPONSE=$(jq -n \
--arg status "success" \
--argjson buckets "$BUCKETS" \
'{"status": $status, "buckets": $buckets}'
)
echo ${RESPONSE} | cat
}
AWS Lambda base images for custom runtimes
Container RuntimeではCustom Runtimeと比べて、DockerfileからDockerImageをビルドしてECRにプッシュして登録する工程を含むため、少し前準備が増えます。ですが、コマンドや環境情報が増えてもDockerfileに記述を足していく方針なので、個人的にはContainer Runtimeのアプローチの方が楽だなと感じました。
※function.shとbootstapは同じになります。
FROM public.ecr.aws/lambda/provided:al2
RUN yum update -y
RUN yum install -y unzip wget jq && \
wget "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -O "awscliv2.zip" && \
unzip awscliv2.zip && \
./aws/install
COPY bootstrap ${LAMBDA_RUNTIME_DIR}
COPY function.sh ${LAMBDA_TASK_ROOT}
RUN chmod +x /var/runtime/bootstrap \
&& chmod +x /var/task/*.sh
CMD ["function.handler"]
ECRへの登録とLambda化は次のスクリプトで実施しました。
#!/bin/bash
image=
ecr_uri=
# ECR login
aws ecr get-login-password --region ${AWS_REGION} | docker login --username AWS --password-stdin ${ecr_uri}
docker image tag ${image}:latest ${ecr_uri}:latest
docker image push ${ecr_uri}:latest
echo "Normal END"
exit
#!/bin/bash
export AWS_ACCOUNT_ID=`aws sts get-caller-identity --query Account --output text`
image=
ecr_uri=
aws lambda create-function \
--function-name ${sysname}-${env}-${purpose} \
--package-type Image \
--code ImageUri=${ecr_uri} \
--role arn:aws:iam::${AWS_ACCOUNT_ID}:role/lambda_basic_execution
# or update
aws lambda update-function-code \
--function-name ${sysname}-${env}-${purpose} \
--image-uri ${ecr_uri}
echo "Normal END"
exit
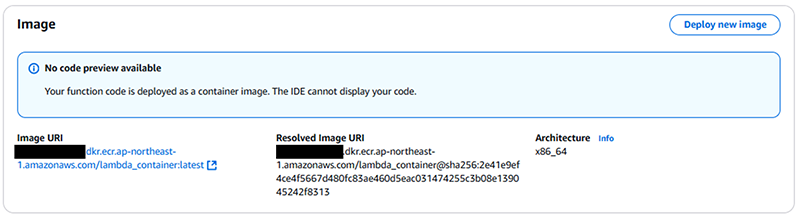
※コーディング画面が残らないところはメリット・デメリットあるかもしれません、、!
上述した内容からawsetsを用いたLambdaでのAPI構築は、Container Runtimeでの実施を選択して、実装してみます。
FROM public.ecr.aws/lambda/provided:al2
RUN yum update -y
RUN yum install -y unzip wget jq tar gzip
RUN wget "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -O "awscliv2.zip" && \
unzip awscliv2.zip && \
./aws/install
RUN wget https://github.com/trek10inc/awsets/releases/download/v1.1.1/awsets_1.1.1_linux_x86_64.tar.gz -P /usr/local/src --no-check-certificate && \
tar xvzf /usr/local/src/awsets_1.1.1_linux_x86_64.tar.gz -C /usr/bin
COPY bootstrap ${LAMBDA_RUNTIME_DIR}
COPY function.sh ${LAMBDA_TASK_ROOT}
RUN chmod +x /var/runtime/bootstrap \
&& chmod +x /var/task/*.sh
CMD ["function.handler"]
#!/bin/bash
CMD="awsets"
export HOME=/tmp
export XDG_CACHE_HOME=/tmp/.cache
CACHE_DIR="${XDG_CACHE_HOME}/awsets"
mkdir -p ${CACHE_DIR}
function handler () {
EVENT=$1
echo "${EVENT}" >&2
if echo "$EVENT" | jq -e 'has("body")' > /dev/null; then
BODY=$(echo "$EVENT" | jq -r '.body')
else
BODY="$EVENT"
fi
SERVICE=$(echo ${BODY} | jq -r '.prefix')
RESOURCES=$(${CMD} list --include ${SERVICE})
RESPONSE=$(jq -n \
--arg status "success" \
--argjson resources "$RESOURCES" \
'{"status": $status, "resources": $resources}'
)
echo ${RESPONSE} | cat
}
先ほどとほぼ同じスクリプとですが、各サービスの情報粒度が細かい内容を取得できております。
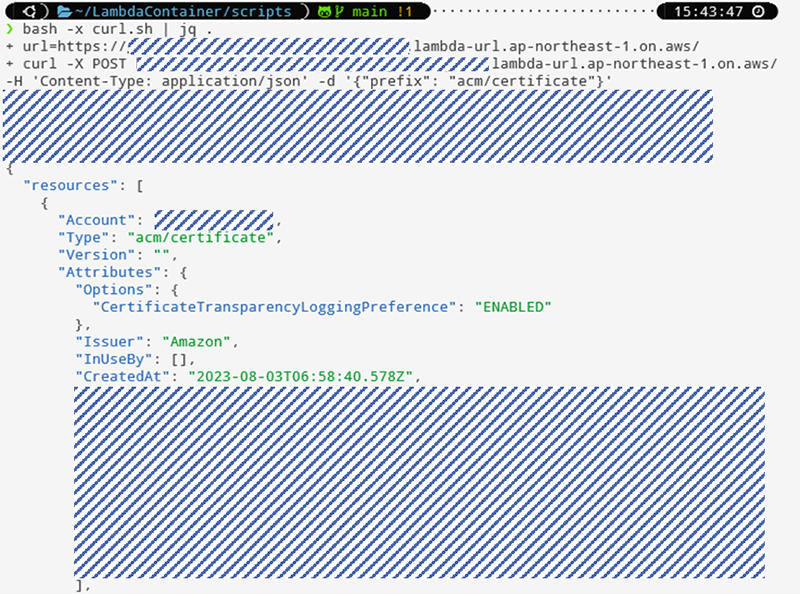
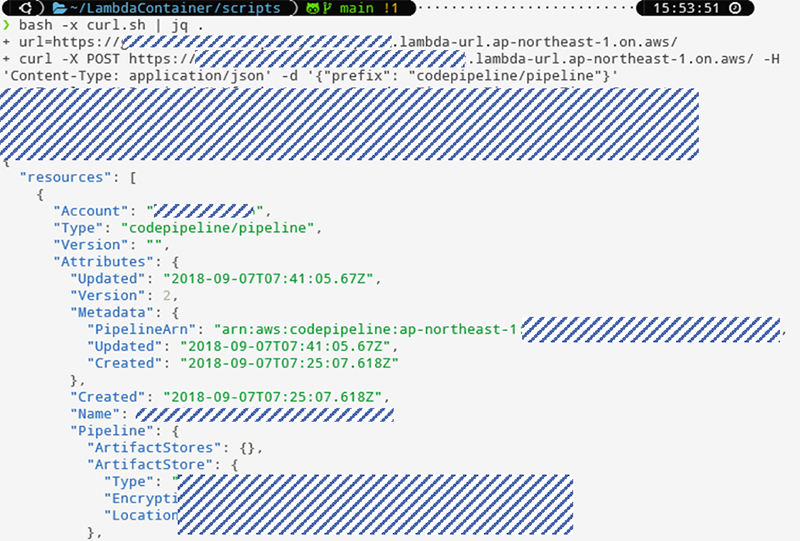
本記事では、AWS CLI・AWS OSSであるawsetsをLambdaを通じてAPI化し、AWSリソース情報の取得を効率化する方法を紹介しました。この形式はLinuxコマンド提供されているOSSに適用ができるので、少ない記述スクリプトで情報量が多いAPIをすぐに作成することができるので、ぜひスピード重視やOSSの活用を考えたい際はご検討ください。
また、awsets自体が2022年で更新が止まっているため、必要に応じてOSSへの貢献も視野に入れていきたいですね。最後まで、見ていただきありがとうございました!






相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

