
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


こんにちは、豊岡です。
本記事では自身が参加したre:Invent 2024のWorkShopセッション”Using Observability for effective incident response”で取り扱われた周辺スキルを丁寧にお伝えしたいと思います。本記事を読んでいただくことで、最新のAWS Native Serviceを用いた運用技術周り(モダンなダッシュボード・自動化など)を把握いただくことを目指しております。

※注意※
本WorkShop資料は公開されているものの、初期構築が済んでいるAWSアカウント配布はその場限りでした。そのため本記事では再現性担保のため、Observabilityとして一般提供されているワークショップ”One Observability Workshop”を中心に紹介して、ところどころでWorkShopとして紹介されたトピックを紹介いたします。
NTT東日本では、AWSなどクラウドに関するお役立ち情報をメールマガジンにて発信していますので、ぜひこちらからご登録ください。

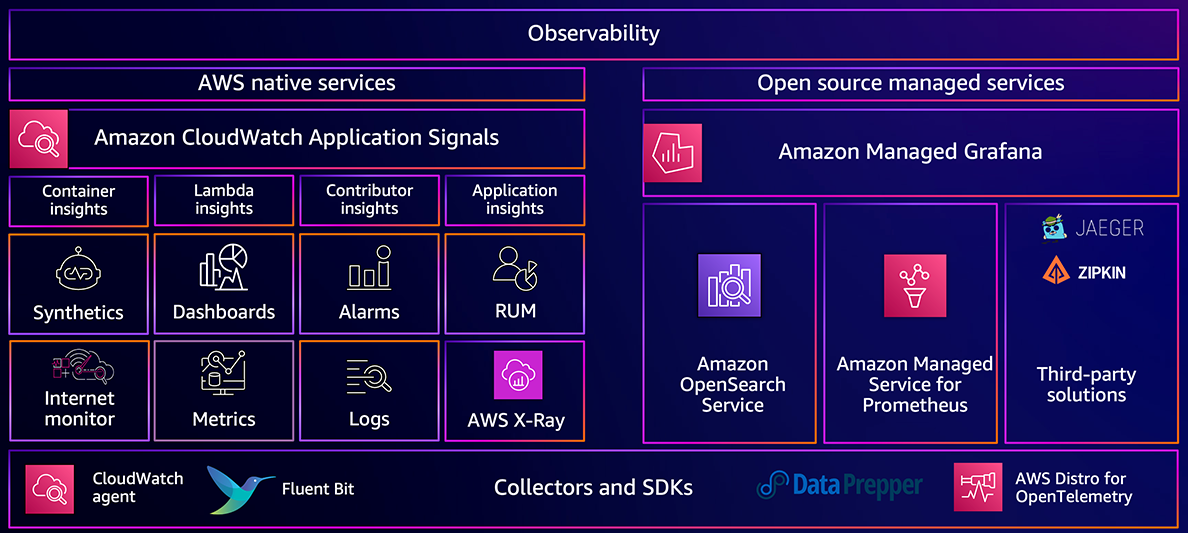
WorkShopに入る前に、現在のObservabilityの重要性を説く説明がありました。AWSのObservabilityソリューションは、CloudWatchをはじめとして下記のように分類されます。
またAWSを運用するには欠かせない、AWS System Managerの機能を網羅するスライドも紹介されました。
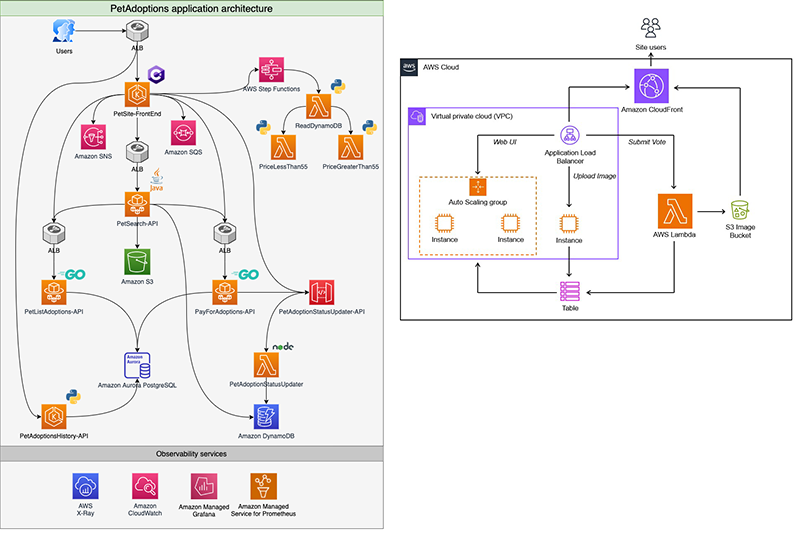
今回のワークショップでは、ペットのお気に入りの写真をアップロードするWebサイトのDevOpsチーム一員として参画します。今回題材にあるアーキテクチャは左図の構成になっております。現地でのワークショップは右図の構成になっており、今回のワークショップの方が包含しているリソースであることが分かります。
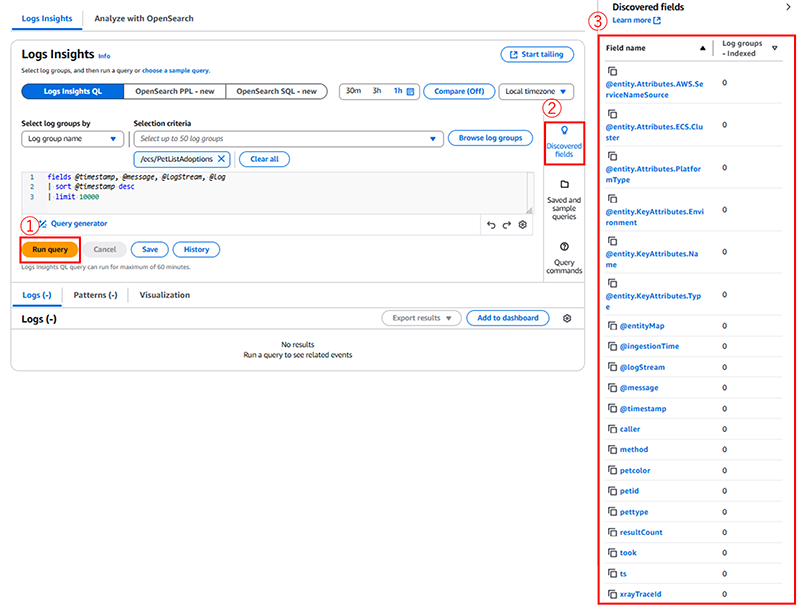
まず初めにログ編について、紹介します。
CloudWatchに対して、複雑なクエリも利用できる機能です。Athenaと同様にスキャンに対して過剰な金額がかかるため、ロググループの選択・時間指定・更新が少ないものに対してのHistoryの利用推奨が挙げられます。
デフォルトクエリを①で実施することで、ロググループのフィールドを②から③が展開されて確認することができます。
@はCloudWatchが自動的に生成するフィールドです。@messageフィールドには、解析されていない生のログイベントが含まれます。
fields @timestamp, @message, @logStream, @log
| sort @timestamp desc
| limit 1000
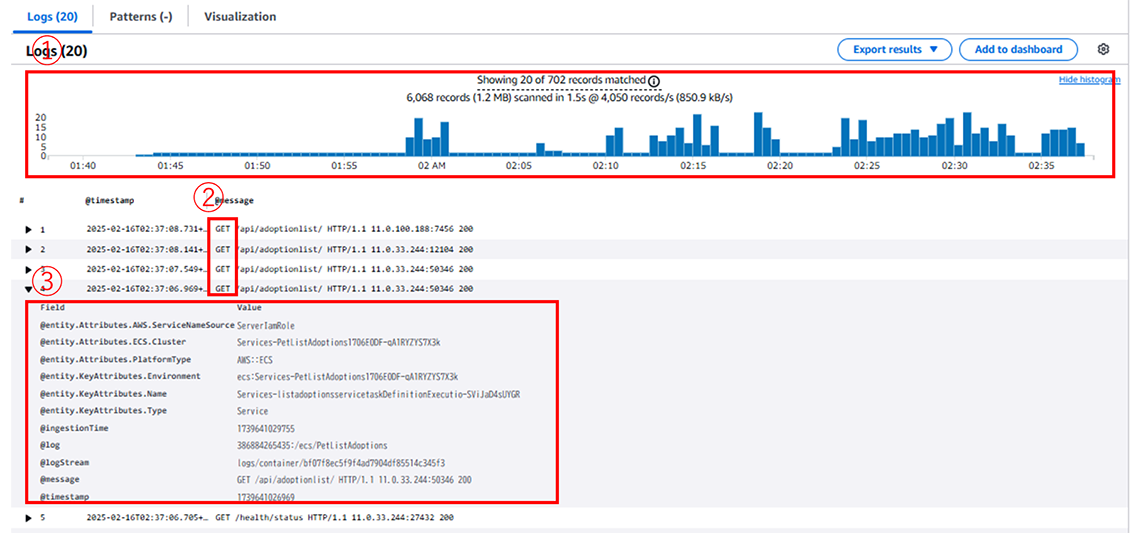
@messageフィールドはカラムとして認識されないので、文字として取得する方法を取ります。結果にはデフォルトで①のように横軸が時間で、縦軸がビン数のヒストグラムを提示してくれます。②でGETがフィルタリングしていることが分かり、クエリ文で選択しなかったfieldsも③のように展開すると行レベルの情報も把握することができます。
fields @timestamp, @message
| filter @message like /GET/
| sort @timestamp desc
| limit 20
フィールドで@timestampとpetcolor, petypeを指定します。petcolorとpettypeは、@messageの中身のキー情報ですが、デフォルトクエリをすることでDiscover fieldで選択でき[※1]、得られた情報をCloudWatchのダッシュボードに組み入れることができます。
1) JSON構造ではない場合、フィールドの分割が役に立たない場合があるかもしれません。
ダッシュボードの日付を選択すると、ソースのログストリーム側で日付をフィルタリングをするため、クエリ文に日付を組み込む必要がない点はいい点だと思いました。
{"caller":"repository.go:103","method":"GetTopTransactions","petcolor":"white","petid":"015","pettype":"puppy","ts":"2025-02-18T06:33:04.535070903Z","xrayTraceId":"1-67b429a0-1da378b43ea3bfe0546928ec"}
fields @timestamp, petcolor, pettype
| filter ispresent(petcolor) AND ispresent(pettype)
| stats count() by pettype
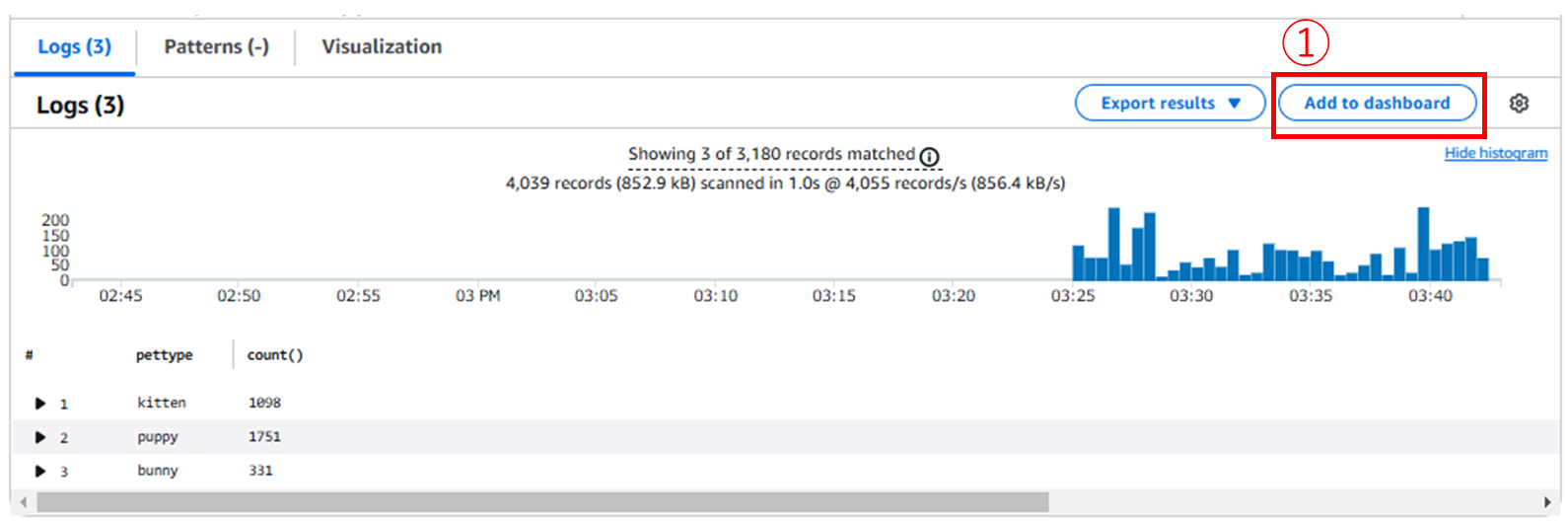
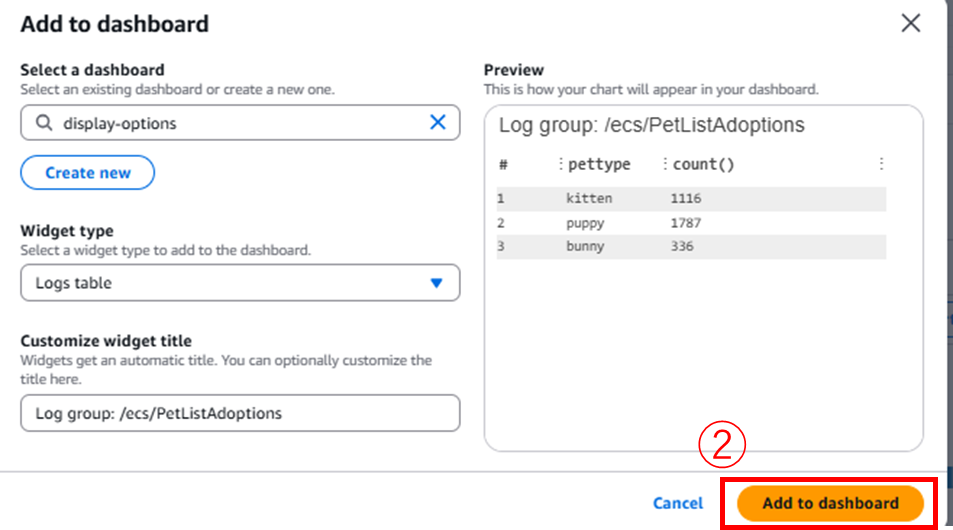
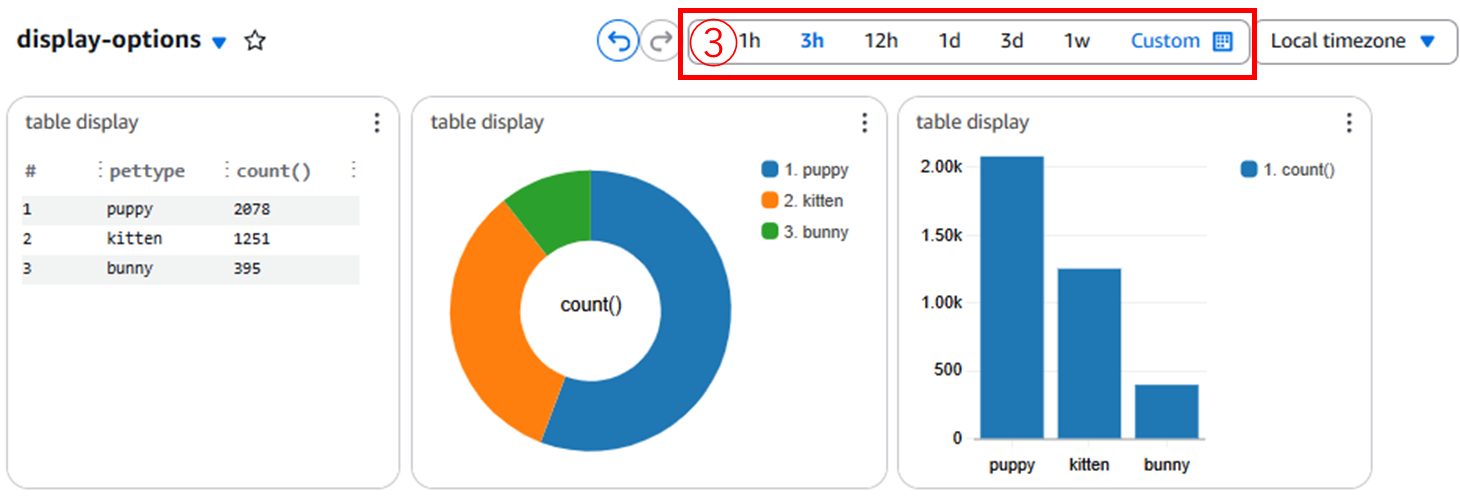
3で利用したpetcolorとpettypeはJSON構造のため、フィールドの分割をDiscoverで取得することができましたが、2で実施したような@messageフィールドをGETでフィルタリングした結果を分割することはできません。
filter @message like /POST/
| field @timestamp, @message
| sort @timestamp desc
| limit 20
andで条件を加えることでより詳細にフィルタリングをかけることができます。
filter @message like /POST/ and @message like /petId=01/
| field @timestamp, @message
| sort @timestamp desc
| limit 20
@messageフィールドでは赤い枠で順に、メソッド・パス属性・プロトコル・ソースIP・ポート・結果と分割できそうなことが読み取れます。この場合、自身でその場合はparseを用いて、分割をすることで@messageフィールド内でクエリを打つことができます。
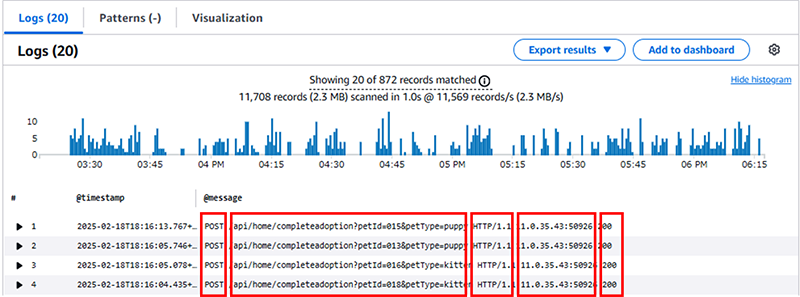
filter @message like /POST/
| parse @message "* * * *:* *" as method, request, protocol, port, status
| limit 20
@messageフィールドが分割されて自身で定義したフィールドで表現することができました。
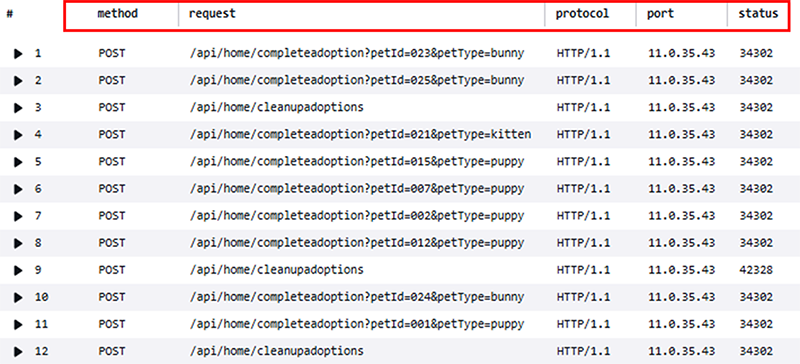
そこからさらにフィルターを掛けたクエリを打ちたい場合は、2行目で定義した内容に加えて、さらにparseで新たなフィールドを定義します。実施すると新たなフィールドが追加されるので、表示を限定したい場合はdisplayを利用します。
filter @message like /POST/
| parse @message "* * * *:* *" as method, request, protocol, port, status
| parse request "*?petId=*&petType=*" as requestUrl, id, type
| display @timestamp, requestUrl, type
| limit 20
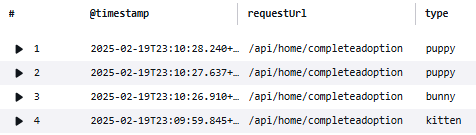
これまでは行に注目するクエリを打ってきましたが、列に注目するクエリではstatsを利用します。末尾に`by bin(5m)`と打つと、5分間隔のビン数を得ることができ、可視化で折れ線グラフを選択すると時系列変化を追うことができます。
filter @message like /POST/
| parse @message "* * * *:* *" as method, request, protocol, port, status
| parse request "*?petId=*&petType=*" as requestUrl, id, type
| stats sum(type="puppy") as puppy, sum(type="kitten") as kitten, sum(type="bunny") as bunny by bin(5m)
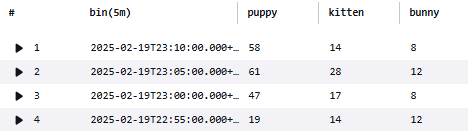
先ほどはparseを利用して@messageフィールドで新たにフィールドにしたい内容を*で表現しましたが、正規表現でも同様の処理を図ることができます。Afterでは@messageフィールドを各要素に区切ることなく、いきなりtypeの取得を図ることができています。
filter @message like /POST/ and @message like /completeadoption/
| parse @message "* * * *:* *" as method, request, protocol, ip, port, status
| parse request "*?petId=*&petType=*" as requestUrl, id, type
| display @timestamp, type
| limit 20
filter @message like /POST/ and @message like /completeadoption/
| parse @message /&petType=(?<type>\w+) HTTP/
| display @timestamp, type
| limit 20
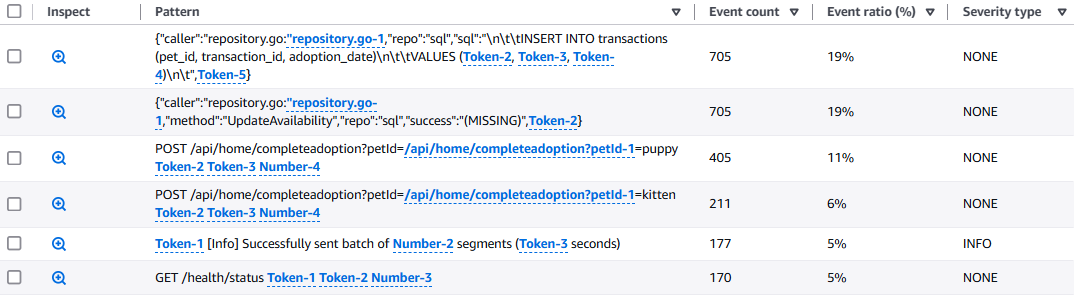
大量のログを検索やフィルタリングをするには、messageフィールドの構造の把握などが必要ですが、patternクエリを型の列レベルの情報把握を手助けしてくれます。頻発ワードを選択すると、Patten inspectで新しいウィンドウが立ち上がり、行レベルの情報を提供してくれます。
pattern @message
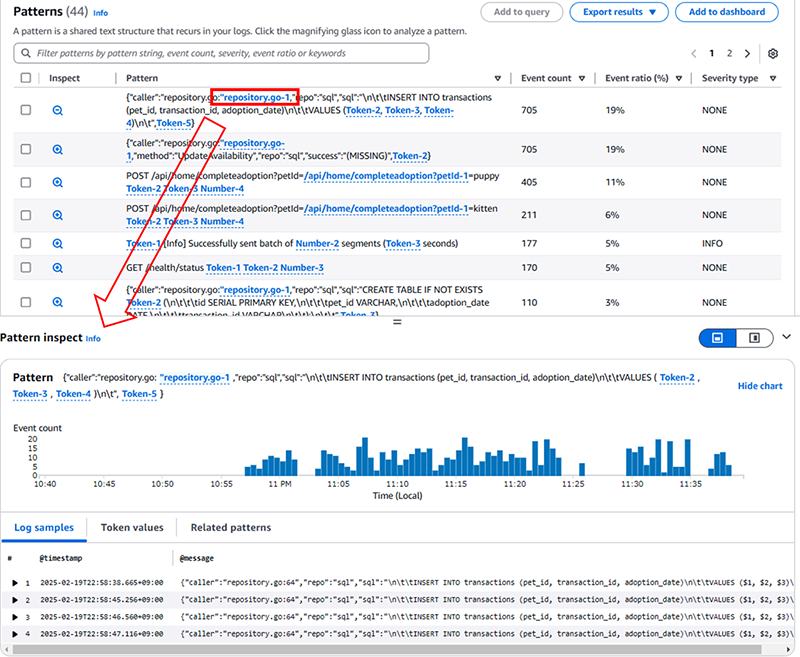
dedupは特定のフィールド値に基づい重複するログを削除することができます。”Generating presigned url"の重複が削除されたことが確認できます。
fields @timestamp, message
| sort @timestamp desc
| dedup message
| limit 20
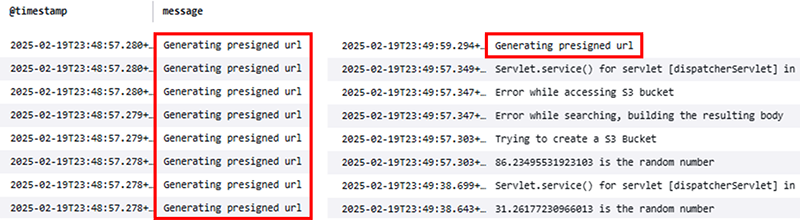
好きなワードを打つと、クエリ文が生成されます。まだまだフィールドの中身を丁寧に提示すれば構文エラーの手間は大きく省けると思いました。
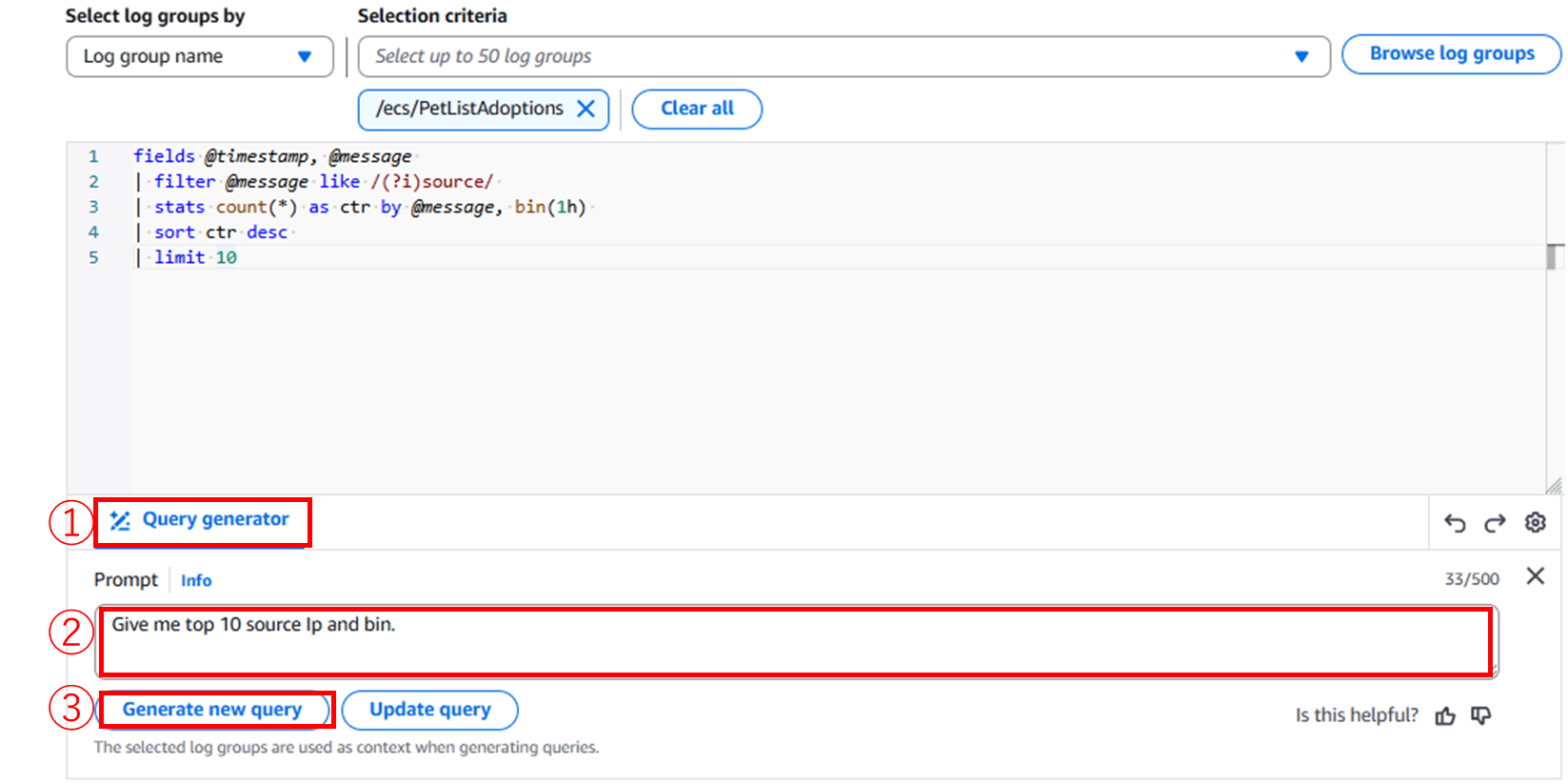
`pattern @message`のクエリを打ってもPatternsで傾向を図ることができますが、デフォルトクエリでも制限を2000ほどに落とすとPatternsが生成されます。
※基本的には`patterns @message`の結果と変わらないように見えましたが、少ないフィルタリングをするとパターンが見れることはよいと思いました。
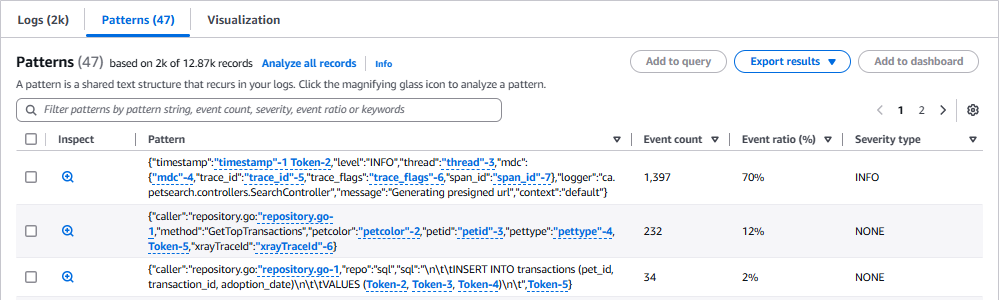
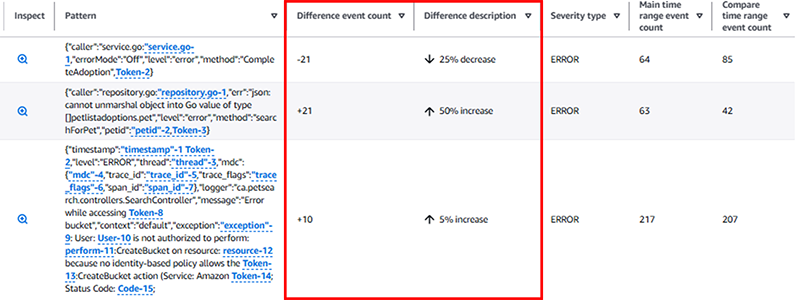
また、上段でCompareをOnにするとクエリ文が追加されます。`pattern`も追加されているので、デフォルトで裏実行されているかもしれません。前回からの傾向を把握することができます。
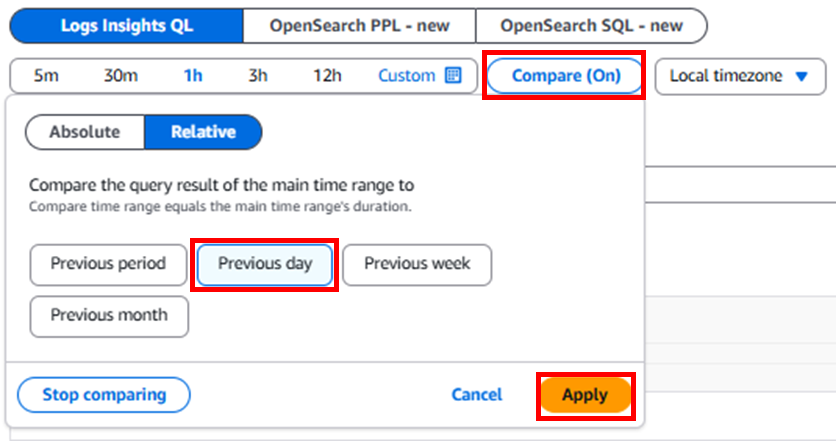
fields @timestamp, @message, @logStream, @log
| sort @timestamp desc
| limit 2000
| pattern @message
| diff previousDay
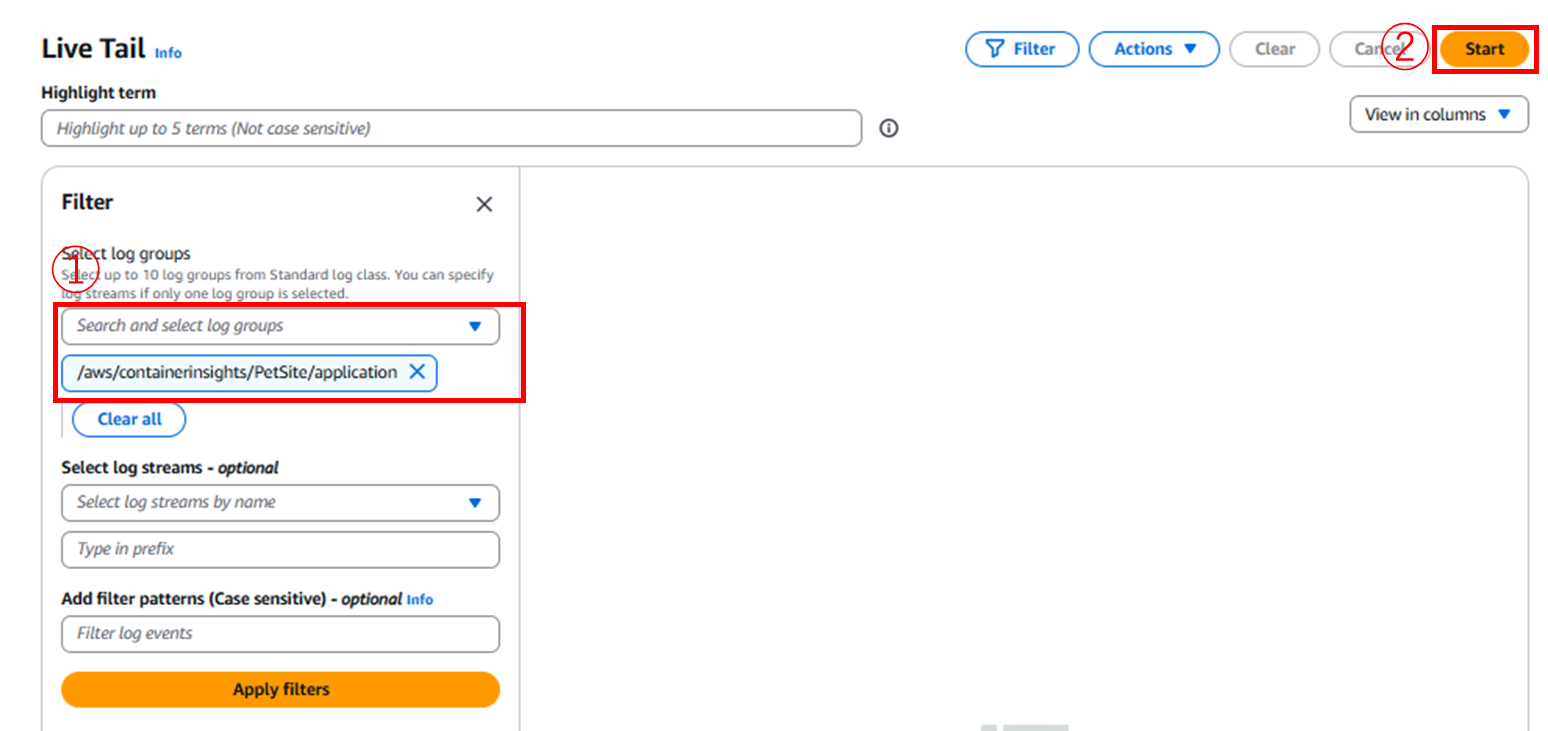
Live Tailは、ログのリアルタイムな対話型ビューを提供する分析機能で、アプリケーションのライフサイクル全体にわたる問題の迅速な検出とタイムリーな解決を可能にします。
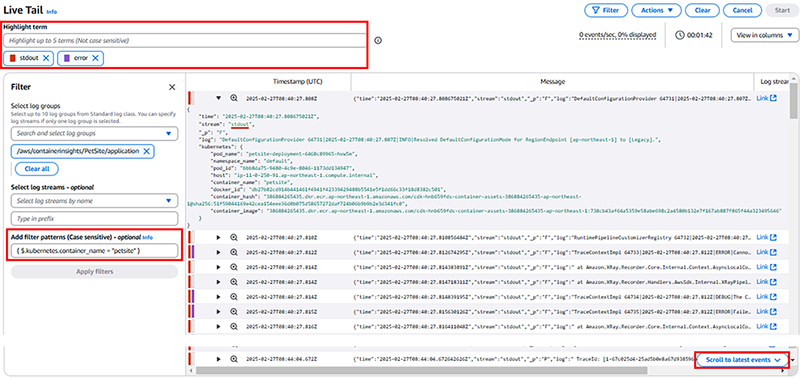
CloudWatchのサイバーからLive Tailからアクセスできます。ロググループを選び、Startを押すとリアルタイムに流れてくるログを確認できます。調査が始まるとログが一気に流れ込み、末尾が最新のログになります。Linux上のログで確認する`less stdlog`でCtrl-Fでログの動的確認のような形で、Scroll to latest eventsボタンが用意されています。Filter Patternでは、messageフィールドがJSONである場合、キーとバリューを入力することでログデータをしょぼることができます。Hilight termではフィルタリングされた内容をさらに色分けで提示してくれます。
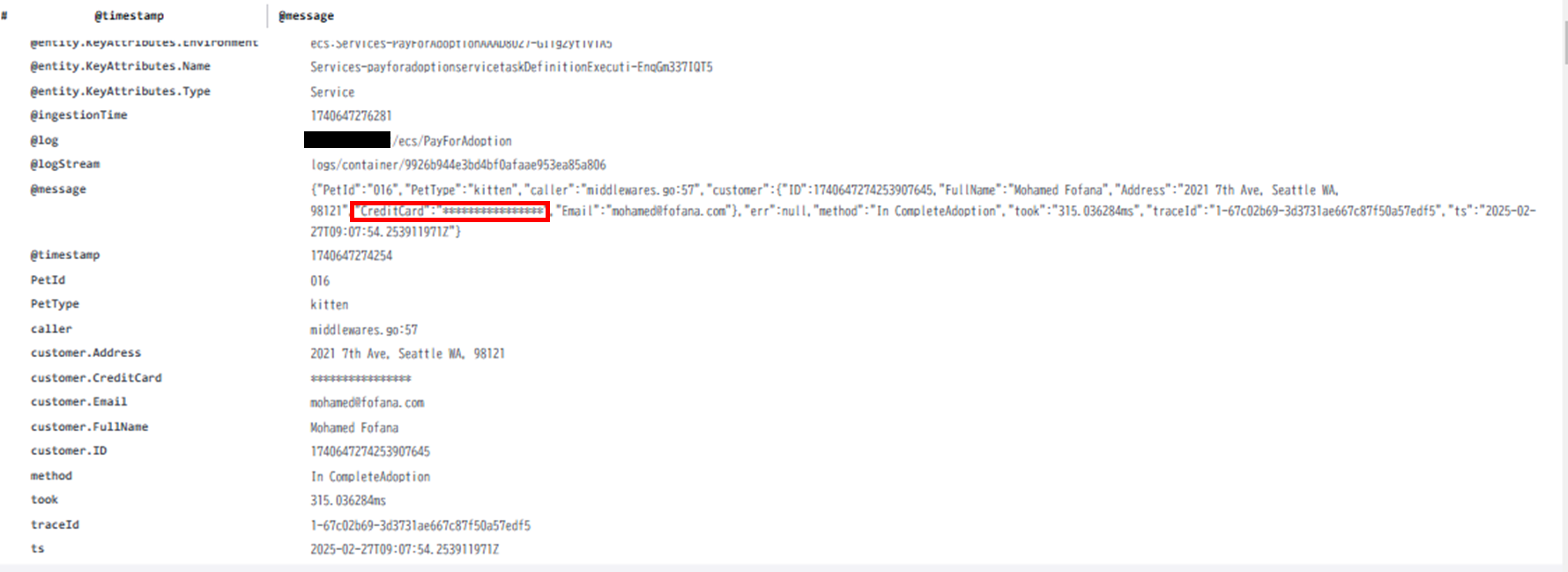
CloudWatch logsでは、機密データの検出もフォローしています。秘密鍵やAWSのシークレットアクセスキー、クレジットカード番号、運転免許証や社会保険番号などの個人を特定できる情報(PII)などが当たります。
LoggroupsのActionsのプルダウンから、Create data protection policyを選択します。Credit CardNumberを選択して適用後に見に行くと*で埋められていることが確認できました。
ログに機密性の高い情報を吐き出すべきかを適切に設定する必要性があります。
NTT東日本では、AWSなどクラウドに関するお役立ち情報をメールマガジンにて発信していますので、ぜひこちらからご登録ください。
ObserbervilityのWorkShopとして、はじめのログ編としてCloudWatch logsで提供されているLogs Insightを中心にクエリレベルまで紹介しました。運用にあたって、規模が小さいアプリケーションなどではダッシュボードの構築まではできていないかもしれませんが、ログを吐き出していることは実施されていると思います。CloudWatch Agentとうまく合わせてCloudWatch Logsとうまく連携できれば、Logs Insightから過去の傾向分析を図ることも可能であることを実感しました。
最後まで読んでいただき、ありがとうございました。次回はメトリクス編を紹介させていただきます!






相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

