
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


 |
こんにちは、白鳥です。 |
|---|
本日はAmazon Application Recovery Controller(以下、Amazon ARC)を利用した高可用性について解説していきたいと思います。
先日(2024年10月11日)、クロスゾーン負荷分散を有効化したNetwork Load BalancerでのAmazon ARCによるゾーンシフト・ゾーンオートシフト対応が発表されましたが、Amazon ARCの概念が少し難解なので、概念を理解しながら進めていきたいと思います。
アップデートの発表資料
Cross-zone enabled Network Load Balancer now supports zonal shift and zonal autoshift

目次:
Amazon ARCは、マルチアベイラビリティーゾーンやマルチリージョンを利用している環境において障害や不具合が発生した際の高速復旧の実行に使われます。具体的には、障害や不具合の起きているアベイラビリティーゾーンやリージョンを使用しないよう分離して、サービスを継続するための仕組みとなります。
2021年7月にAmazon Route 53 Application Recovery Controllerとしてリリースされましたが、2023年1月にゾーンシフトの機能がリリースされ、Amazon ARCとして利用可能になっています。機能としては以下の機能が搭載されています。
ゾーンシフトは、障害や不具合の起きているアベイラビリティーゾーンからELBのトラフィックを遠ざけます。ゾーンシフトの場合、手動(マネジメントコンソールやAPI/CLI)で設定し、障害や不具合の起きているアベイラビリティーゾーンを使用しないようにすることができます。具体的には、使用しないアベイラビリティーゾーンのELBヘルスチェックを意図的に「異常」と設定してヘルスチェックを失敗させることで、ELBがリソース(EC2やECSなど)にトラフィックを送信しないようにします。イメージとしては公式ブログからの借用となりますが、1つのアベイラビリティーゾーン(az3)で非常に大きなレイテンシーが発生している場合に、このアベイラビリティーゾーンのみを使用しないように設定することができます。
ゾーンシフト前
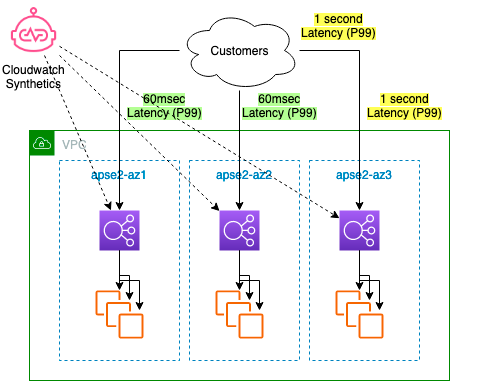
ゾーンシフト後
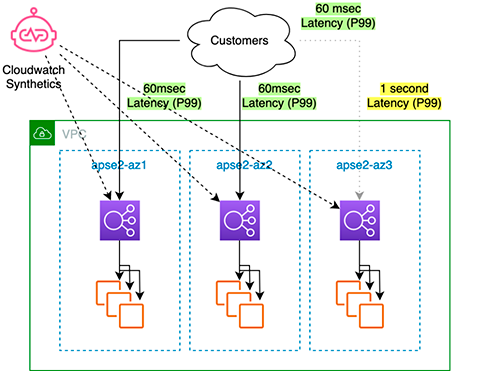
出典:Rapidly recover from application failures in a single AZ
利用できるELBは、執筆日時点では下記のとおりです。
また、ゾーンシフトの期間には有効期限を設定することができ、1時間から3日(72時間)まで設定できます。そのため、復旧の見込みを鑑みながら設定することができます。
ゾーンオートシフトは、ゾーンシフトの可否をAWS側で判断して障害または不具合の起きているアベイラビリティーゾーンを使用しないようにすることができます。AWSの内部テレメトリによって判断することができますが、注意点もあり、場合によっては影響が出ていないリソースがシフトされることもあるのと、毎週30分Practice Runと呼ばれる定期試験を行う必要があります。この30分でサービスに影響が出ないようリソースのキャパシティを事前に確保しておく必要があります。また、トラフィックのシフトは1つのみとなり、優先順位の高い順に「手動で開始したゾーンシフト」、「ゾーンオートシフト」、「Practice Run」の順番となります。

こちらがもともとAmazon Route 53 Application Recovery Controllerと呼ばれていたものになります。リージョン障害や不具合が発生した際に、Amazon Route 53と連携してフェイルオーバーを実現します。ルーティングコントロール自体はON/OFFスイッチとなり、Route 53のヘルスチェックを意図的に制御します。
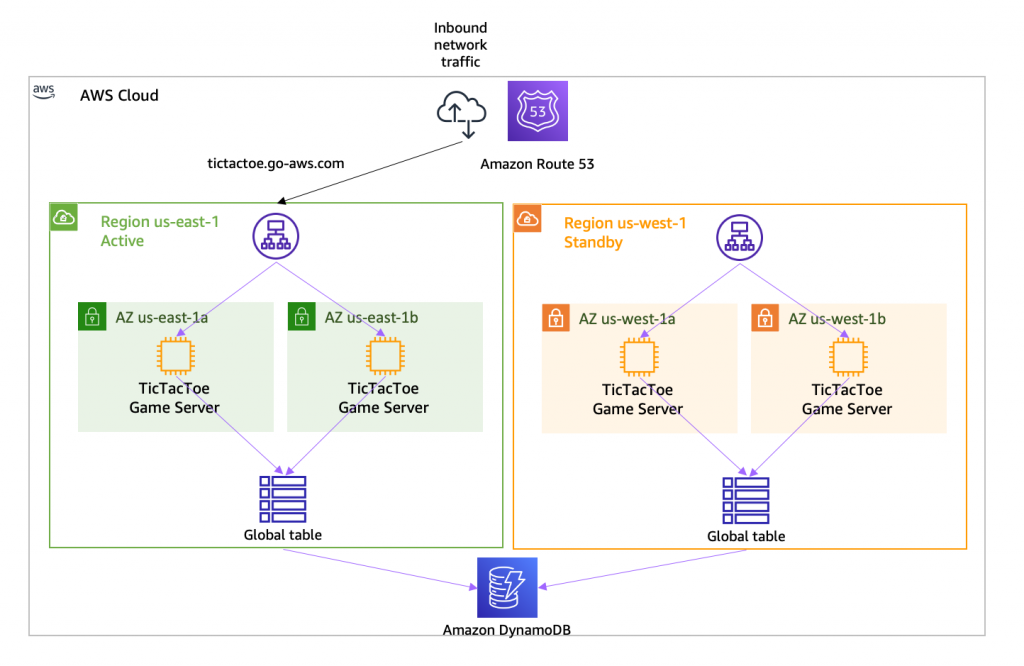
出典:Introducing Amazon Route 53 Application Recovery Controller
ルーティングコントロールにはいくつかのコンポーネントがあり、設定時に理解しておく必要があります。
クラスターは、ルーティングコントロールの更新または取得を行うためのAPIを呼び出すコンポーネントとなります。5つのリージョンに冗長化したセットとなっており、ルーティングコントロールやコントロールパネルの設定を複数持たせることができます。
クラスター上で保持されるON/OFFスイッチとなります。ONとなっているセル(ALBやEC2をセットにしたグループ)にトラフィックを送信することができます。
Amazon Route 53のヘルスチェックと連動して、ON/OFFをコントロールします。ルーティングコントロールのヘルスチェックをUnhealthyにすることで、ルーティングコントロールがOffとなり、意図的にAmazon Route 53のヘルスチェックがUnhealthyとなり、スタンバイのリージョンにトラフィックが更新されるようになります。
ルーティングコントロールと、後述する安全ルールをセットにしたグループとなります。各ELBにルーティングコントロールを設定してグループ化します。また、安全ルールを追加して意図しない「フェイルオープン」の状況を発生させないよう、1つ以上のリージョンで利用可能な状態を保ちます。
意図しない可用性への影響から守るためのルールになります。安全ルールのタイプには2つのタイプがあります。
1つまたは一連のルーティングコントロールを変更した際に、ルール設定時に設定した基準が満たされるか、そうでなければルールの変更を実施しないようにすることができます。
ルーティングルール全体のON/OFFを一定の基準で実行するか否かを決めることができるようになります。これにより、自動化による未承認の更新がされないようにターゲットのルーティングコントロールの更新を禁止することができます。
クラスターには5つのリージョンエンドポイントがあり、ルーティングコントロールの状態を変更する際にエンドポイントにアクセスします。
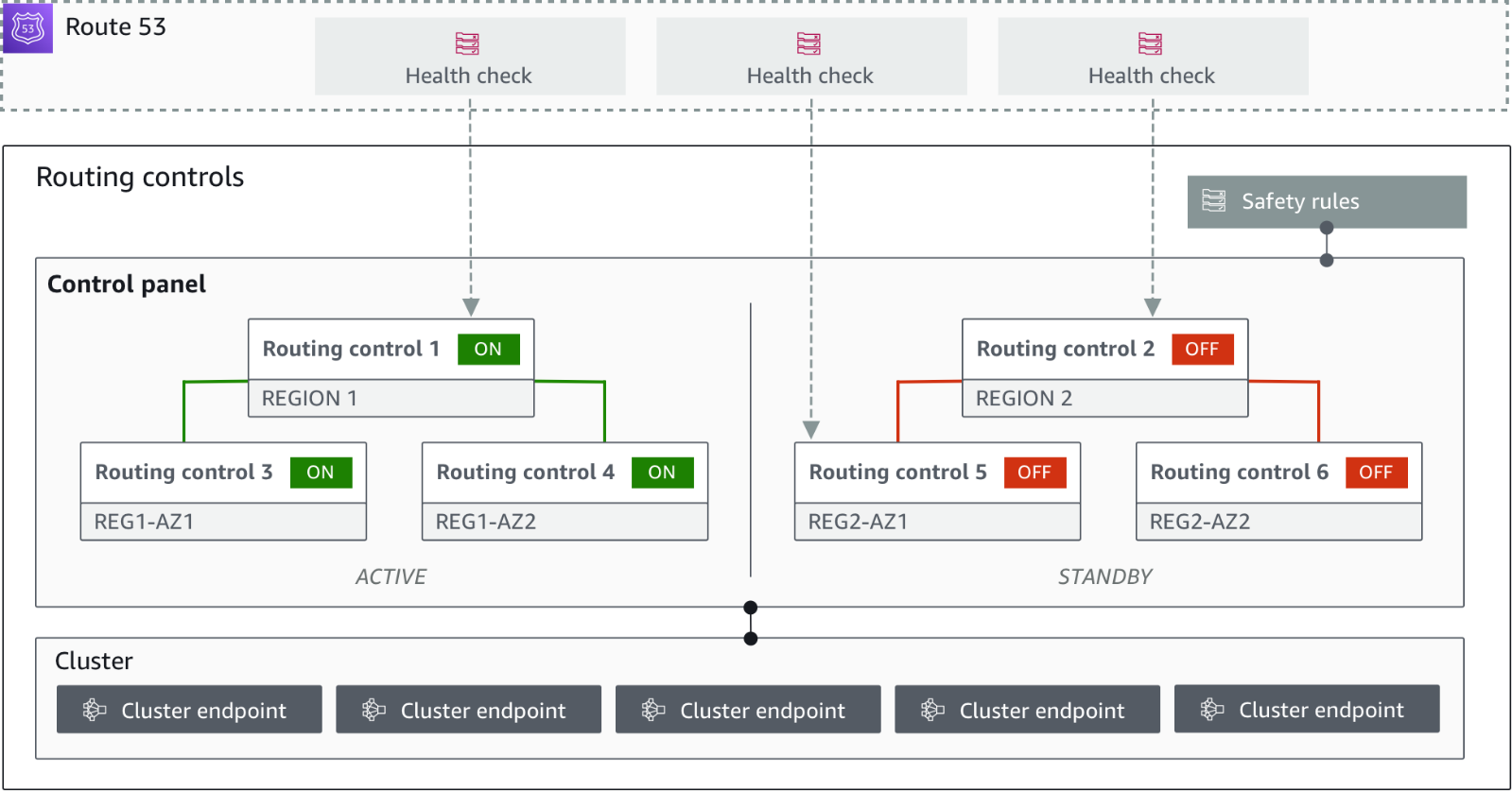
フェイルオーバーの手順を用意するだけではなく、実際にフェイルオーバーできるかどうか確認する必要があります。その際に、この準備状況チェックを行って、プロビジョニングされたリソースや、サービスクォータ、バージョンの不一致のチェックを行います。リソースタイプごとにルールセットがあり、ルールセットに応じてチェックを行うことで、準備状況の監視を行うことができます。
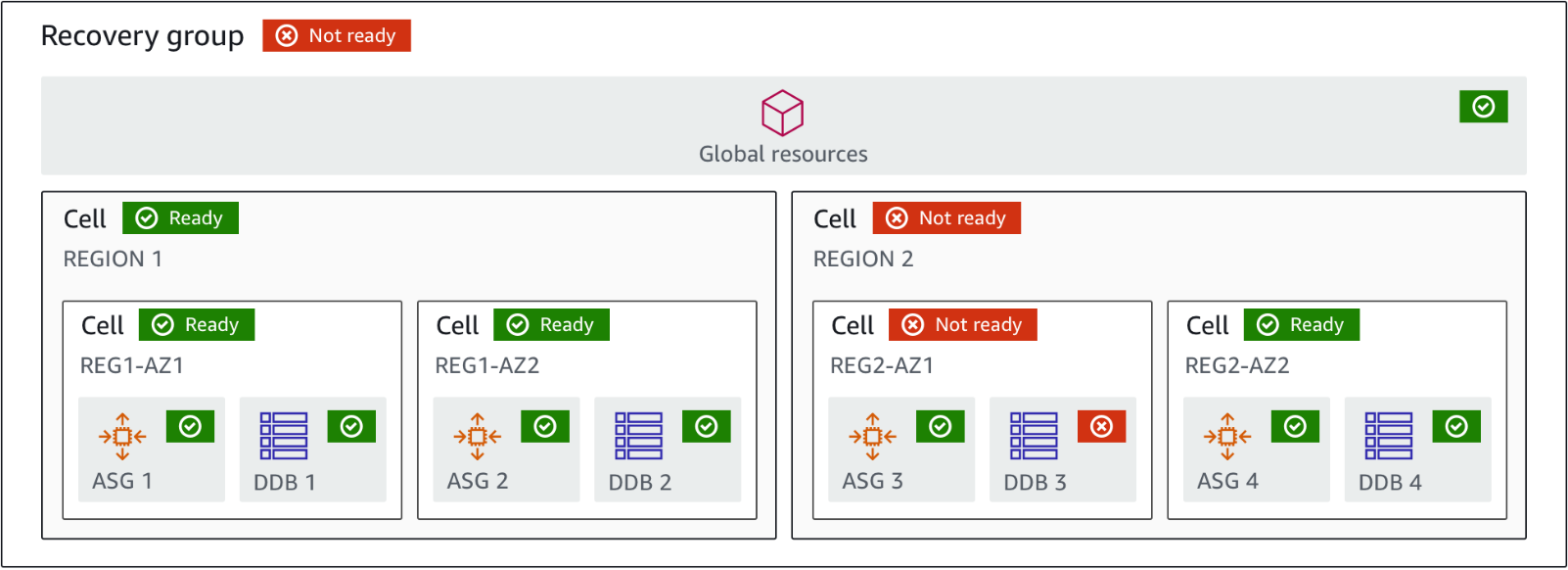
Amazon ARCの利用シーンは大きく分けて次の2つになります。
アベイラビリティーゾーンやリージョンの障害時に対象になっているリソースを素早く分離することで、サービスの継続を優先させます。まずサービスが継続できることが確認できれば、MTTRが短縮できお客さまへの影響を最小限にできます。根本的な原因の修復は、サービス正常性を確認した後に行います。このときに重要なのは、一つの障害がほかの正常なアベイラビリティーゾーンやリージョンに波及しないようにアーキテクチャを設計しておく必要があります。したがって、Amazon ARCの利用環境下ではクロスゾーン負荷分散を無効化することが必要だったのですが、先日のアップデートでクロスゾーン負荷分散を有効化したNLBで障害や不具合の発生したアベイラビリティーゾーンにトラフィックを送信しないようにできるゾーンシフトが可能になったことで、よりNLBのバックエンドにいるリソースを有効に使えるようになりました。
障害や不具合において、すべてのトラフィックにおいてHTTPステータスコードが500番台(サーバー側のエラー)のレスポンスを返す、ICMPが到達しないといった状況だけではなく、1割だけ正常にレスポンスが返ってくるという状況もあり得ます。また、HTTPステータスコードが正常に200番(正常)で応答した場合でも意図しない結果になる、機能的なバグが存在している、応答が異常に遅い、アプリケーションのバージョンアップに失敗しているなどという状態になることもあります。こうした状態をグレー障害と呼びます。グレー障害からの復旧において根本原因だけを取り除くことができればいいのですが、グレー障害は原因究明や障害個所の特定が難しく長期化することが多くなります。ひとまず復旧を優先させるために問題のアベイラビリティーゾーンやリージョンを取り除ける仕組みをAmazon ARCで導入することで仮復旧を迅速化させるように使います。
グレー障害についてより理解を深めたい場合は、下記のre:Invent 2023のセッション資料も参考になります。
AWS re:Invent 2023 - Detecting and mitigating gray failures (ARC310)
こうしたアベイラビリティーゾーン・リージョン障害やグレー障害において、Amazon ARCを使用しない復旧方法はどんなことが考えられるでしょうか?例えば、このようなことが考えられます。
障害になっているアベイラビリティーゾーンのELBやEC2等のリソースを使用しない設定に変更したり、場合によっては削除を行ったりします。復旧時は逆順をたどり、元に戻します。
バックアップ&リストア、パイロットライト、ウォームスタンバイ、ホットスタンバイといったディザスタリカバリの手順に応じて、別リージョンのリソースを準備し、Amazon Route 53のレコードとTTLを設定変更してトラフィックを移行します。元のリージョンが復旧したらデータとトラフィックをフェイルバックします。
アベイラビリティーゾーン障害の場合と同様に、問題のありそうなリソースをシステムから取り除きます。
ここまで書きましたが、一つの疑問が浮かんできます。こうした復旧手順は本当に実現可能でしょうか?復旧リソースの作成や削除がうまくいかない可能性や、グレー障害において変更・削除する必要のないリソースを使えなくしてしまう二次障害のリスクなどを踏まえて復旧シナリオを検討したいところです。つまり、正常に稼働しているリソースを設定変更するなどリスクのある手順は最小限にしておく必要があります。
AWSを利用した高可用性の実現に向けては、AWSの各サービスを理解するだけではなく、AWSが稼働しているインフラストラクチャがどのように実現しているかを知る必要があります。
AWSでは、概念として障害分離境界を定めています。これは、アベイラビリティーゾーンやリージョンといったインフラストラクチャの分離性のこともそうですが、コントロールプレーンとデータプレーンという、ポリシーやリソースの作成を行う機能とルールに基づいて処理を行う機能の2つに分割されており、それぞれの単位のことを障害コンテナと呼んでいます。一つの障害コンテナで起きた障害がほかの障害コンテナに波及しないような設計を行っており、利用者側でも障害コンテナ内で一つのセルを作ることで、耐障害性を高めることができるようになります。
AWSにはコントロールプレーンとデータプレーンがあるというお話を先ほどしました。APIを利用して、コントロールプレーンやデータプレーンの操作を行っており、データプレーンにおいてはトラフィックやトランザクションに応じた処理を行っています。
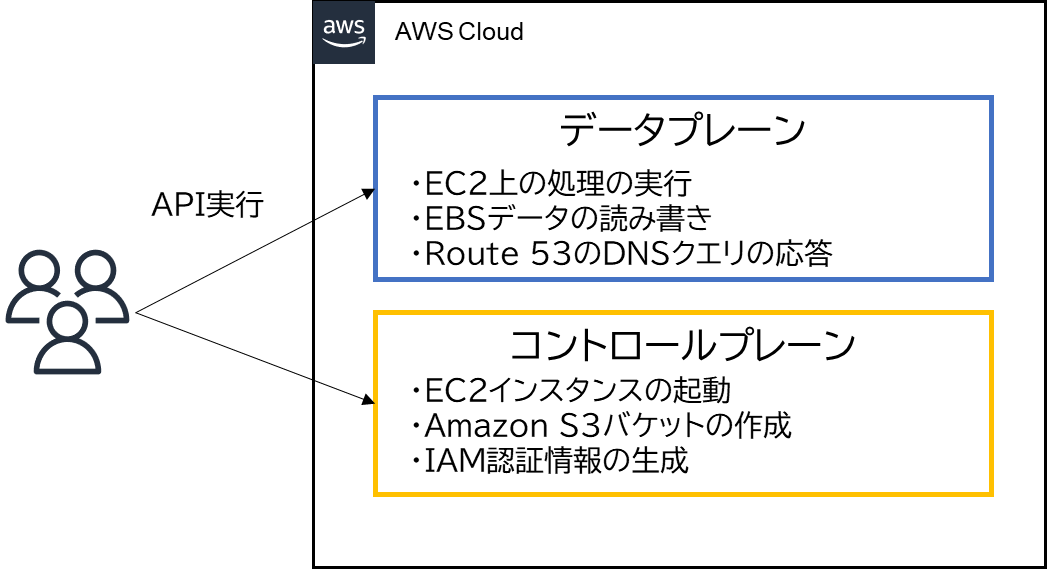
Amazon EC2やEBSボリュームといったアベイラビリティーゾーンに依存するサービスは、各アベイラビリティーゾーンでコントロールプレーンとデータプレーンを独立して持っています。
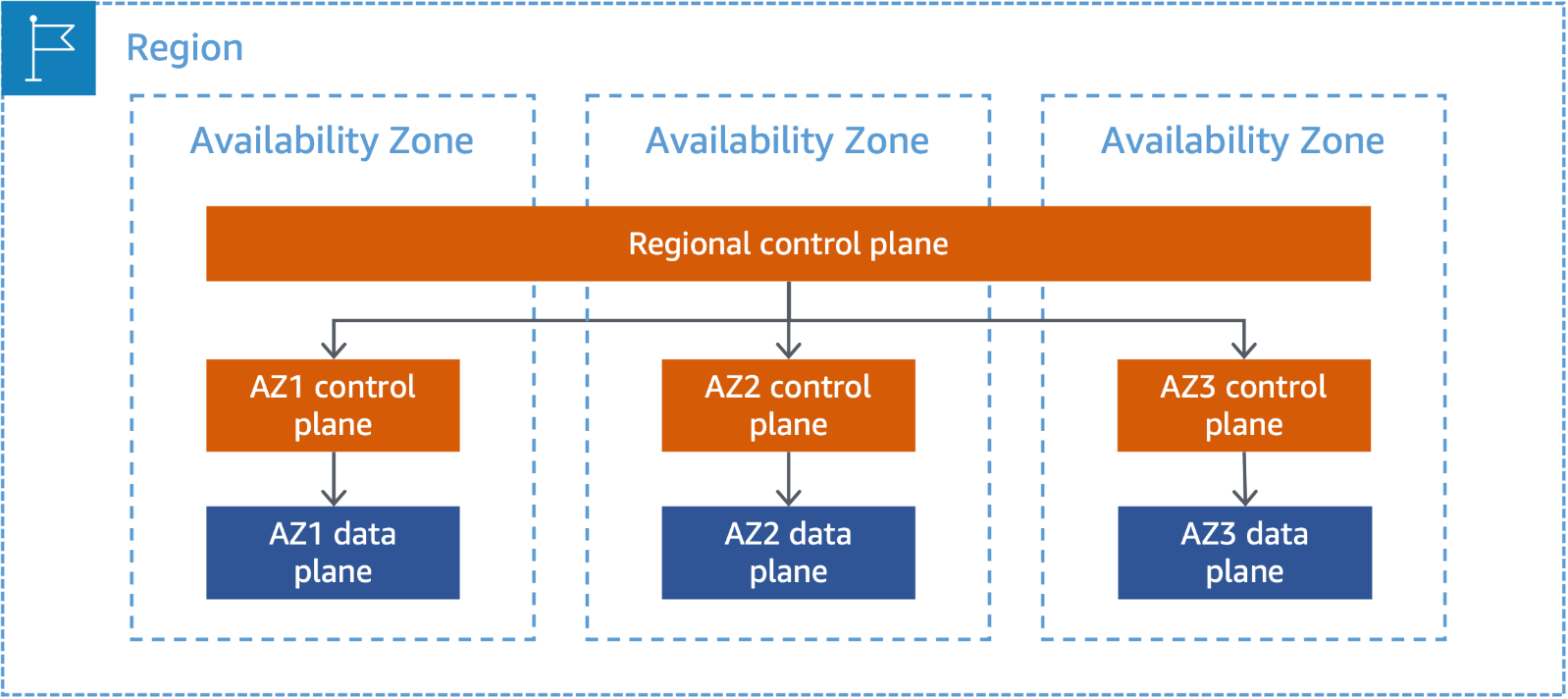
出典:ゾーンサービス
一方でAWSの公式資料によると、コントロールプレーンとデータプレーンの可用性について言及しています。簡単にまとめると、コントロールプレーンのほうが複雑な処理を行っているため、データプレーンのほうが高い可用性を持っており、静的安定性という原則を用いてコントロールプレーンとデータプレーンを分離し、もしコントロールプレーンが機能しなくなった場合でもデータプレーンは機能するように設計されています。
したがって、高い可用性を必要とする処理においては障害分離境界の原則から、データプレーンに閉じた手順で実現する必要があります。つまり、コントロールプレーン側のAPIを利用せず、データプレーン側のAPIで障害に備える必要があります。
話をAmazon ARCに戻しましょう。最初の機能説明を振り返ると、Amazon ARCのゾーンシフトやルーティングコントロールでは、ヘルスチェックを意図的に異常とすることでトラフィックを特定のアベイラビリティーゾーンやリージョンから分離する機能を提供することでした。ヘルスチェックの判断はデータプレーンで行われるため、データプレーン側に障害分離境界を設けることができ、可用性を向上させることができるようになります。
Amazon ARCを利用する際のベストプラクティスはいくつかありますが、ゾーンシフト・ゾーンオートシフトとルーティングコントロールに分けてご紹介します。
今回はAmazon ARCの機能と、ベースになるAWSにおける高可用性の実現に向けた概念の解説となりました。次回のコラムで、実際にAmazon ARCを使ったフェイルオーバーを試してみたいと思います。
NTT東日本では、LAN環境からネットワーク、クラウド環境まで幅広いエリアでのお客さまのクラウド化や高可用性の実現、ビジネスモデルの進化のお手伝いをさせていただいております。
経験値豊かなメンバーがご担当させていただきますので、是非お気軽にお問い合わせください!






相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

