






AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


 |
突然ですが、先日こんな出来事がありました。 |
|---|
~とある平日の夕方~
妻:「今日の夜ご飯、三色丼にしようと思うから仕事終わったら、さやえんどう買ってきて」
私:「はいよー」
~終業後、スーパーにて~
私:(ごはん早くたべたいから急いでさやえんどう買って帰ろう~)
(これだろう!さやえんどう!レジへGo!)
~帰宅後~
私:「買ってきたよー」
妻:「ありがとうー」
妻:「って、え?これは・・・笑」
_人人人人人人人人人人_
> スナップえんどう <
 ̄Y^Y^Y^Y^Y^Y^Y^ ̄
急いでいたあまり、「さやえんどう」と「スナップえんどう」を間違えて買ってきてしまいました(実話)。
スナップえんどうを使った三色丼を食べながら、悔しさと好奇心から私は思いました、
さやえんどうとスナップえんどうを識別するアプリ作ってみたら勉強になるし面白いのでは?と。
ということで、今回はMicrosoft Power AppsとAzure Cognitive Servicesを活用して、えんどうの画像識別アプリを作ってみましたので、ご紹介します。
今回は題材をえんどうの画像にしていますが、使う画像を変えれば他のテーマにもそのまま利用できますので、ご参考になれば幸いです。
(スーパーでラベルをちゃんと見たらアプリいらないでしょ、というツッコミが聞こえてきそうです)
Power AppsとCognitive Servicesで役割が分かれていますので、作成手順を含めて前編と後編に分けてご紹介します。

はじめに、今回作成するアプリの全体概要を図にまとめました。
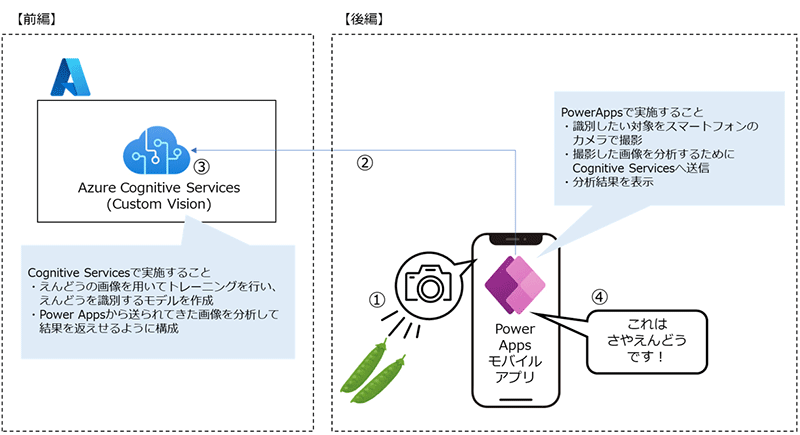
前編ではAzure Cognitive Services側の設定を行い、後編でPower Appsの設定を実施します。
それぞれの役割は以下の通りです。
Power Apps(キャンバスアプリ)
Cognitive Services
それでは早速作っていきます。
今回は以下の材料を用意しました。
※せっかくなので、似た野菜として「さやいんげん」も用意し、それぞれしっかりと識別できるか試します。
なお、本アプリ作成にはPower Appsのライセンスと、Azureサブスクリプションが必要ですのでご注意ください。
お持ちでない方は、Power Appsの試用版ライセンスやAzureの無料アカウントでも実施可能です。
Power Apps試用版
Microsoft 365 開発者プログラム
https://developer.microsoft.com/ja-jp/microsoft-365/dev-program
Azure無料アカウント
Cognitive ServicesはMicrosoft社がAzure上で提供しているクラウドベースのAIサービスで、用途ごとに視覚、音声、言語、決定などの人間の認知(Cognitive)を模したさまざまな機能が提供されています。これらに加えて、最近話題のOpenAIのAIモデルをAzure上で利用できるAzure OpenAI ServiceもCognitive Servicesのひとつとして提供されています。
今回は、視覚として提供される機能のひとつである「Custom Vision」を利用します。Custom Visionでは、利用者の用途に合わせて画像を学習させてAIモデルを作成することができるため、えんどうの識別に特化したモデルといったものも作成可能です。また、Custom Visionにはモデル作成用のポータル「Custom Visionポータル」が用意されており、専門的な知識がなくても作成を進めることができます。
本コラムでの実施内容は以下の通りです。②~⑤の作業は全てCustom Visionポータルで行います。
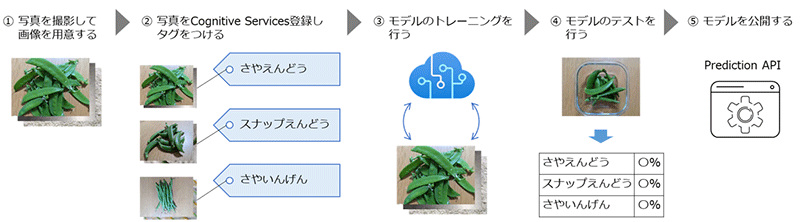
Cognitive Servicesでのモデルのトレーニングとテスト用に画像を用意する必要があります。
この作業に最も時間がかかったような気がしますが、さやえんどう、スナップえんどう、さやいんげん、それぞれの写真をたくさん撮影しました。
材料で準備したお皿やタオル等を入れ替えて背景を変えたり、画像内に映る対象の本数をかえたり、撮影する角度を変えたり等、工夫しながら学習に利用できる画像の数を確保しました。それぞれ138枚撮影し、128枚をトレーニング用、10枚をテスト用としています。
Custom Visionで利用できる画像には以下の条件がありますので、画像準備の際はご留意ください。
| 対象 | トレーニング用 | テスト用 |
|---|---|---|
| さやえんどう |
|
|
| スナップえんどう |
|
|
| さやいんげん |
|
|
本コラムでは公式ドキュメントの手順を参考に設定を進めます。
モデルの作成と予測に必要なAzureリソースを作成していきます。
まず、Azure Portalにログインし、Cognitive Servicesのページへ移動します。
左メニュー内の「Custom Vision」をクリック。
「+作成」をクリックして、Custom Visionのリソースを作成します。
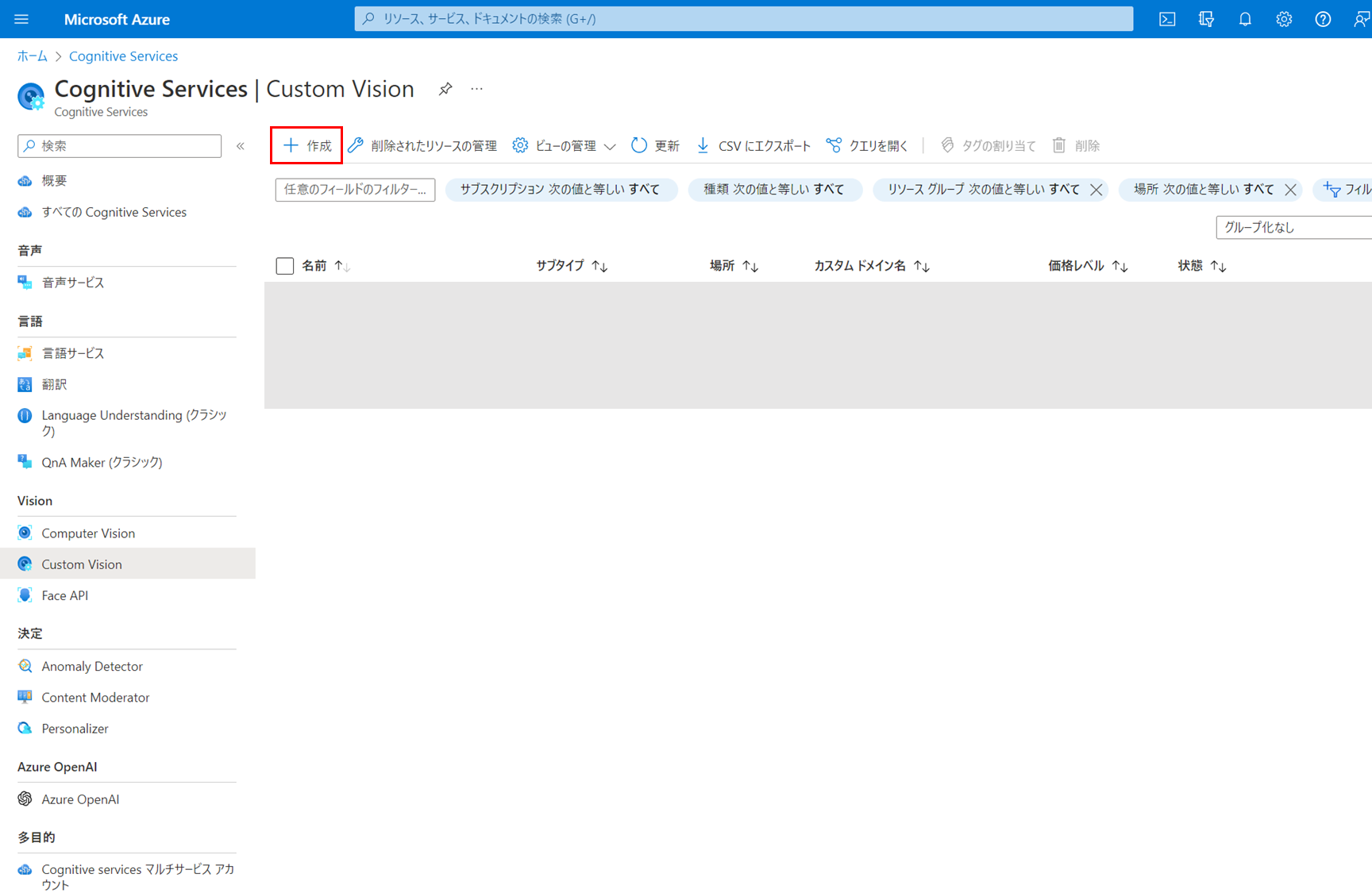
作成オプションは「両方」を指定します。Custom Visionには、モデルのトレーニング用のリソースと、モデルを使った予測用のリソースの2種類のリソースがあります。今回はどちらも利用するため、「両方」を指定して2種類のリソースを作成します。
サブスクリプションとリソースグループは、ご利用される環境のものを指定または新規に作成します。
インスタンス名を指定します。ここで登録した名前は、モデル作成後に発行するAPIのエンドポイントにも利用されます。
本コラムで各リソース名の一部に利用している「pea」は「えんどう」を意味しています。
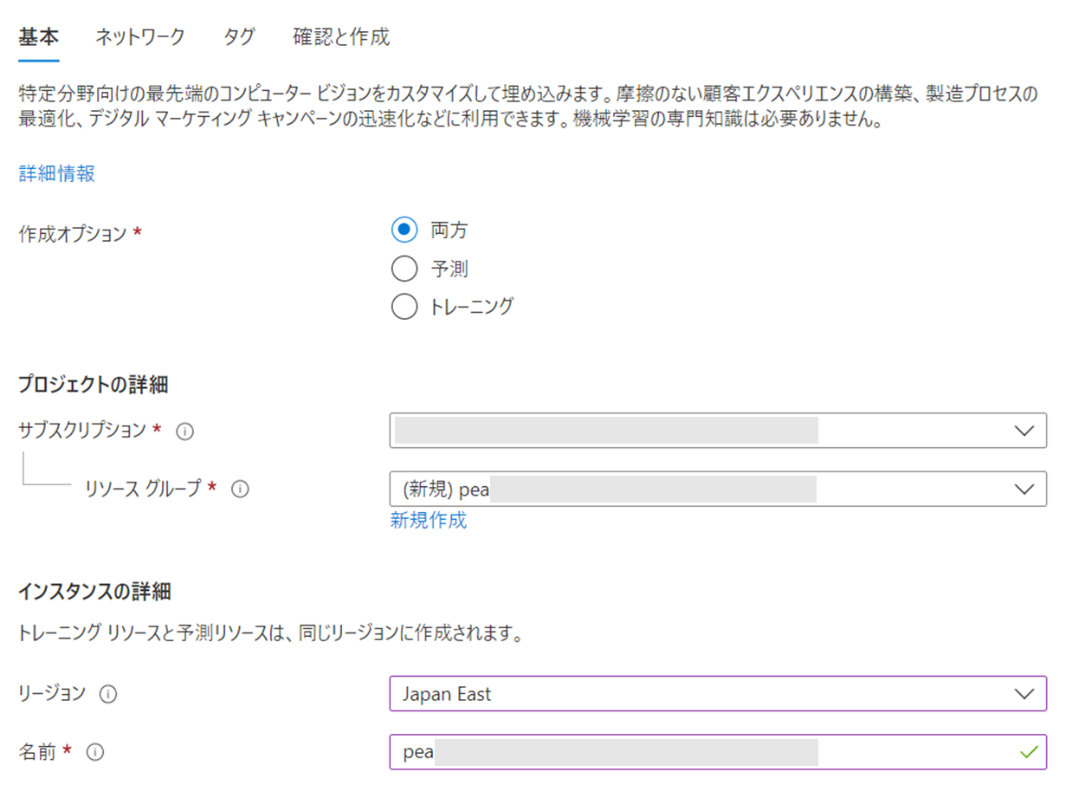
各リソースの価格レベルを選択します。ここではF0 (Free) を選択しました。学習させる画像枚数やタグの数が多い場合など、必要に応じて S0 (standard) を選択してください(詳細は公式ドキュメントをご参照ください)。リソース作成後でも価格レベルを変更可能です。
価格レベルを選択したら「確認と作成」をクリックします。個別にネットワークやタグの設定をしたい場合は「次:ネットワーク」から設定が可能です。
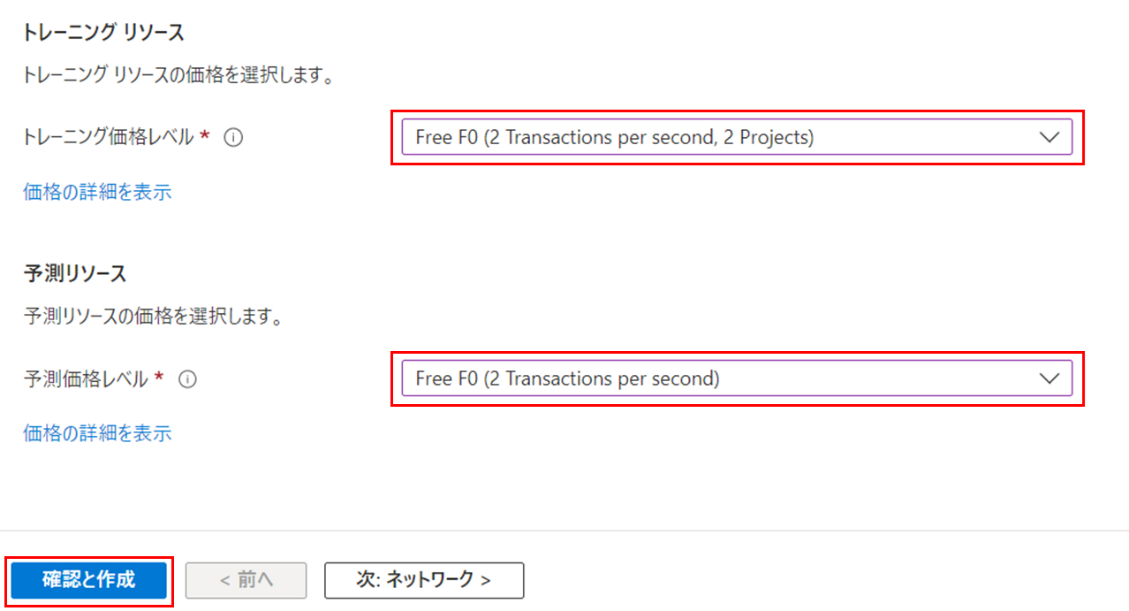
検証が成功していること、作成するリソースの情報が正しいことを確認し、「作成」をクリック。
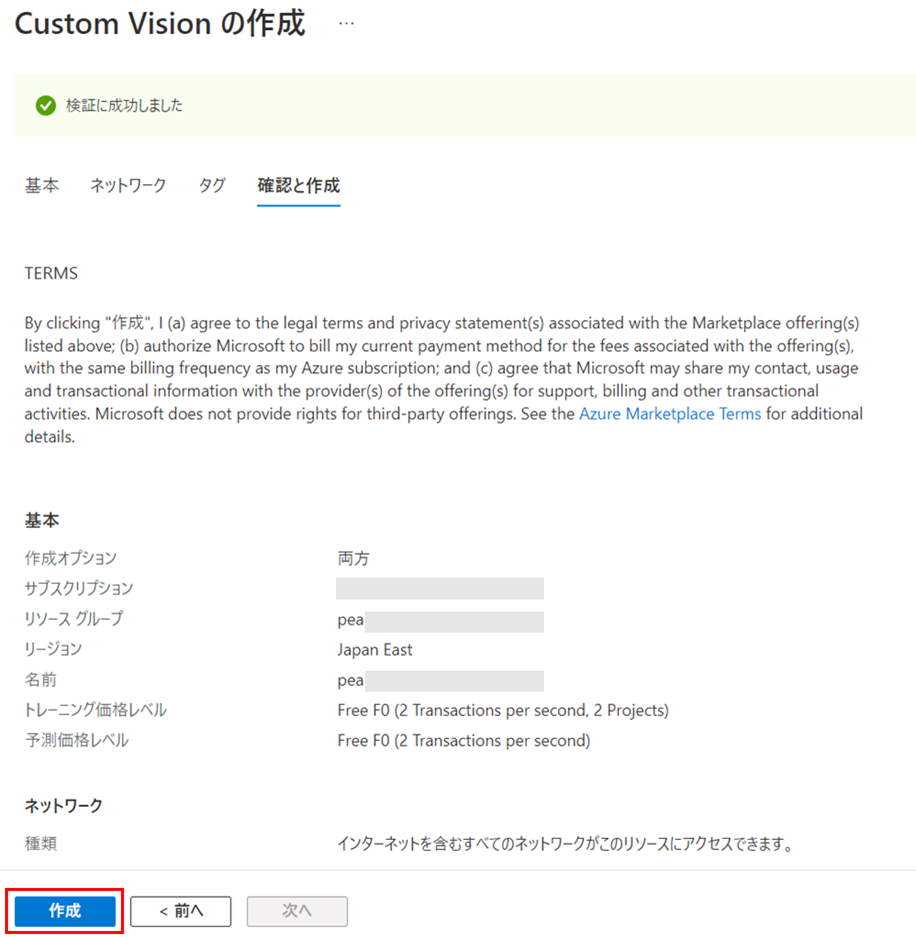
Custom Visionのページにて、2つのリソースが作成されていることを確認します。サブタイプ「CustomVision.Training」がトレーニング用、「CustomVision.Prediction」が予測用のリソースです。
トレーニング用のリソースの名前をクリックし、設定を進めます。
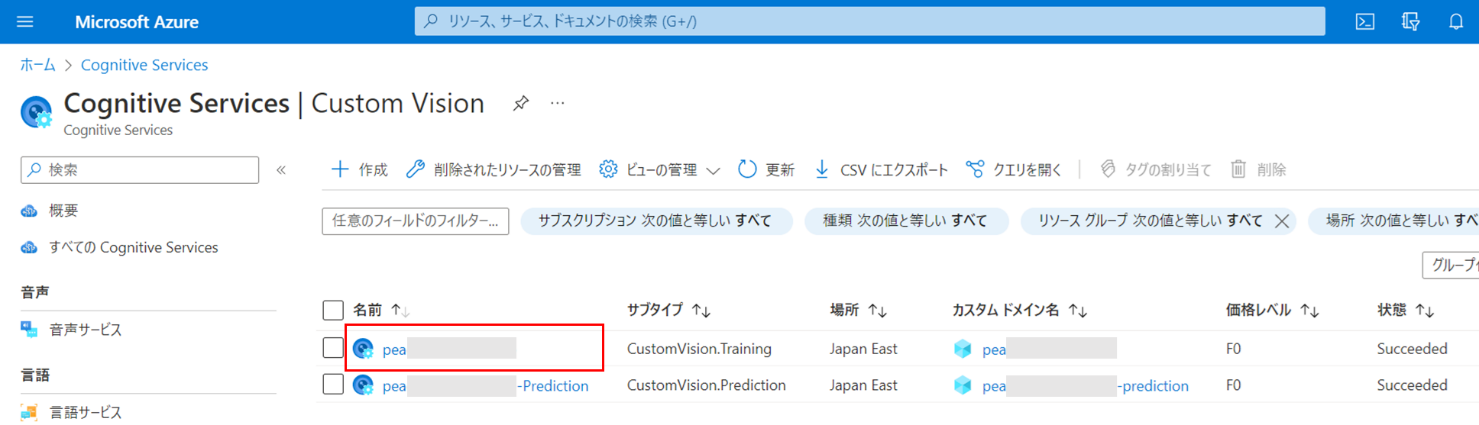
「Custom Visionポータル」をクリック。
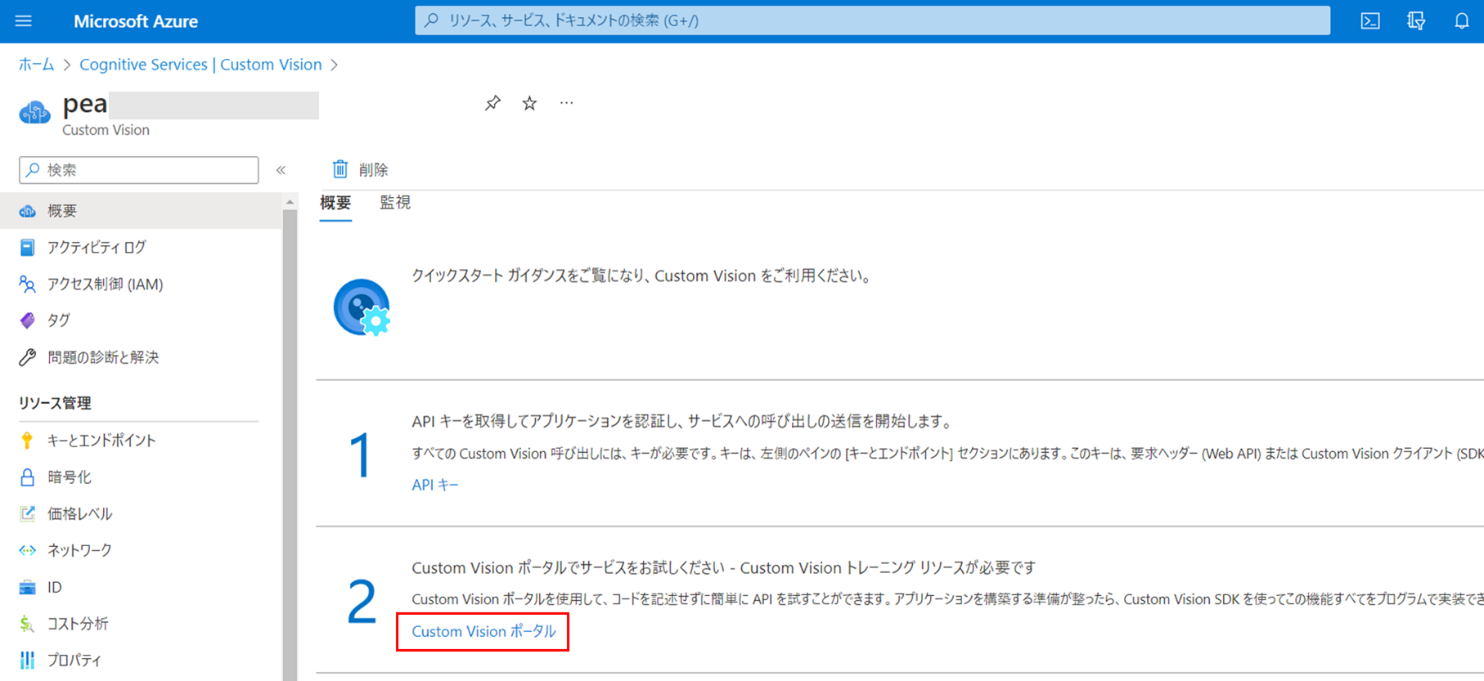
Custom Visionポータルに遷移しますので、「SIGN IN」をクリック。
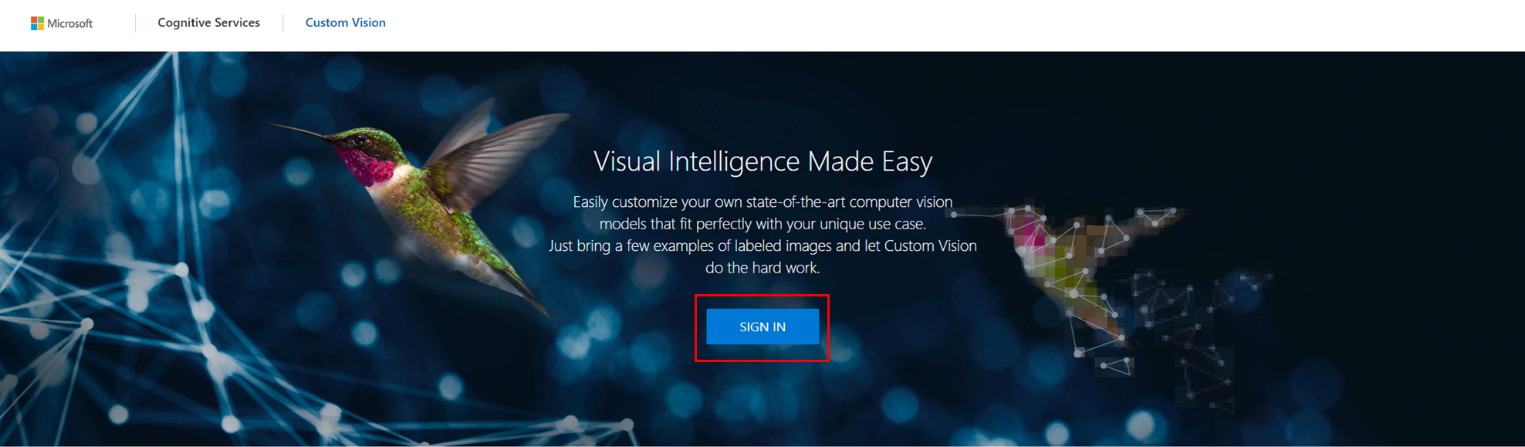
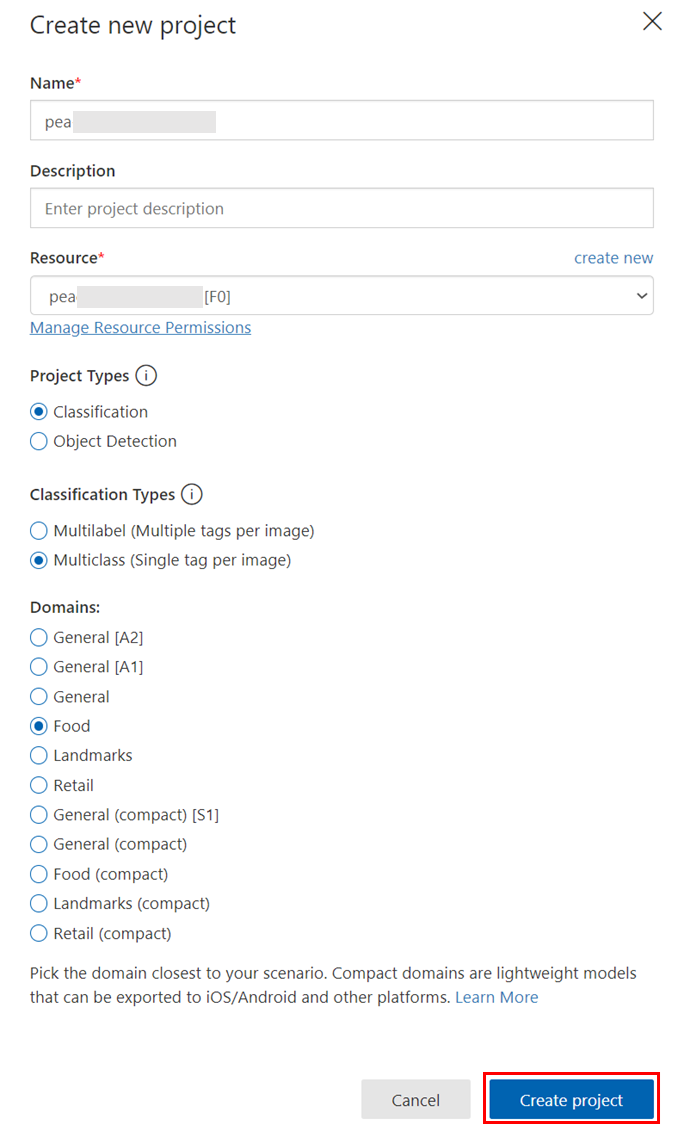
新規にプロジェクトを作成します。モデル作成に使用する画像などは、このプロジェクト単位で管理されます。
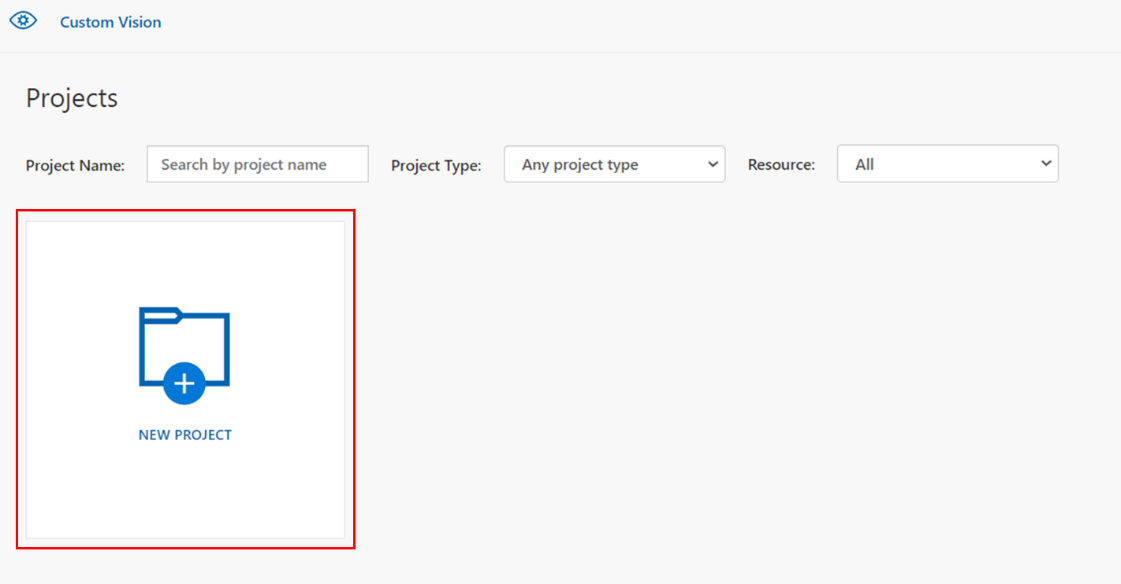
Nameに任意のプロジェクト名を指定します。
Resourceでは、先ほど作成したCustom Visionのトレーニングリソースを選択します。
Project Typeでは、今回は対象の画像がどの野菜の画像なのかを予測して分類したいので、Classification(分類)を選択しました。
Classification Typeでは、今回は1画像につき1つのタグを指定するため、Multiclassを選択しています。(1画像内に映っているものがどの野菜なのかを1つだけ予測して回答することを想定しているため。)
Domainsは、Foodを選びました。分析したい対象がどういったものなのかに応じて選択可能です。詳細は公式ドキュメントをご参照ください。
上記完了したら「Create Project」をクリック。
やっとでCustom Visionに画像を登録する準備が整いましたので、用意した画像をCustom Visionに登録していきます。登録の際は、同じタグを付けたい画像をまとめて登録し、同時にタグ付けが可能です。
Custom Visionポータル左上の「Add images」をクリックし、登録したい画像をまとめて選択します。
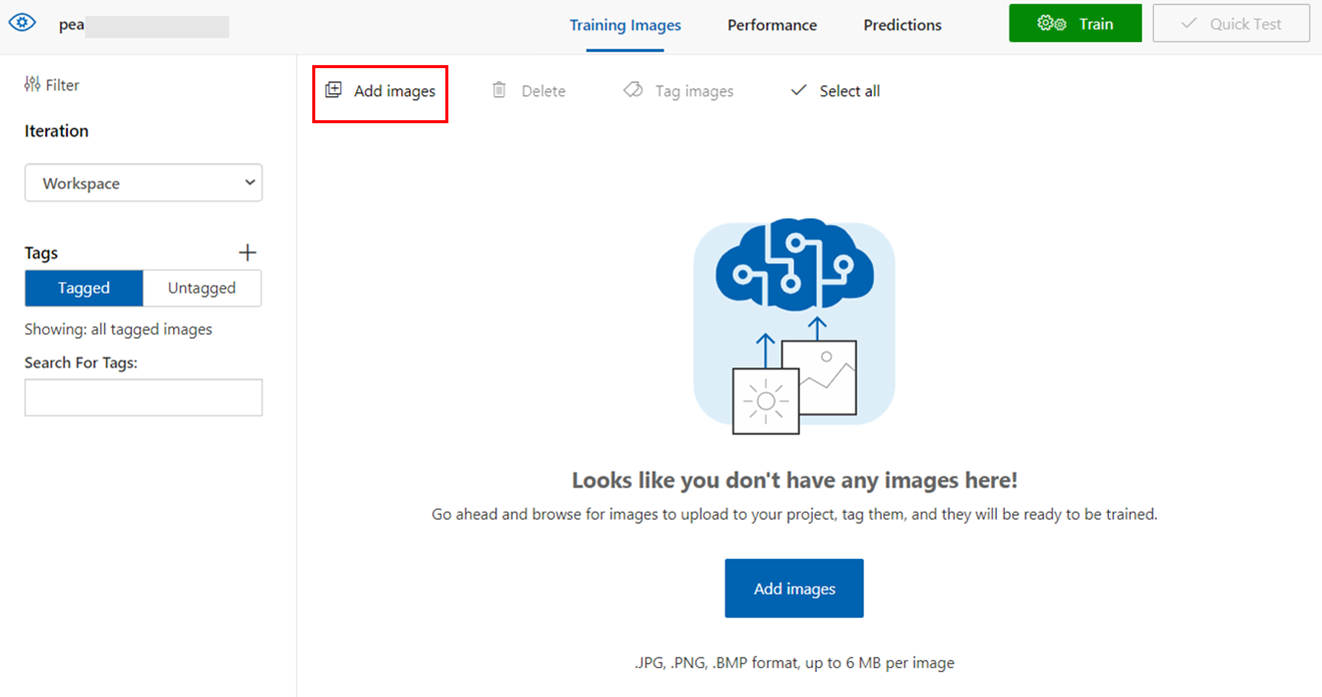
選択した画像に付与したいタグを入力します。現状Custom Visionポータルは英語のみの表示になっていますが、タグには日本語も利用可能です。ここではさやえんどうの画像を選択しているので、タグも「さやえんどう」と日本語で入力しています。
登録したい画像枚数が正しいことを確認し「Upload files」をクリック。
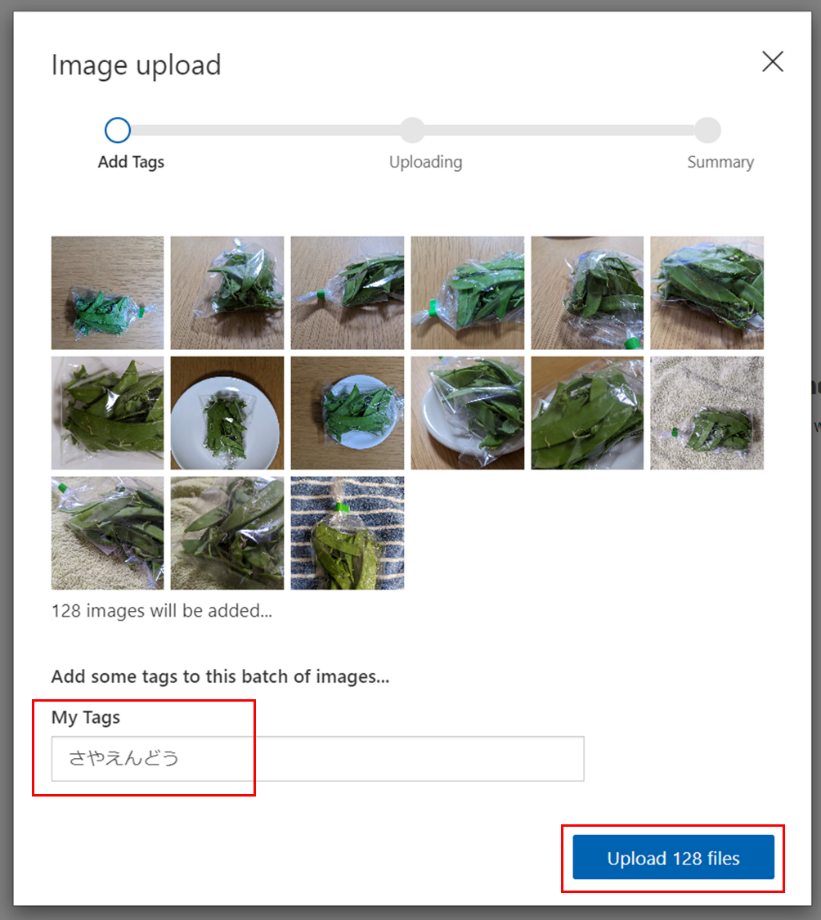
「Done」をクリックして画像の登録が完了です。
同様の手順で、その他の画像とタグ(スナップえんどうとさやいんげん)も登録していきます。
画像とタグが登録できたら、これらを使用してモデルのトレーニングを行います!
Custom Visionポータル右上の「Train」をクリック。
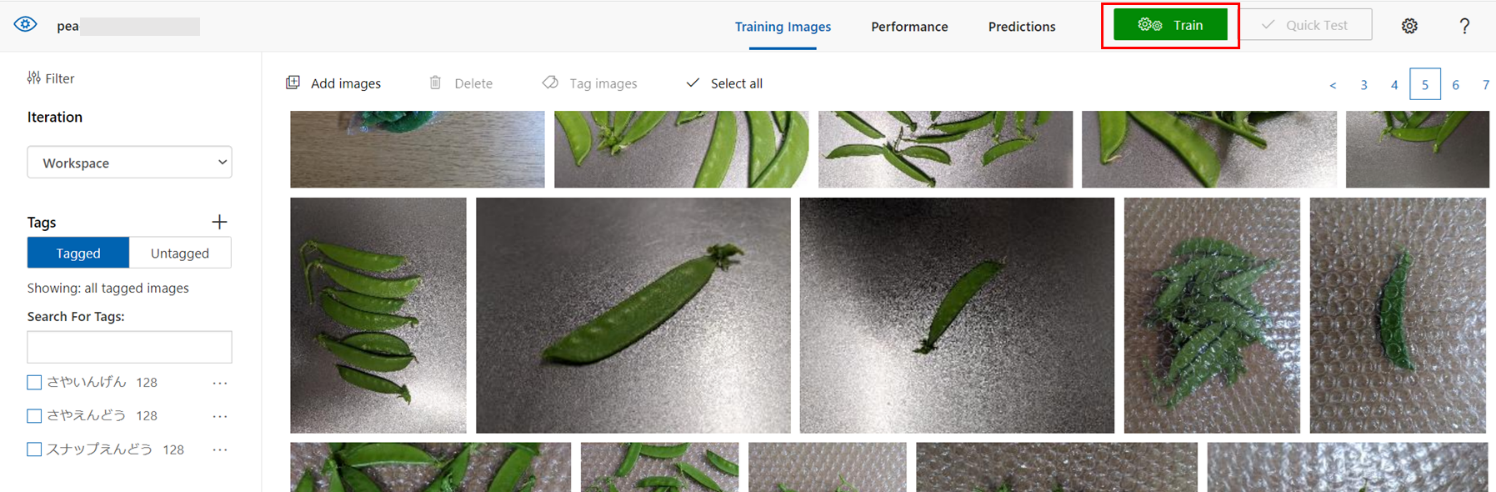
トレーニングタイプの選択画面が表示されます。ここでは「Quick Training」を選択しました。「Train」をクリックすると、トレーニングが開始されます。
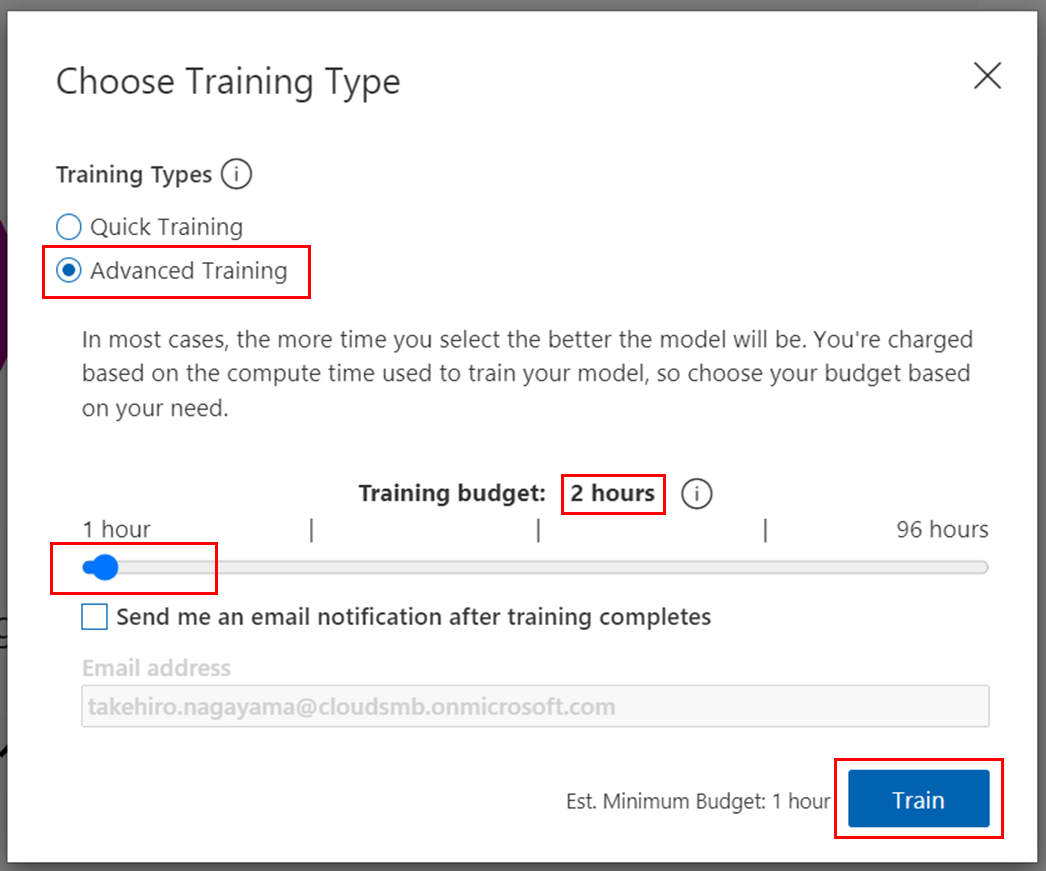
トレーニングタイプ「Advanced Training」では、学習時間を1~96時間で指定して長期的な学習が可能です。(Quick Trainingよりも精度が高くなることが多く、本コラム後半でも試していますので、後ほどお話します)
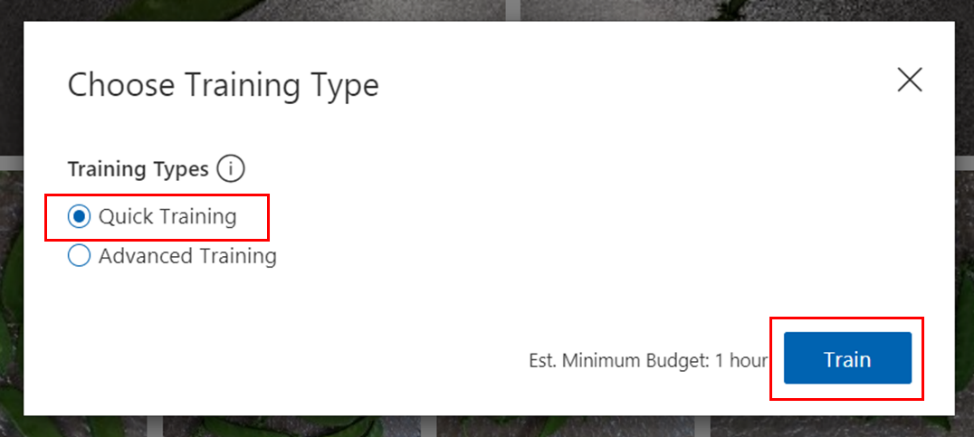
トレーニングが完了すると、「Performance」タブに以下のようなトレーニング結果が表示されます。
Iterationは学習工程のことを示しており、Iteration 1は1回目の学習を意味しています。画像を追加して再度学習したり、学習時間の長さを変えて学習したりすると、Iterationの数字が増えたものが画面左のリストに追加されていきます。
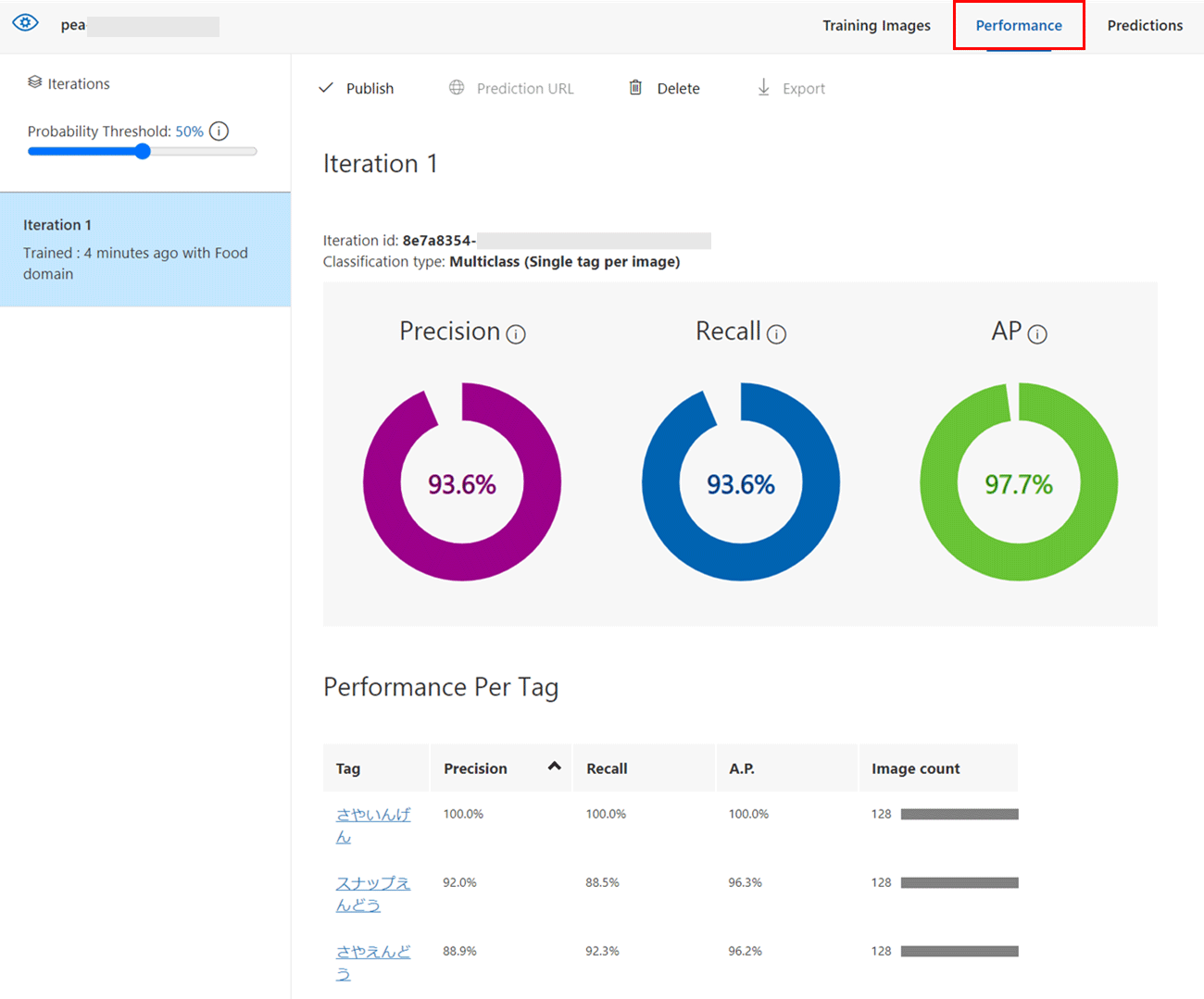
画面左上の「Probability Threshold」は、モデルが対象の画像が何の画像かを判断する閾値を示しています。ある画像を識別するとき、モデルはその画像が何を示しているかを確率で出力し、その確率が閾値以上である場合に、「〇〇である」と判断します。
例として、モデルの出力が以下で、閾値を50%とした場合、「さやえんどう」と識別されます。
閾値を上げると、以下で説明する精度が向上する一方で、再現性は低下する傾向にあります。
上記画像のトレーニング結果には、3つの数値とグラフが表示されています。
Precision(精度)は、識別された画像うち正しく識別できている画像の割合です。例として、モデルによって100枚の画像が「さやえんどう」として識別され、そのうち94枚が実際に「さやえんどう」であった場合、精度は94%です。
Recall(再現性)は、画像全体のうち正しく識別ができた画像の割合を示します。 例として、実際に「さやえんどう」である画像が100枚あり、モデルによって94枚が「さやえんどう」として識別された場合、再現率は94%です。
AP(Average Precision、平均精度)は、異なる閾値での精度と再現率をまとめた、モデルの性能を表す指標です。
それではトレーニングしたモデルをテストしてみましょう!
画面右上の「Quick Test」をクリック。

「Browse local files」から、事前にテスト用に準備していた画像を選択します。
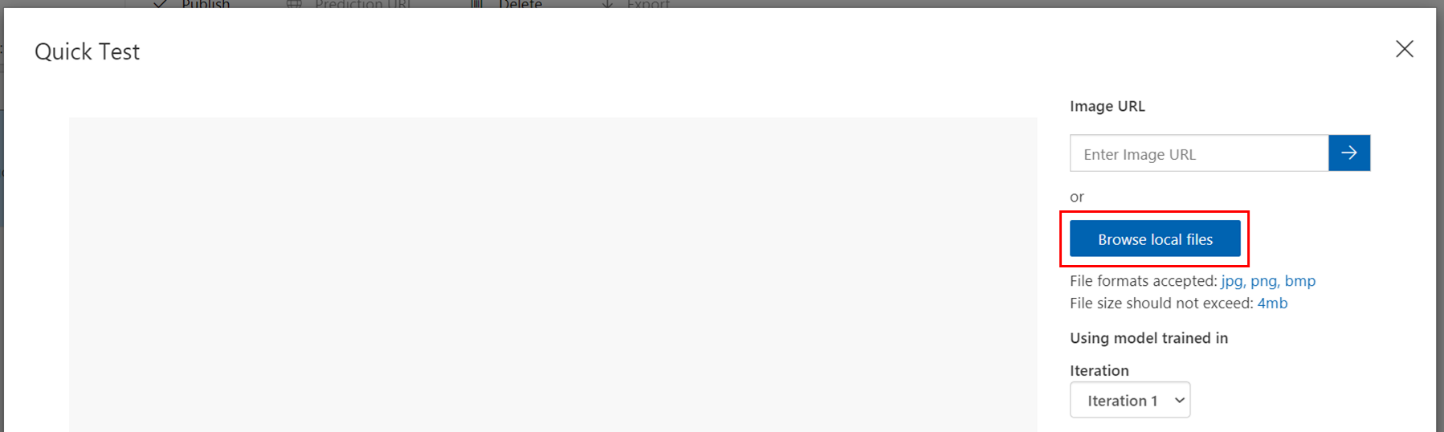
今回はテスト画像を合計30枚準備していますので、いくつかの結果を見てみましょう。
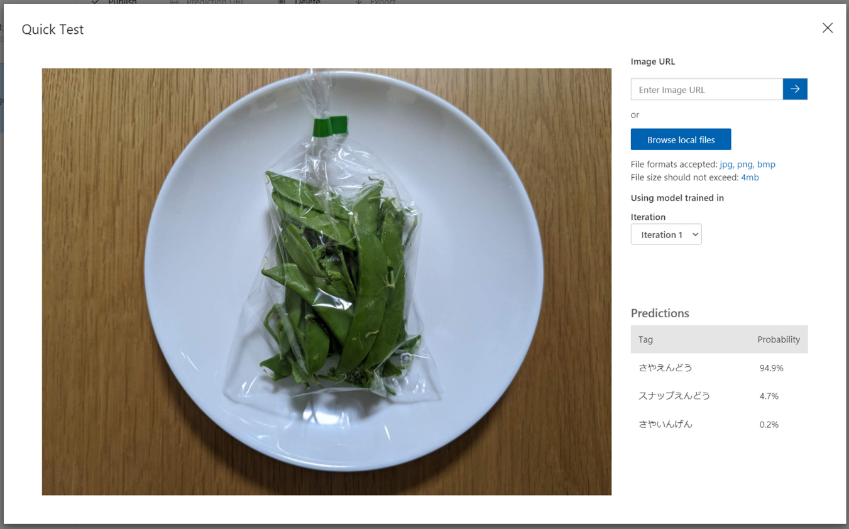
【ビニール袋に入っている、さやえんどう】の画像。AIは94.9%の確立でさやえんどうと言っています。正解!
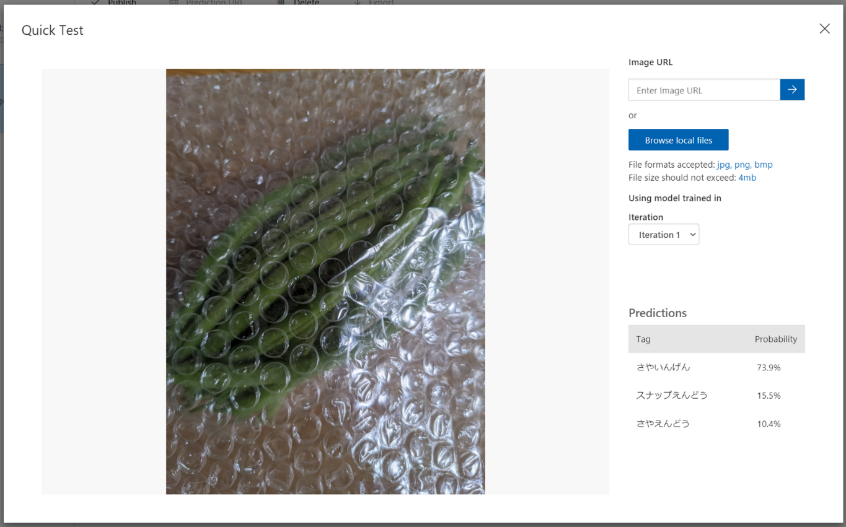
【緩衝材に入れた、さやいんげん】の画像。確率73.9%と先ほどより自信がないようですが、正解!
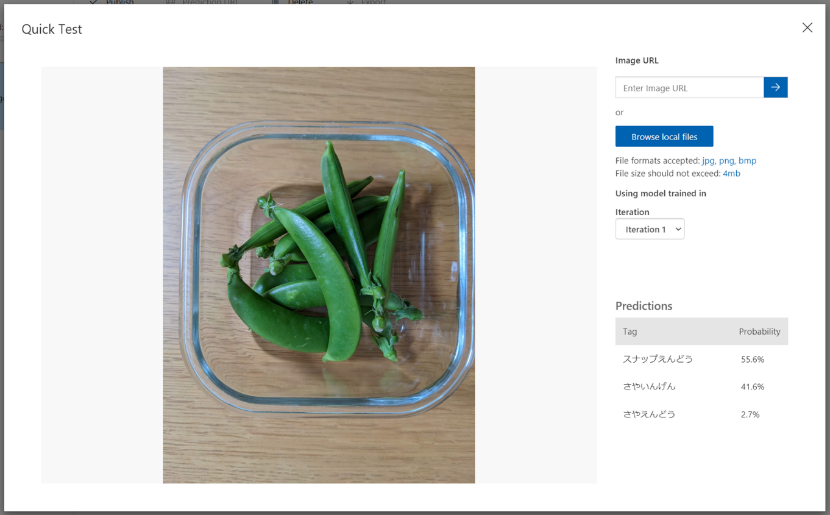
【ガラス容器に入れた、スナップえんどう】の画像。正解!なのですが、確率55.6%と、さらに自信がないようです。
残りのテスト用画像でもテストをしてみたのですが、確率が低いものがいくつかありました。改善したいですよね。
そこで、学習時間を増やすことでの改善を期待して、前述の「Advanced Training」を使用して学習時間を2時間としてトレーニングを行いました。
実際にはトレーニング開始から30分も経たずにトレーニングが完了しました。
トレーニング結果がこちらです。Iterationが2に増えています。
トレーニングに使用している画像は同じですが、前回の「Quick Test」と比較すると、どの評価指標とも高くなっていることがわかります。これは期待できますね!
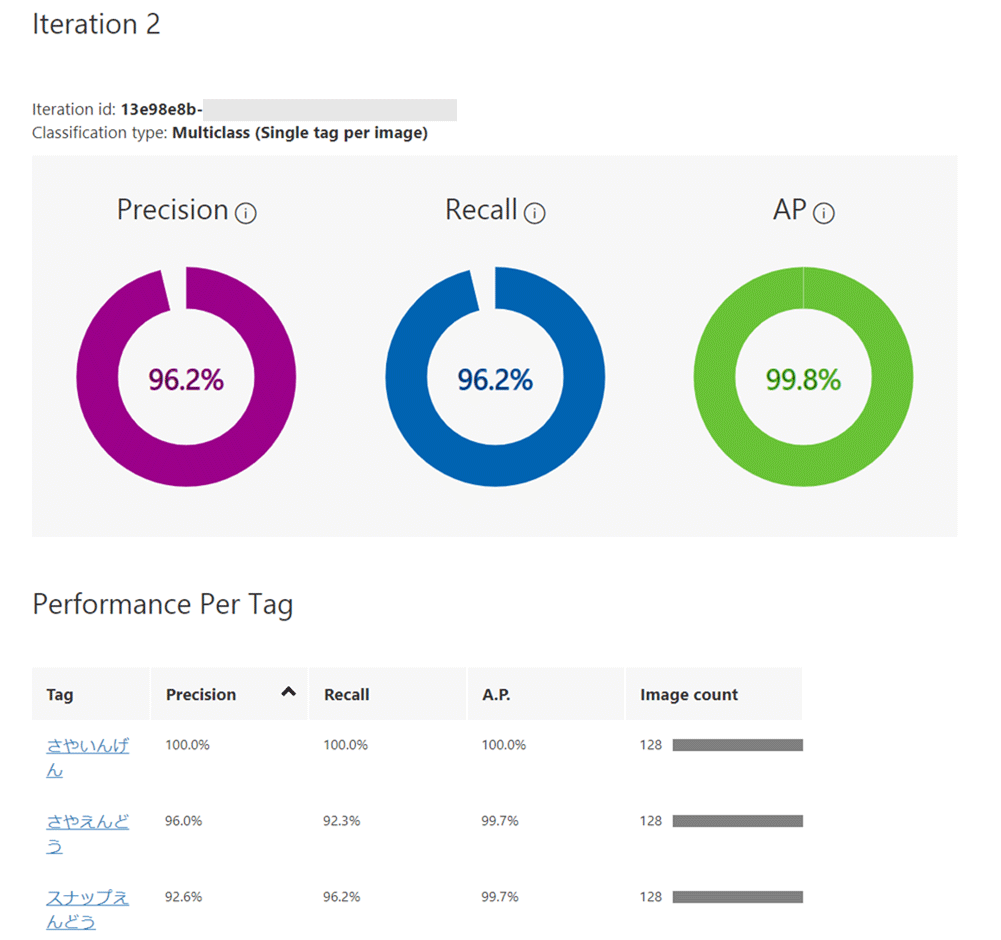
それでは、さきほどのテストで確率が低く自信なさそうだった、【ガラス容器に入った、スナップえんどう】の画像を使って、このモデルのテストをしてみます。
結果は如何に・・・・
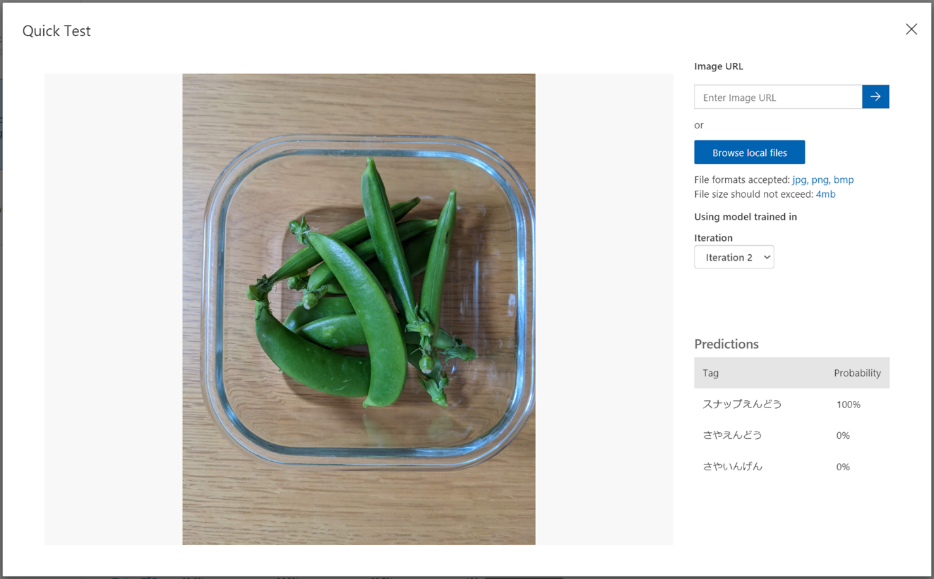
なんと、スナップえんどう100%!素晴らしい!
モデルがかなり改善されていることがわかりました。
今回の「えんどう識別アプリ」ではこのモデル(Iteration 2)を採用したいと思います。
モデルの作成が完了したので、Power Appsからこのモデルを利用できるように予測APIとして発行していきます。
「Performance」タブで対象のIterationを選択して、「Publish」をクリック。

予測リソースとして、手順3で作成した予測リソースを選択し、「Publish」をクリック
対象のIterationに「PUBLISHED」のマークが表示されます。
これで発行完了です!!

以上で今回のえんどう識別アプリに必要なCognitive Servicesの作業が完了です。
今回は画像を識別するためのモデルを、Cognitive ServicesのCustom Visionを使って作成しました。
モデル作成自体は専門知識がなくてもポータル内でポチポチとクリックしていくだけで、とても簡単なのがおわかりいただけたのではないでしょうか。学習時間を増やすことでモデルの性能が向上するところも見られて面白いですね。
次回はPower Appsを使って、今回のモデルをスマートフォンで簡単に利用できるようにアプリを作成します。お楽しみに!
Microsoft Azure、Azure Cognitive Services、Microsoft Power Apps は、Microsoft Corporationの米国及びその他の国における登録商標または商標です。






相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

