
AWS Key Management Service(KMS)とは?仕組みや使い方を解説
本コラムでは、AWSが提供する鍵管理サービスであるAWS KMSの役割と仕組み、使い方について解説します。
![]()


Amazon S3の構築や運用について、NTT東日本では、クラウド導入・運用サービスで貴社システムをサポートいたします。クラウド導入・運用サービスの提供機能や料金など詳しく記載したサービス資料をぜひダウンロードください。
Amazon Simple Storage Service (以下S3とします。)はAmazon Web Services(以下AWSとします。)で利用できる容量無制限のストレージサービスです。
当コラムではS3の概要や利用方法の説明、コンソールを使用した実際の方法などを説明します。
また、こちらのコラム「Amazon S3をどう使うか-容量無制限の優れたストレージサービス」では、S3のメリット、主な使い方、料金を解説していますので、合わせてご確認ください。

AWSとは、Amazon Web Servicesの略でAmazonが提供しているクラウドサービスの総称です。
世界各国で利用されており、クラウドサービスのなかでもトップクラスの高い人気を誇っています。
AWSの概要や具体的にできることなどについては以下のコラムで紹介しています。
是非ご確認ください。
S3とはデータを格納・管理できるオブジェクトストレージサービスです。
主にウェブサイトやアプリケーションなどのデータバックアップおよび復元、アーカイブなど、さまざまなことに利用します。
また、ファイルのバックアップ、ファイル処理の加工前、あるいは加工後のファイルの保存、動画・画像ファイルやCSSなどWebで使う静的なファイルをS3に置いて配信するなど、非常に広範囲な使い方ができます。
リンク:Amazon S3![]()
以下のようなメリットがあります。
高い可用性や耐久性
利用するストレージリソースを自由にスケールアップ・ダウンすることができます。
保存したデータを自動的に3つのデータセンターに複製し、99.999999999%の高いデータ耐久性を実現します。そのため、万一の障害やエラー、脅威などからデータを保護することができます。
コストを意識した利用が可能な従量課金制
従量課金制で、「ストレージ容量」「リクエスト数」「データ転送量」といった使用量に応じて料金が算出されるため、コストを意識した利用が可能となります。
詳細な料金表については公式サイトのAmazon S3 の料金![]() をご確認ください。
をご確認ください。
機能ストレージクラス分析を利用することで、保存されたデータのアクセスパターン等をチェックし、低コストのストレージに移動するべきデータを知ることができます。
一定時間たったら削除するなどの設定も行えるので、膨大なデータを効率よく利用できるようになります。
容量無制限
容量制限が無く、データをいくらでもアップロードできる非常に大きなメリットがあります。
※保存するデータは1ファイルにつき5TBまでという制限はあります。
ストレージの残容量を気にすることなく、いくらでもクラウドにデータを保存できますので、使用しているコンピュータはもちろん、複数のデバイスにデータを分けて蓄積するといったことに手間などをかける必要がありません。
他にもメリットがあり、以下のコラムで紹介しています。
S3の利用方法としては、以下があります。
バックアップと復元
S3とAWSの他のサービス(例:S3 Glacier、Amazon EFS、Amazon EBS)を使用することで、スケーラブルで、耐久性、安全性に優れたバックアップと復元を行うことができます。
クラウドにある既存のデータをバックアップしたり、AWS Storage Gatewayを使用して、オンプレミスデータのバックアップを AWS に自動的に送信したりすることができます。
BCP(事業継続計画)
S3を活用しAWSやオンプレミス環境で実行されている重要なデータ、アプリケーション、IT システムを保護できます。そのため、予備の物理データセンターにコストをかける必要がなくなります。
バックアップをS3に取っておくことにより、自然災害やシステム障害、人為的ミスによって発生する機能停止から簡単にすばやく復旧することができるため、BCP(Business Continuity Plan:事業継続計画)の対策として利用できます。
アーカイブ
取り出すことのないデータの長期保存が目的の場合はS3 GlacierとS3 Glacier Deep Archiveの利用が最適です。データをアーカイブし、データを長期間、低コストで保持することができます。価格はS3とGlacierで異なり、S3は1GBあたり約10円、Glacierでは1GBあたり約1円となり、約10分の1です。テープライブラリより遥かに高速に復元が可能で、S3 Glacier では迅速取り出しサービスを利用する場合は 1分、標準取り出しサービスを利用する場合は 3~5 時間でアーカイブデータを復元できます。S3 Glacierからの一括データ復元とS3 Glacier Deep Archiveを使用した復元はすべて 12 時間以内に完了できます。
データレイクとビッグデータの分析
S3でデータレイク(多数のソースからのビッグデータを元のままの多様な形式で保持するストレージリポジトリ)を作成できます。多数のAWS分析アプリケーション(Athena、EMR、Glueなど)はS3 のデータレイクのデータにアクセス可能です。データレイクのデータはビッグデータの分析に活用できます。
ハイブリッドクラウドストレージ
AWS Storage Gatewayを利用することでオンプレミスにあるストレージとS3のストレージをシームレスに接続することができます。また、AWS DataSyncを使用することで、オンプレミスストレージとS3の間のデータ転送を自動化して障害に備えることができます。AWS Transfer for SFTP(サードパーティーとの安全なファイル交換を可能にする完全マネージド型サービス) を使用してS3間でファイルを直接転送することも可能です。
こちらのコラムではファイルサーバーとしてS3を利用しています。是非ご確認ください。
S3のコンソールの使用方法を説明します。
以下は作業手順です。
---
---
バケットを作成
S3マネジメントコンソール(https://aws.amazon.com/jp/s3)でバケットを作成します。
※作成後はバケットの名前、リージョンは変更不可です。
バケット名に「test-kenshou」と入力します。
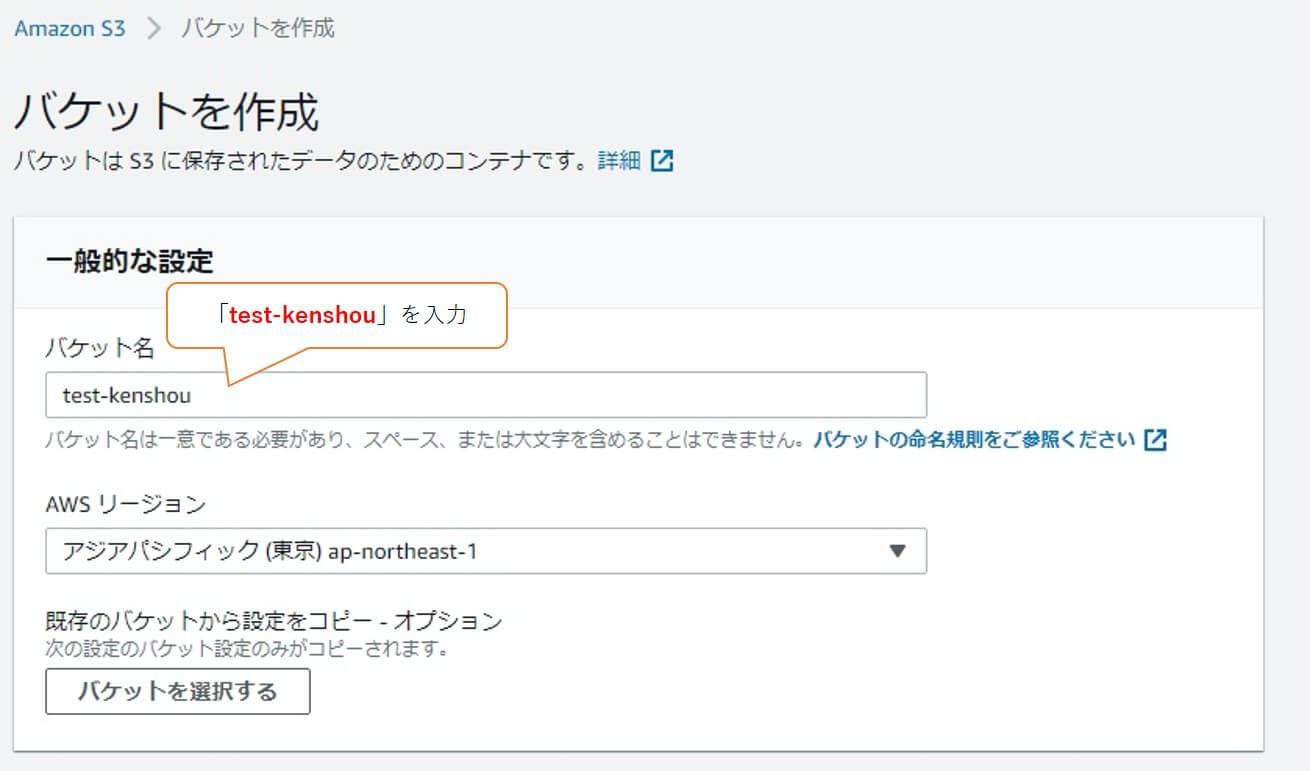
他の設定はデフォルトのまま下部の「バケットを作成」をクリックします。
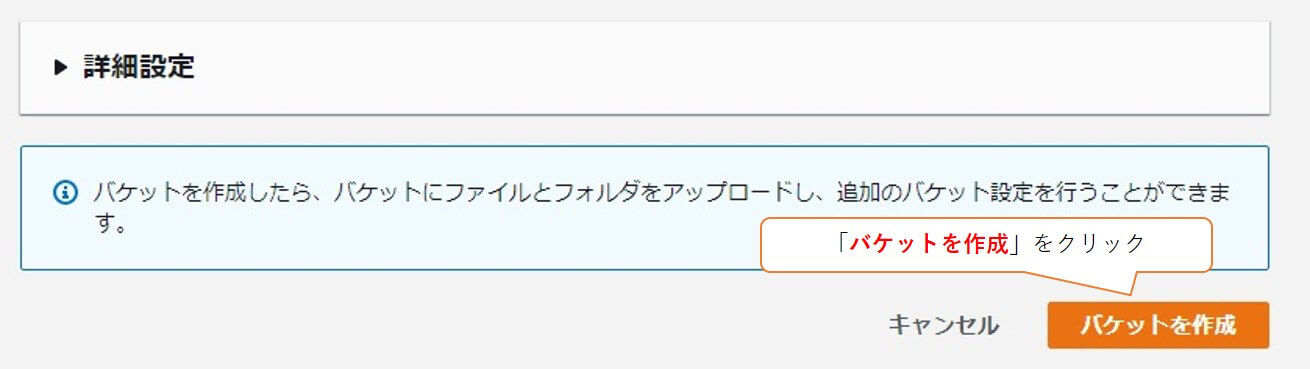
上部に「~が正常に作成されました」と表示され、作成完了です。

ファイルのアップロード
さきほど作成したバケットへ「ファイル、フォルダのアップロード」を行います。
バケットへ移動するため、検索欄に「test-kenshou」を入力します。
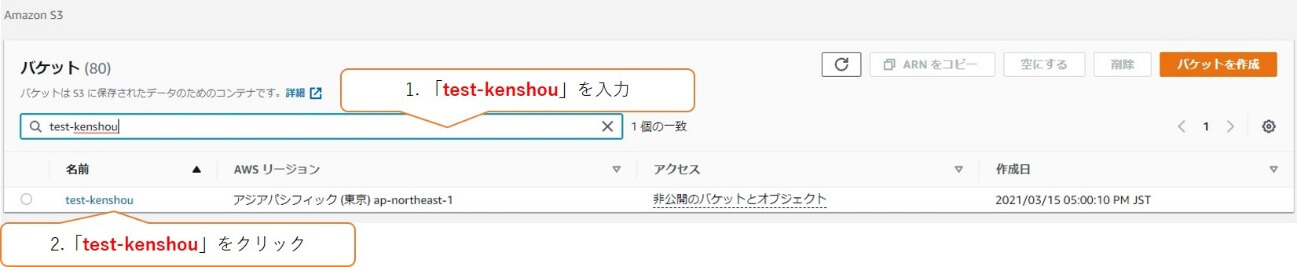
「アップロード」をクリックします。
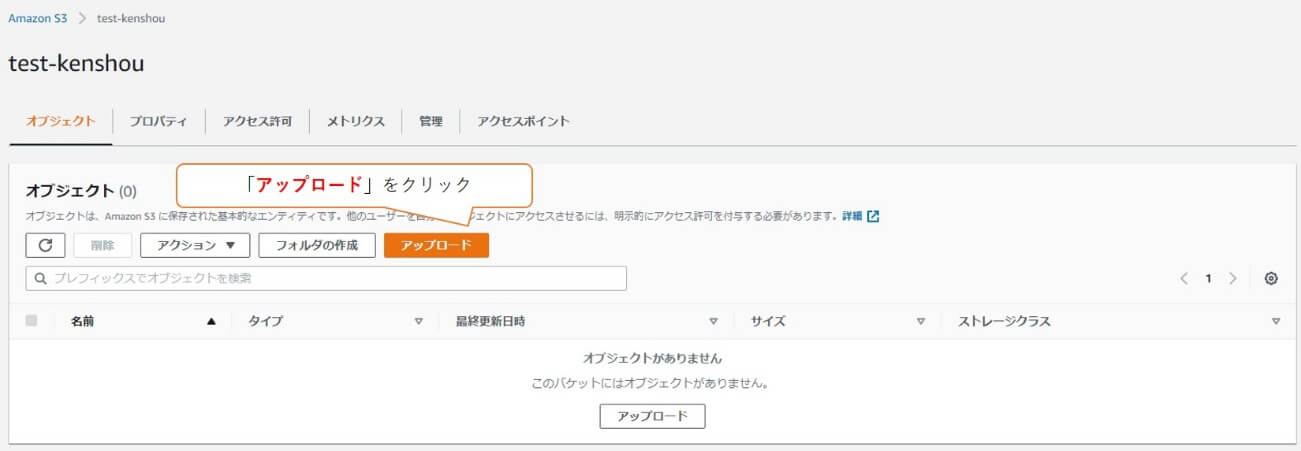
次に、ファイルやフォルダをアップロードしていきます。
アップロードの方法として、画面へ直接ファイルやフォルダを「ドラッグアンドドロップ」する、「ファイルを追加」または「フォルダの追加」からファイルやフォルダを選択するがあります。
今回は「ファイルを追加」でアップロードします。「ファイルを追加」をクリックします。
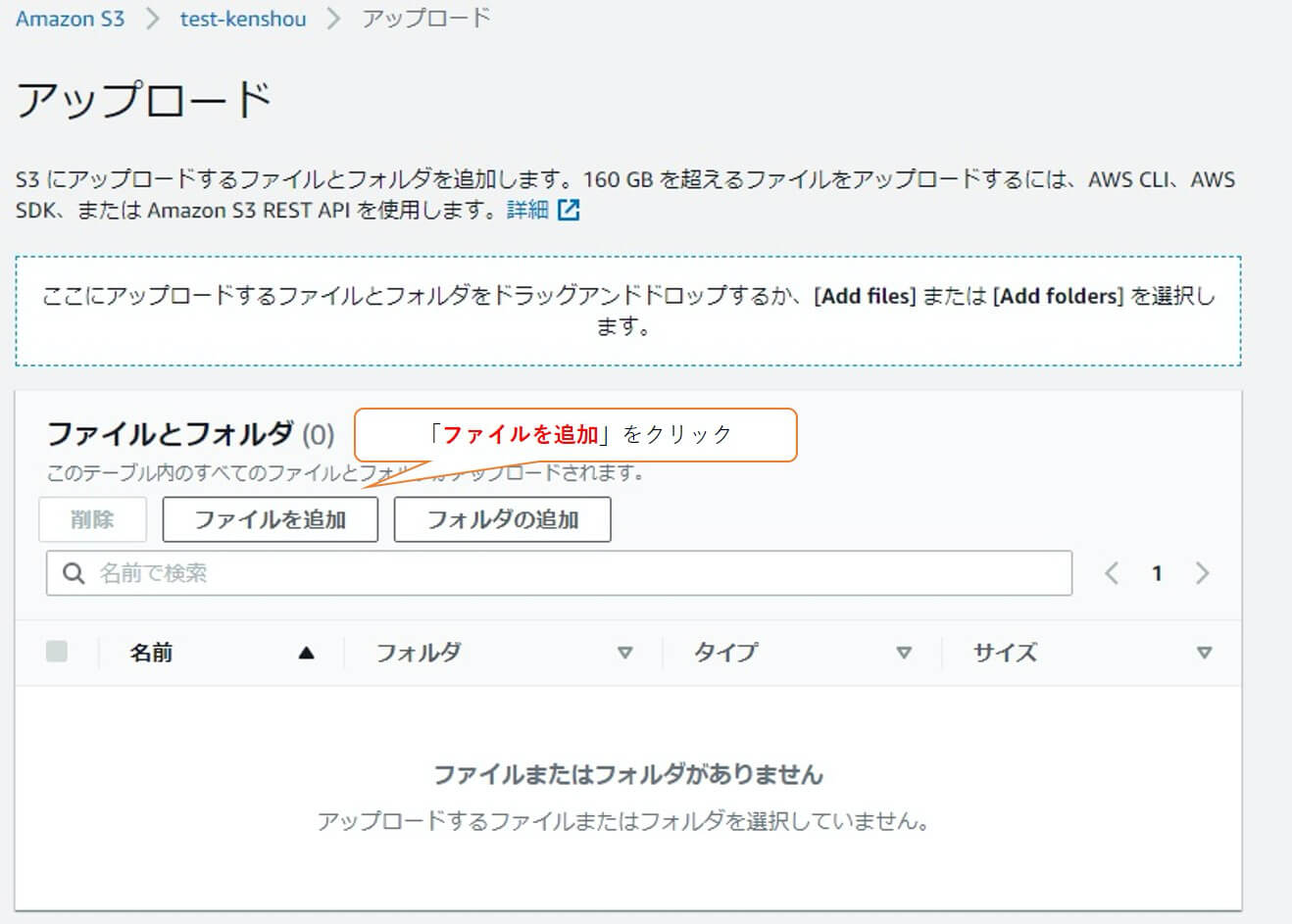
アップロードするファイル「test.txt」を選択し、「開く」をクリックします。
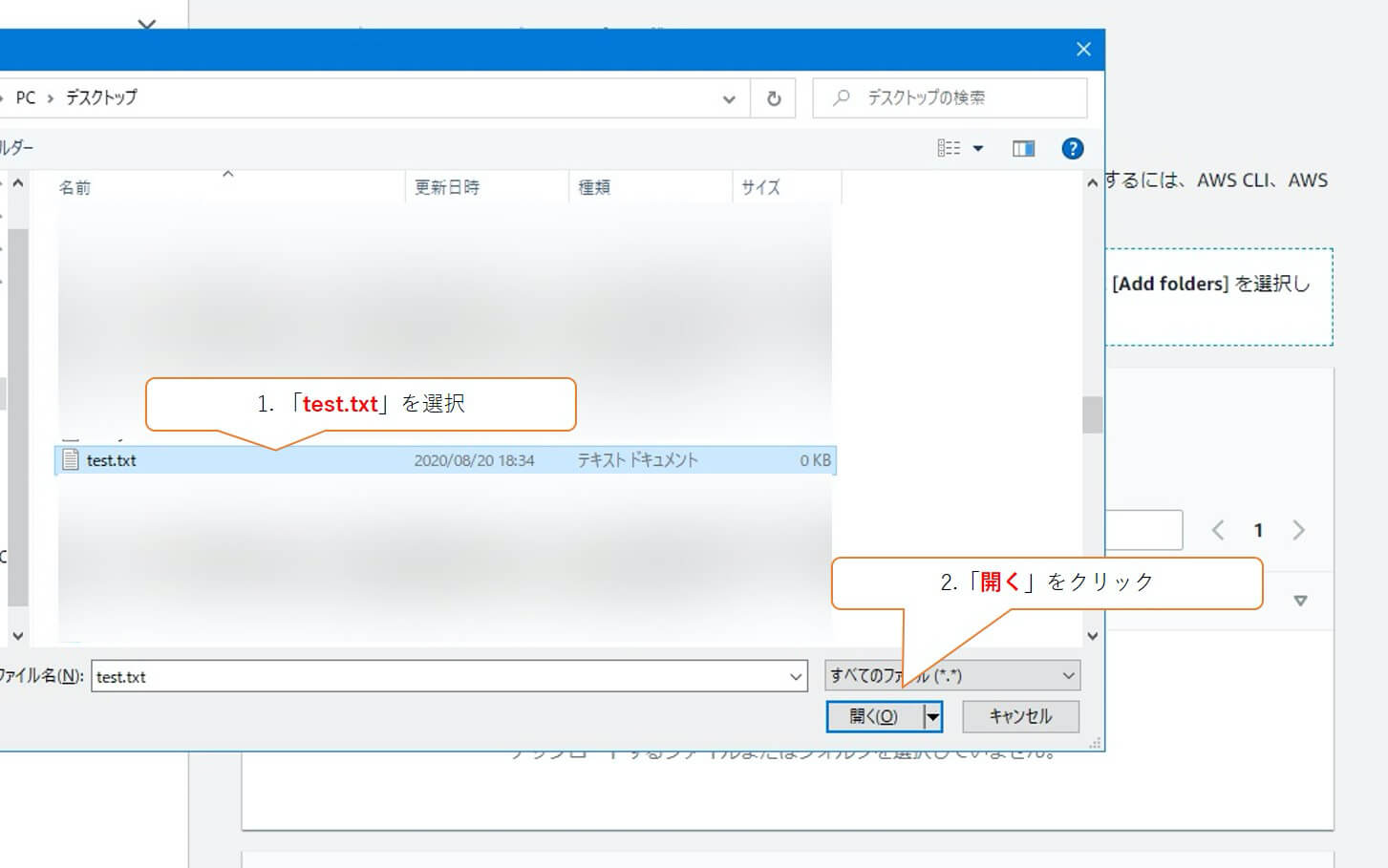
ファイル名が表示されたら、「アップロード」をクリックします。
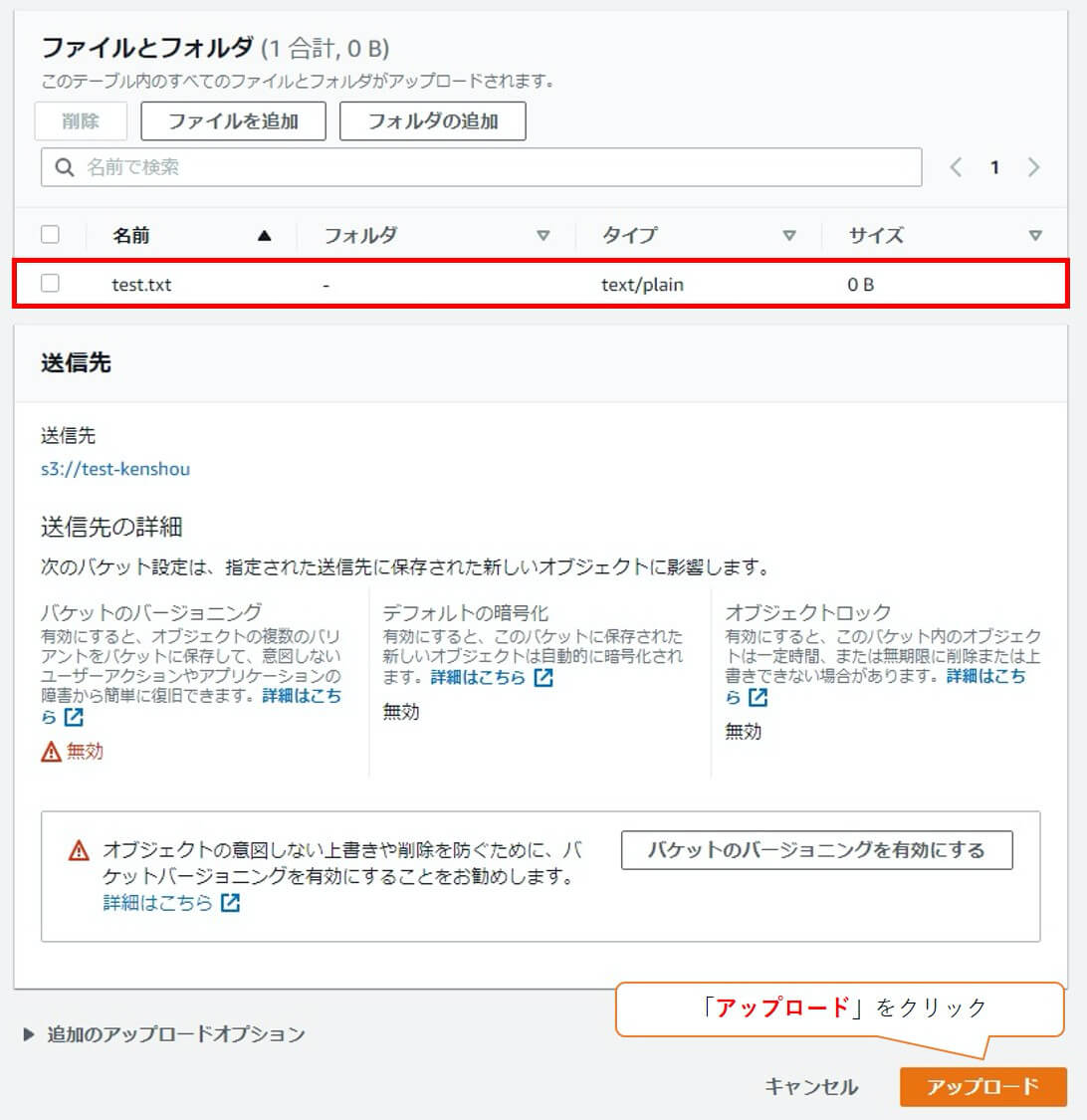
ステータスに「成功しました」と表示されれば、アップロードは完了です。
ファイルのダウンロード
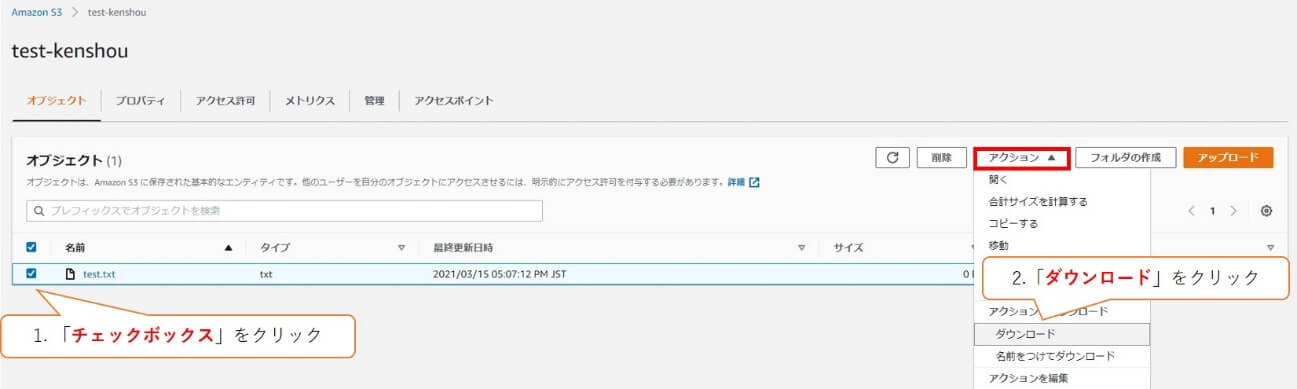
次は、バケットにアップロードされているファイルをダウンロードしていきます。
ダウンロードするファイル「test.txt」を選択し、「アクション」のメニューから「ダウンロード」をクリックします。
ファイルの削除
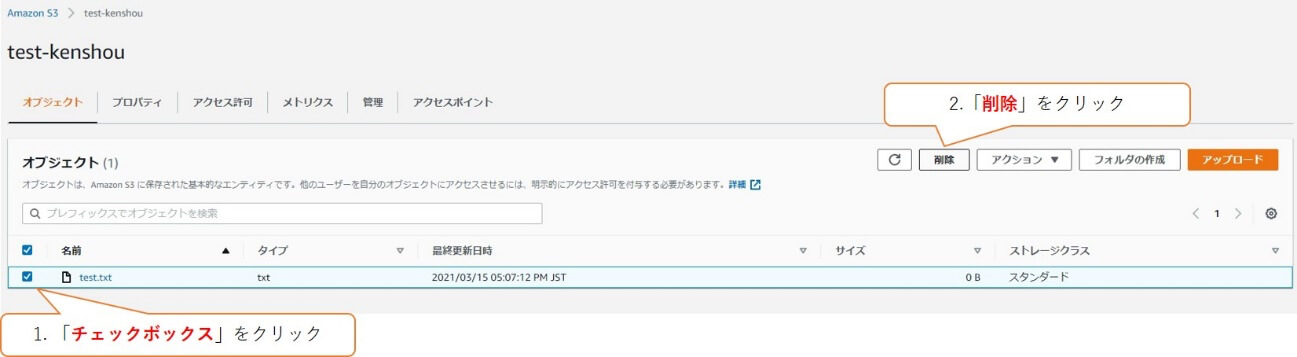
バケットにアップロードされたファイルを削除していきます。
削除するファイル「test.txt」を選択し、「削除」をクリックします。
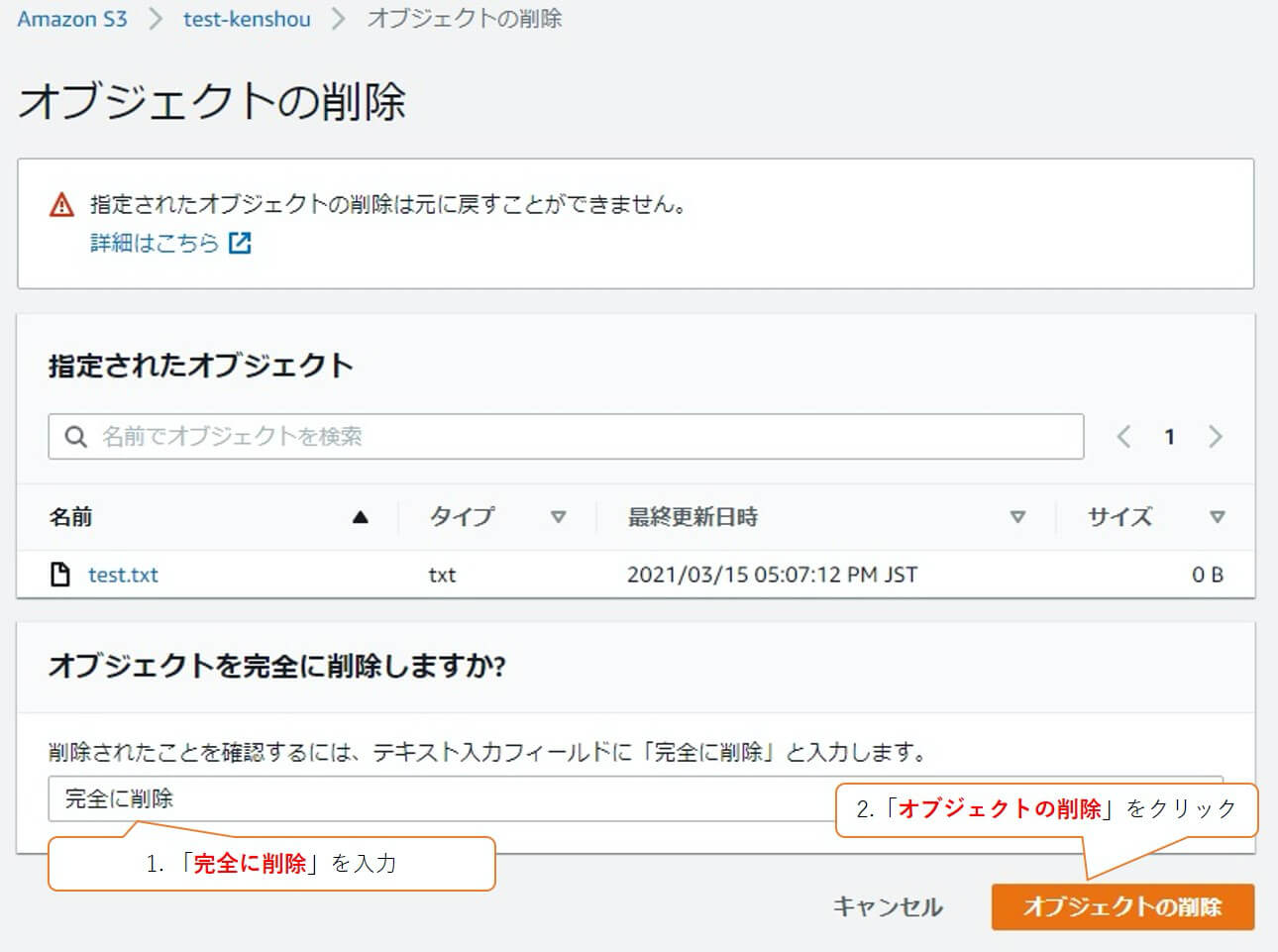
テキスト入力フィールドに「完全に削除」と入力し、「オブジェクトの削除」をクリックします。
※「完全に削除」を入力しない場合、削除されません。
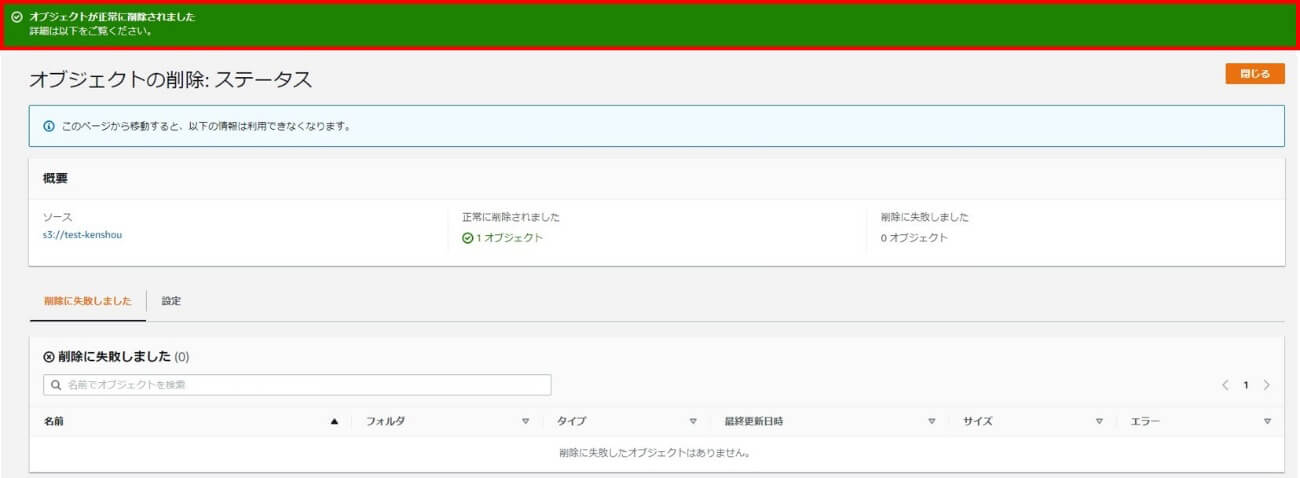
画面上部に「オブジェクトが正常に削除されました」と表示されれば、削除完了です。
バケットの削除
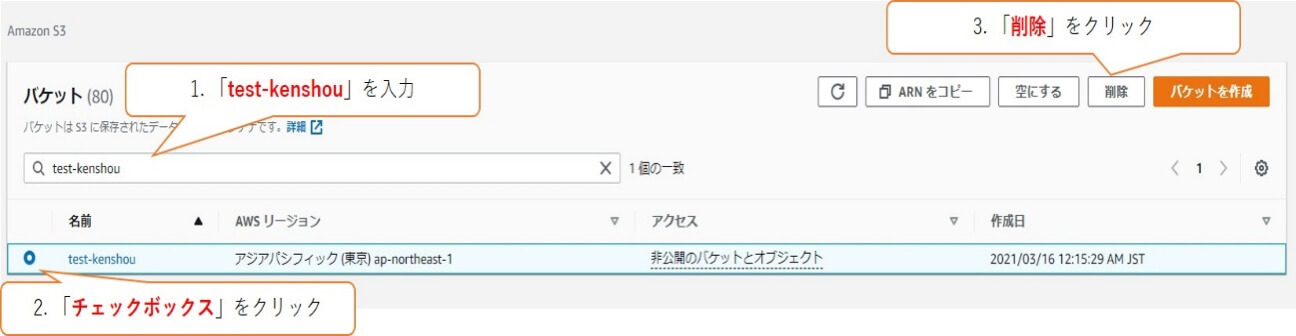
バケットを削除する方法を解説します。検索欄に「test-kenshou」を入力します。
削除するバケット「test-kenshou」を選択し、削除をクリックします。
「test-kenshou」と入力し、「バケットを削除」をクリックします。
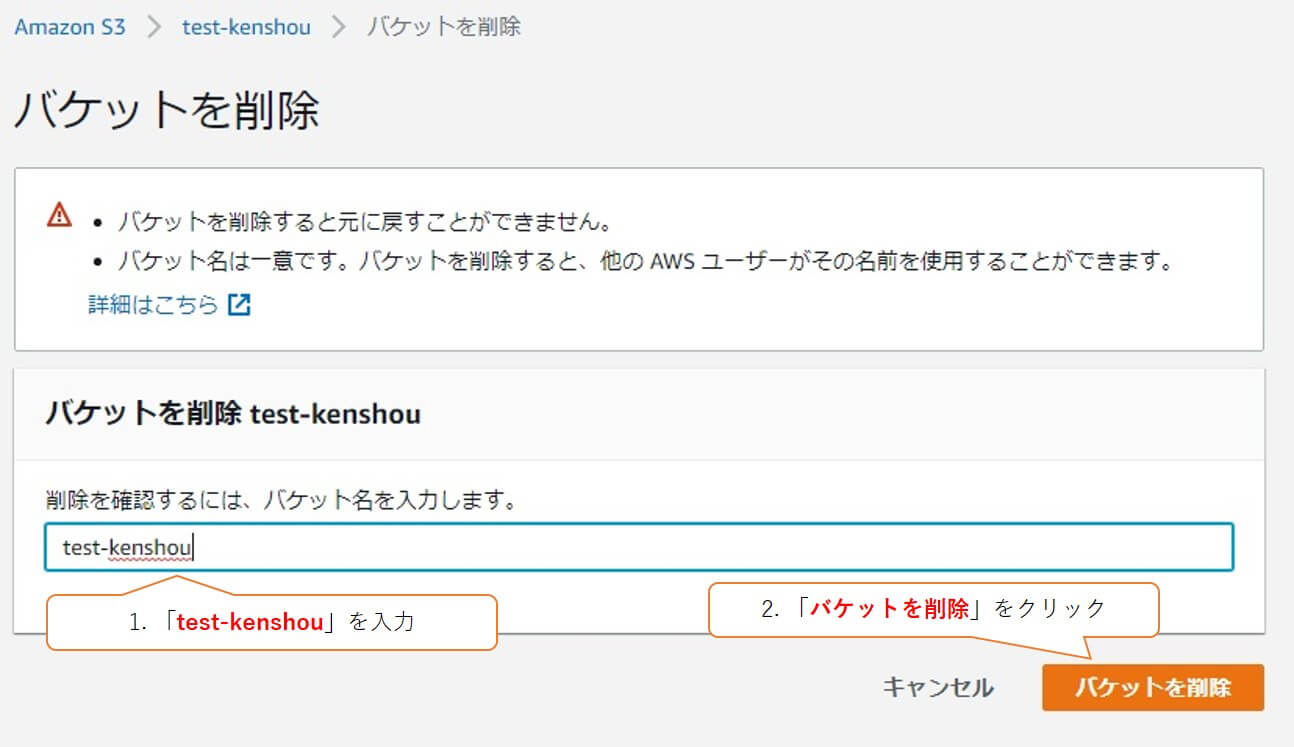
上部に「正常に削除されました」と表示されれば、削除完了です。

S3のコンソールの使用方法の説明は以上です。
S3ではデータを安全に無制限に保存できるだけでなく、データの分析や保管に使うなどさまざまな利用方法があります。AWSには1年間無料で使える無償枠もありますので、お試しで利用してみてはいかがでしょうか。
Amazon S3の構築や運用について、NTT東日本では、クラウド導入・運用サービスで貴社システムをサポートいたします。クラウド導入・運用サービスの提供機能や料金など詳しく記載したサービス資料をぜひダウンロードください。





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


