
AWSで利用可能なWindows系サービス
AWSで利用可能なWindows系サービスについて紹介すると共に、Amazon EC2でWindows Serverインスタンスを起動してアクセスする方法について紹介します。
![]()


社内のさまざまな領域でデジタル化が加速するのに伴い、システムの可用性に対する要求が高まっています。
特に、基幹システムのようにシステムの停止が事業運営に多大な影響を及ぼす場合、システムの可用性を維持することはとりわけ重要となります。
Amazon Web Services (AWS)をはじめとする主要なクラウド事業者は、クラウド上で構築・運用されるシステムの可用性を高めるためのベストプラクティスに関する情報や、ベストプラクティスの実践をサポートするためのサービスを提供しています。
このコラムでは可用性について基礎的な知識を解説すると共に、クラウド上で構築・運用されるシステムの可用性を高めるための方法を紹介します。

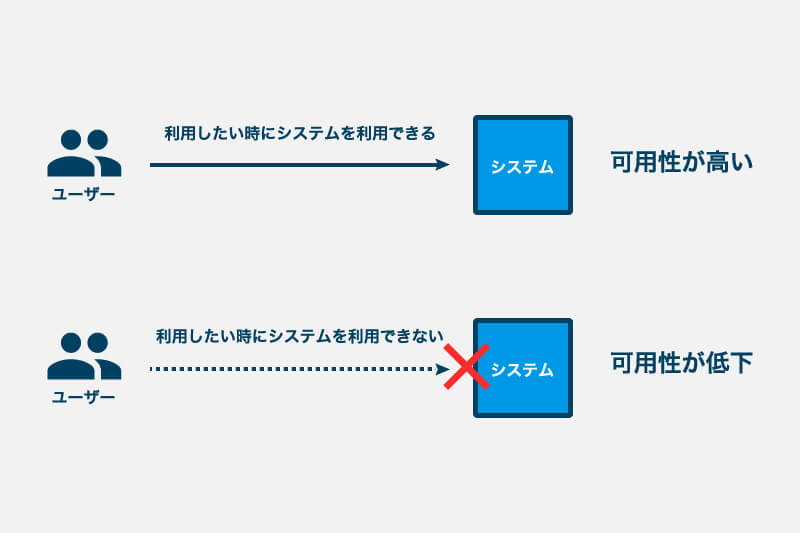
可用性は、システムが利用可能な状態を維持する能力を意味する言葉として用いられます。
ユーザーの観点からは、利用したいときにシステムを利用できる度合いと考えることもできます。
システムが利用できる時間が長いほど、システムの可用性は高くなります。
逆に、障害などが原因でシステムが停止した場合、システムが復旧するまでの間はシステムを利用できないため、システムの可用性は低下します。
可用性を評価するための指標としては、次に解説する「稼動率」がよく用いられます。
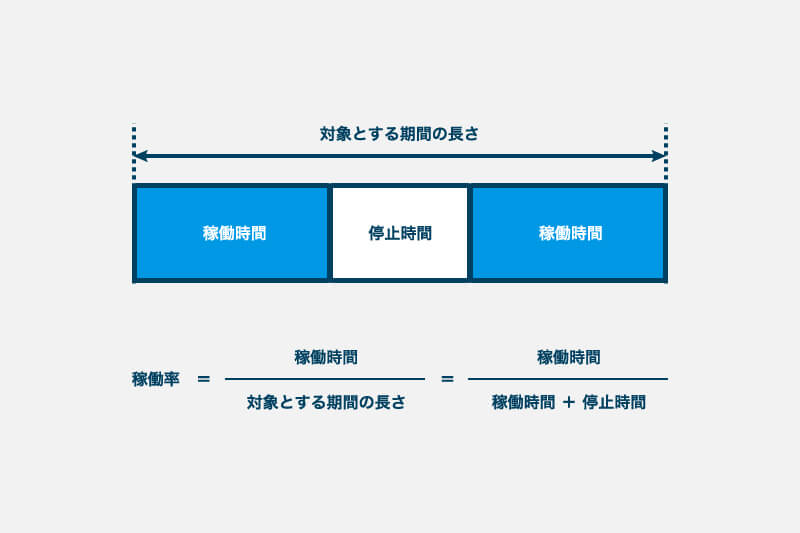
稼動率は、対象とする期間においてシステムが稼動 = 利用可能な状態を維持していた時間の割合を意味する言葉として用いられ、システムの稼動時間 ÷ 対象とする期間の長さで算出されます。
また、対象とする期間の長さはシステムの稼動時間と停止時間の和に等しいため、システムの稼動時間 ÷ (システムの稼動時間 + システムの停止時間)で稼動率を算出することもできます。
稼動率の単位にはパーセント(%)が用いられ、システムの稼動時間が長いほど、稼動率は100%に近づきます。
システムやサービスの稼動率として、例えば「99%」や「99.9%」と表記すると一見高そうに感じられますが、1年単位で考える場合は停止時間が87時間以下であれば稼動率99%を達成することができ、停止時間が8時間以下であれば稼動率99.9%を達成することができます。
なお、稼動率から停止時間を計算したい場合は、対象とする期間の長さと(1 - 稼動率)の積として停止時間を算出することができます。
稼動率は過去の実績に基づく指標であり、システムやサービスの可用性を評価する上で有用ですが、過去の稼動率から未来の稼動率を推測することは困難です。
そこで、次に解説する「SLA」が重要となります。
サービス水準合意(service level agreement: SLA)は、システムやサービスの提供者と利用者の間でサービス水準に関する合意形成を図るために結ばれる合意を意味する言葉として用いられます。
前に解説した稼動率は、クラウドサービスのサービス水準としてよく用いられる指標の一つであり、クラウド事業者は目標とする稼動率を上回るように最善の努力を尽くします。
SLAには、ある期間において目標とするサービス水準を達成できなかった場合に、その期間のサービス利用料の減額や返金など、ペナルティに関する規定が含まれることもあります。
クラウドサービスの利用者はシステムを計画・設計するにあたり、クラウド事業者によってSLAとして提示されるサービス水準を一つの基準として用いることができます。
AWSはWebサイトなどでサービス水準の引き上げを頻繁にアナウンスしています。
AWSがサービス水準を引き上げる背景として、オンプレミスで稼働している既存の基幹システムや勘定システムなどのクラウドへの移行を取り込みたい思惑があることが仮説の一つとして考えられます。
クラウドコンピューティングは技術のライフサイクルとしてはすでに成熟期にあり、これまでオンプレミスで構築・運用されていたこれらのシステムのクラウドへの移行が今後国内で増加することが予想されます。
移行先のクラウドを選定するにあたり、クラウド事業者が提示するサービス水準は重要な判断材料の一つであり、クラウド事業者が移行先として選ばれる見込みを高めるためにサービス水準を引き上げていることが推測されます。
前段では可用性、稼動率、SLAについて解説しました。
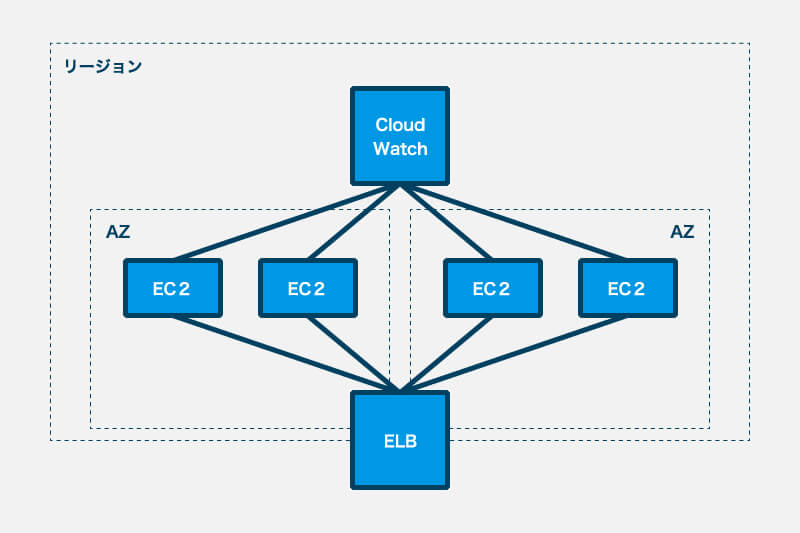
はじめに述べたように、クラウド事業者はクラウド上で構築・運用されるシステムの可用性を高めるためのベストプラクティスに関する情報や、ベストプラクティスの実践をサポートするためのサービスを提供しています。 以下、可用性を高めるための方法や、可用性を高めるために利用できるAWSのサービスを紹介します。上記の図を参考に読み進めてください。クラウドに限らず、可用性を高めるための常套手段としては「冗長化」が用いられます。
クラウドにおいては、例えばシステムを構成するための仮想マシンを複数起動しておくなどして冗長化を図ります。
しかしながら、特にバックアップを目的として複数の仮想マシンが作成された場合には、冗長化された仮想マシンはコスト削減の対象となりやすくいつでも削除される可能性があるため、どのようなタイミングで仮想マシンが削除されても正常に稼動し続けられるようにシステムを設計する必要があります。
設計の基本としては、ロードバランサーを配置して単一のエンドポイントを設け、エンドポイント経由で冗長化された仮想マシンにアクセスするなどし、直接アクセスすることは避けます。
AWSは負荷分散サービスとしてElastic Load Balancing (ELB)を提供しており、ELBによって提供されるロードバランサーのドメイン名を単一のエンドポイントとして利用することができます。
単一のエンドポイントの設置に加え、仮想マシンの稼動状態を監視し、異常が検出された仮想マシンを自動的に取り除くためのしくみを整えることが望まれます。
AWSは死活監視サービスとしてAmazon CloudWatchを提供しており、ELBのヘルスチェック機能や自動スケーリングサービスであるAuto Scalingと組み合わせることにより、異常と判断された仮想マシンを自動的に取り除くと共に、正常なインスタンスの数を保つことができます。
クラウド事業者はデータセンターを「リージョン」や「アベイラビリティーゾーン」(availability zone: AZ)と呼ばれる単位で分けて管理しています。
リージョンやAZはそれぞれ他のリージョンやAZから互いに独立しており、複数のリージョンやAZを使用してシステムを構築・運用することによって高い可用性を実現することができます。
一例として仮想マシンを複数起動する場合、複数のAZにわたって均等に仮想マシンを起動することにより、あるAZに障害が発生しても他のAZでカバーすることができるためシステムの停止を避けることができます。
マルチAZ構成については「AWSにおけるマルチAZの構成例」で詳しく解説していますので、興味のある方はぜひご一読ください。
クラウドの可用性はスケーラビリティーなど他の特徴と共に大きな魅力の一つです。基本をマスターすることで高い可用性を備えたシステムを計画・設計できるようになると、クラウドのメリットをさらに引き出すことができます。





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


