
Amazon Auroraとは?特徴やAmazon RDSとの違い
本コラムでは、Amazon Auroraの特徴、Amazon RDSとの違い(機能や料金)、使い方について解説します。
![]()


クラウド活用に関するさまざま情報をお届けするメルマガを毎週配信しておりますので、ぜひこの機会にご登録ください。
Amazon S3に格納されたデータを適宜分析するときに最適な「Amazon Athena」は、簡単に操作ができる便利な分析サービスです。一方、Amazon AthenaとRedshiftのどちらがよいのか分からず、うまく活用できるか不安な方もいるでしょう。
そこで、本記事ではAmazon Athenaの概要や使い方・メリットなどを解説します。この記事を読めば、自社でAmazon Athenaをすぐに活用できます。Amazon AthenaとRedshiftの違いについても触れていますので、導入検討をしている方はぜひ参考にしてください。

Amazon Athena(アマゾン アテナ)とは、AWSのデータ分析サービスのひとつです。
Amazon S3に格納されているデータを直接分析でき、簡単に操作できるのが特徴です。記述言語としてはSQLを使用しています。SQLはデータベース言語の中で最も普及しているため、既に知識があるシステムエンジニアが在籍していれば使い勝手も良いでしょう。
またサーバーレスのためセットアップも不要で、複数のクエリを同時に実行でき簡易的な分析に利用できます。
AWSでは、Amazon Athenaと同じような機能を持つサービスが他にもあり、データウェアハウスであるRedshiftもSQLを使用して分析が可能です。
RedshiftとAmazon Athenaの大きな違いは、リソースの割り当てを自動で行えるか手動で行えるかの違いでしょう。Amazon Athenaは自動でリソースを割り当てていきますが、Redshiftは手動でコントロールできます。そのためピーク時にAmazon Athenaは負荷がかかり遅くなる場合がありますが、Redshiftは安定性があります。
そのほかAmazon Athenaは、別リージョンにあるAmazon S3の分析・処理ができますが、Redshiftは同じリージョン内のAmazon S3しか対応していないのも違いです。
AWS Athenaを使うメリットは、以下の5点です。
AWS Athenaはサーバーレスで従量課金のため、コストの削減をしつつSQLを使用できます。結果、手軽に分析がしやすい点がメリットです。
またAmazon Athenaがクエリの実行でサポートしているのは、以下のデータ形式です。
上記のように、情報処理ができるデータの種類が豊富なため、さまざまなデータの分析に役立てられます。
情報セキュリティ対策に関しても、データ制御オプションが含まれており扱うデータも暗号化されているため、安心して使用できます。
Amazon Athenaは高速なデータツールである一方、クエリエンジンにPrestoを利用しているため使うべきケースが限られています。
スキャンデータに対しての従量課金のため、概念実証やプロトタイピングの段階などで色々なパターンの分析を手早く試したい場合に最適でしょう。
そのほか、データウェアハウスであるRedshiftにデータを保存するかの選定や、障害が起きたときの原因の確認にも使われるケースがあります。
もしもBIツールに急ぎで特定のデータを入れたいといった場合は、Amazon Athenaを検討しましょう。システムアナリストがAmazon S3にデータを保存すると、すぐにクエリを開始します。BIツールとAmazon S3は接続ができるため、そのまま分析後に可視化も可能です。
Amazon Athenaの料金体系は、SQLクエリ単位の従量課金です。
| 東京リージョン | 1TBあたり5.0USD |
|---|---|
| 大阪リージョン | 1TBあたり6.0USD |
※2023年8月現在の価格です。
SQLクエリのデータ量は、Amazon S3上のデータ量に基づいて計算されています。そのためAmazon S3上のデータを圧縮しておけば、その分コスト削減を図れます。
一方、課金対象の最小単位は10MBのため、10MB以下だったとしても10MB分の請求がきますので注意しましょう。クエリが正常に実行できなかった場合は、料金として加算されないため安心してください。
本章では、実践編としてAmazon Athenaの基本的な使い方を解説します。
Amazon Athenaを使うことによってAmazon S3に格納されたデータに対してSQLクエリを発行できます。実際に使用する際に、ぜひ参考にしてください。
Amazon Athenaを利用するには、最初に「データベース」と呼ばれるリソースを作成しなければなりません。
データベースを作成するには、AWSのWebコンソールからAmazon Athenaのページにアクセスしましょう。
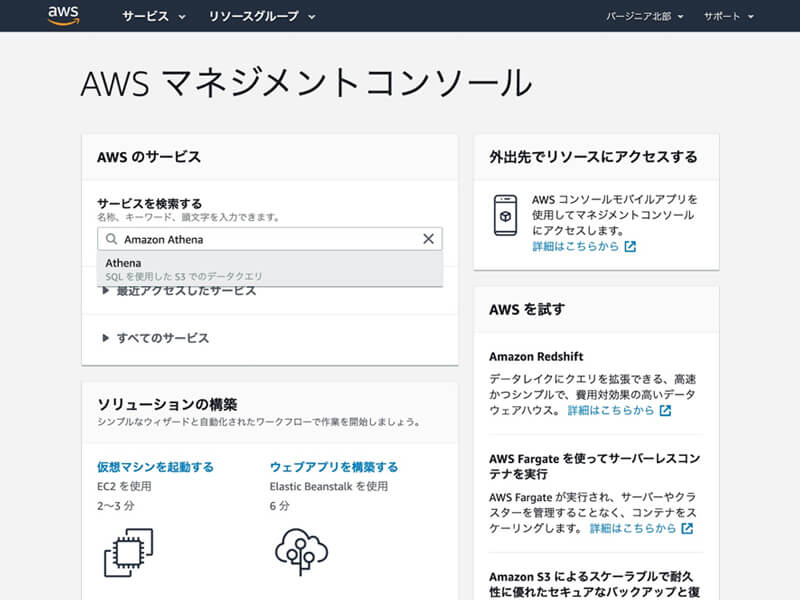
Amazon Athenaのページが表示されたら「Get Started」ボタンをクリックして、Query Editorのページにアクセスします。
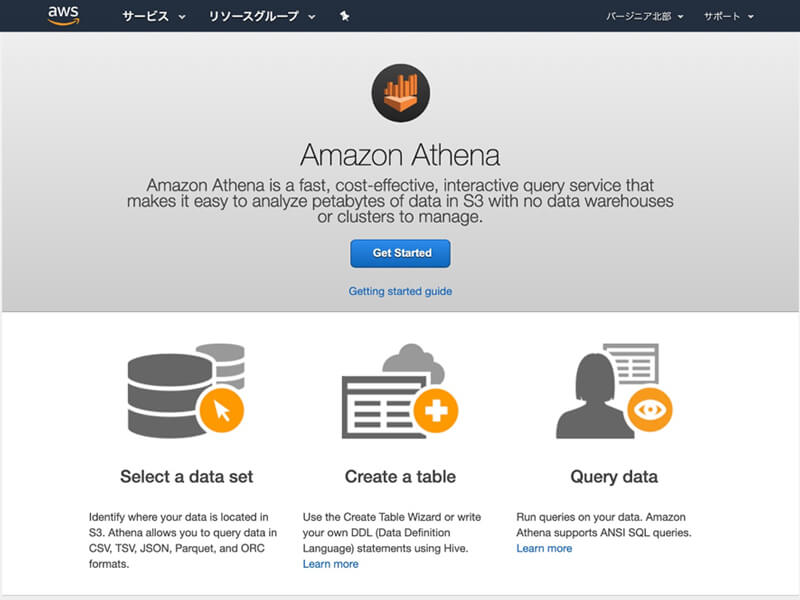
Query Editorのページが表示されたら「set up a query result location in Amazon S3」と表示されたリンクをクリックしましょう。
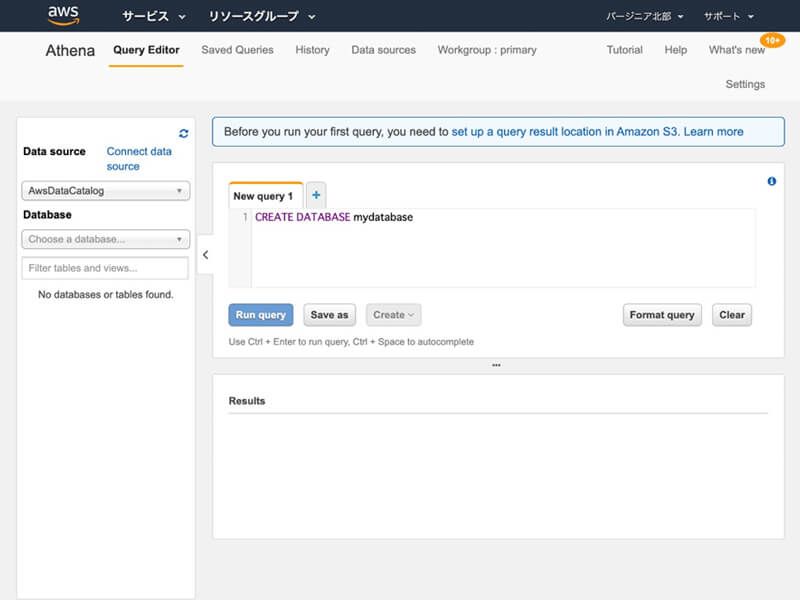
Settingsダイアログが表示された後「Query result location」にAmazon S3バケットのURLを入力してから「Save」ボタンをクリックします。
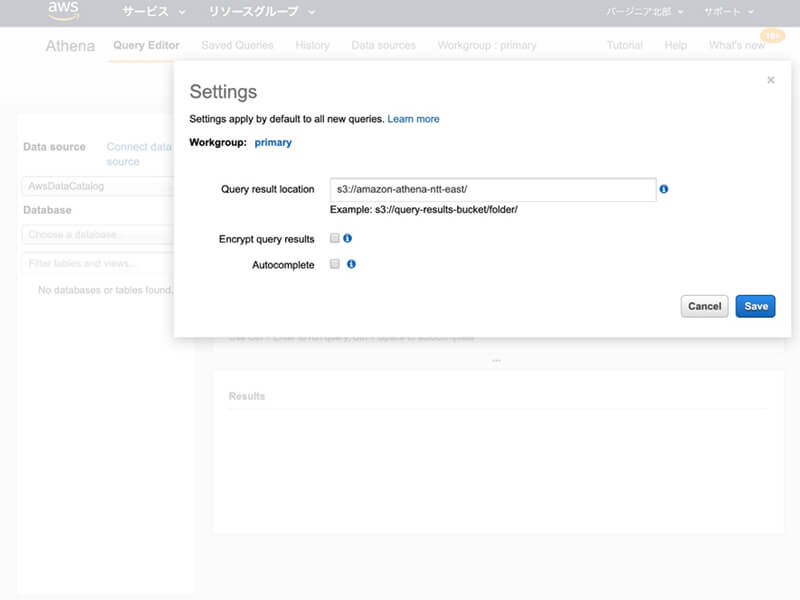
Settingsダイアログが非表示になったら「New query 1」のテキストエリアに下記のSQLクエリを入力してから「Run query」ボタンをクリックしてください。
CREATE DATABASE mydatabase;
SQLクエリの実行が完了した後、Databaseのセレクトボックスをクリックしてから「mydatabase」を選んでクリックしましょう。
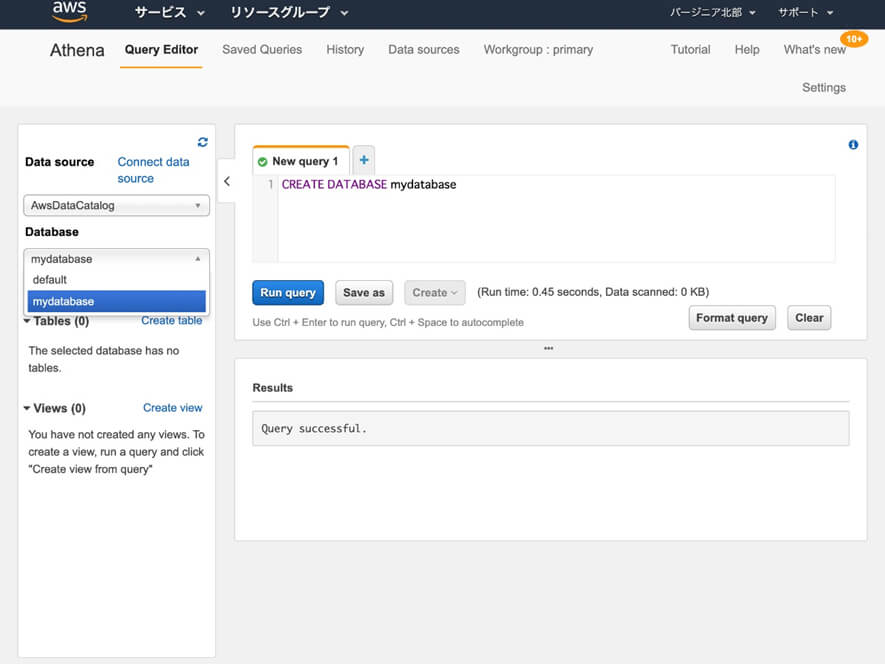
データベースの作成が完了したら「テーブル」と呼ばれるリソースを作成します。
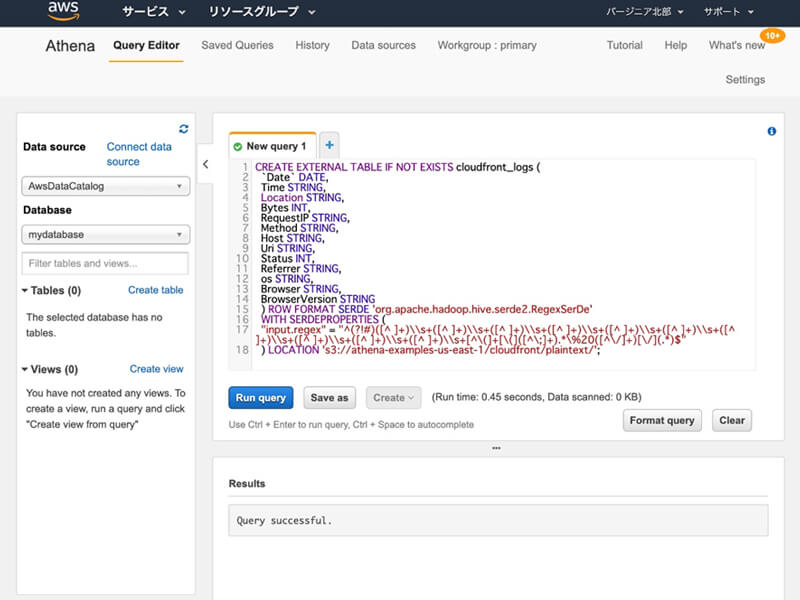
テーブルを作成するには、Query Editorのテキストエリアに下記のSQLクエリを入力してから「Run query」ボタンをクリックしましょう。
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (`Date` DATE,Time STRING,Location STRING,Bytes INT,RequestIP STRING,Method STRING,Host STRING,Uri STRING,Status INT,Referrer STRING,os STRING,Browser STRING,BrowserVersion STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'WITH SERDEPROPERTIES ("input.regex" = "^(?!#)([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+[^\(]+[\(]([^\;]+).*\%20([^\/]+)[\/](.*)$") LOCATION 's3://athena-examples-(ここにリージョンが入ります)/cloudfront/plaintext/';
SQLクエリの実行が完了した後「cloudfront_logs」と記載されたテーブルが作成されたことを確認します。
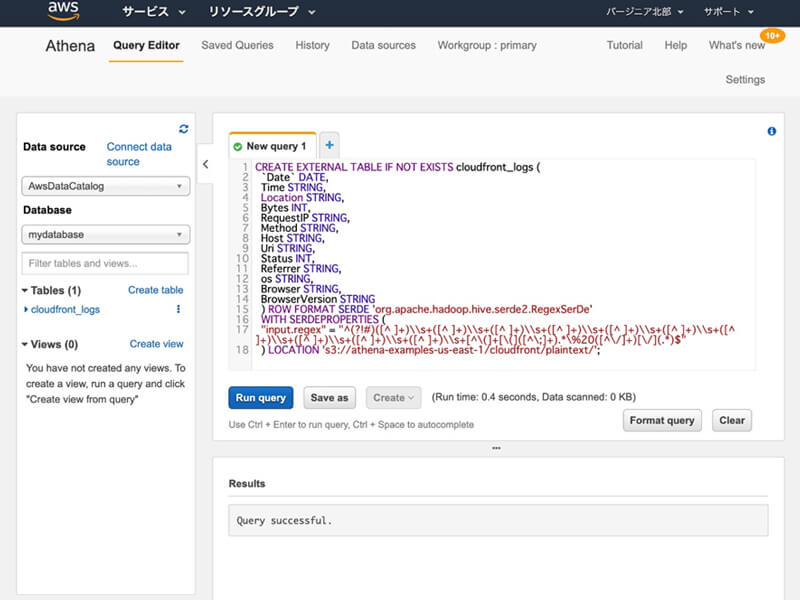
データベースとテーブルの作成が完了した後は、分析のためのSELECTクエリを発行できます。
SELECTクエリを発行するには、Query Editorのテキストエリアに下記のSQLクエリを入力してから「Run query」ボタンをクリックします。
SELECT os, COUNT(*) countFROM cloudfront_logsWHERE date BETWEEN date '2014-07-05' AND date '2014-08-05'GROUP BY os;
SQLクエリの実行が完了した後、実行結果が表示されます。
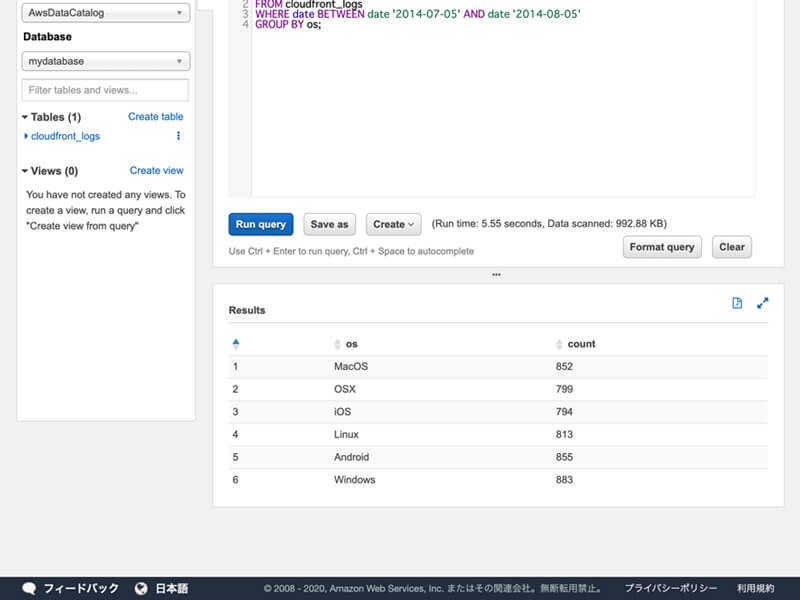
実行結果に含まれるファイルのアイコンをクリックすると、実行結果をCSVデータとしてダウンロードできます。
また、ヘッダナビゲーションに含まれる「History」をクリックすれば、SQLクエリの実行履歴の確認も可能です。
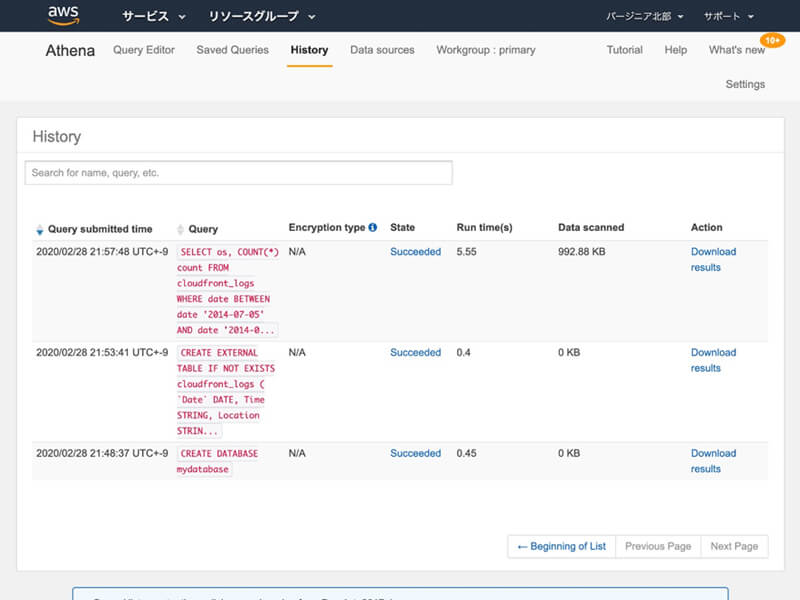
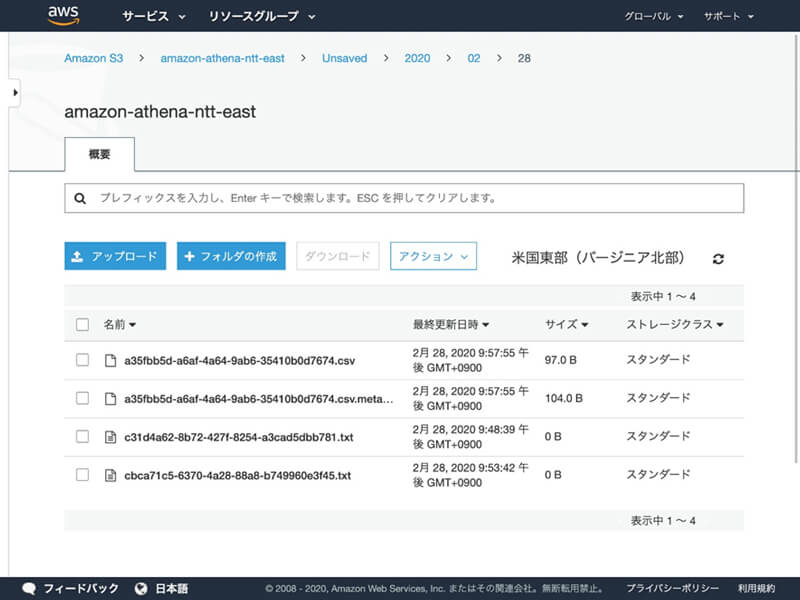
クエリ結果はQuery result locationとして設定された、Amazon S3バケットにも保存されます。
テーブルを作成する際に発行したCREATE TABLEクエリを確認すると「EXTERNAL」「ROW FORMAT」「WITH SERDEPROPERTIES」「LOCATION」など、通常のSQLで使用されたキーワードが、いくつか含まれていることがわかります。
「EXTERNAL」は作成するテーブルが外部テーブルであることを指定するキーワードであり、データベースシステムの外部にあるデータをテーブルとして扱います。
「ROW FORMAT」は外部テーブルの行の形式を指定するキーワードであり、先のCREATE TABLEクエリでは「SERDE」(serializer/deserializer)として正規表現を用いる「org.apache.hadoop.hive.serde2.RegexSerDe」クラスが指定されています。
「WITH SERDEPROPERTIES」はシリアライザー/デシリアライザーのプロパティを指定するキーワードであり、org.apache.hadoop.hive.serde2.RegexSerDeクラスの場合には正規表現が指定されます。
「LOCATION」は外部データソースを指定するキーワードであり、分析対象のAmazon S3オブジェクトのURIが指定されます。
作成したテーブルを削除するには、下記のSQLクエリを実行してください。
DROP TABLE cloudfront_logs;
また、作成したデータベースを削除するには、下記のSQLクエリを実行しましょう。
DROP DATABASE mydatabase;
Amazon Athenaの利用を検討中だけれど、実際導入してから最大限の活用ができるか不安な方や、自社にとってAmazon AthenaとRedshift、どちらの導入が最適か悩んでいる方もいるでしょう。
Amazon Athenaの導入や活用を検討している方は、NTT東日本クラウド導入・運用サービスをご活用ください。NTT東日本では、AWSの知識が豊富にあるプロが、中立的な立場からお客さまにとって最適なプランの提案・導入をサポートします。また、導入後の運用が不安な場合も、運用はもちろん24時間365日の保守対応が可能です。
150社以上の実績があるNTT東日本クラウド・運用サービスの無料相談を試してみませんか。
ご興味のある方は、以下のページをご覧ください。
Amazon Athenaとは、Amazon S3に格納されているデータを直接分析できるAWSのデータ分析サービスのひとつです。
システムエンジニアに馴染み深いSQLを記述言語として利用しており、さまざまなデータ形式に対応しています。またサーバーレスではクエリを実行した分だけの従量課金のため、より作業コストや運用コストが抑えられます。
さらにGZIPなどの圧縮したデータであってもクエリ処理が可能なため、圧縮したデータを分析対象にすることでよりコスト削減を図れるでしょう。
Amazon S3に格納されたデータを効率良く分析したい場合に、Amazon Athenaを活用できます。Amazon Athenaの活用を検討している方は、ぜひNTT東日本クラウド導入・運用サービスにご相談ください。





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


