
AWSにおける大規模障害の原因と対策について
AWS大規模障害はなぜ起きるのか?AWS大規模障害のメカニズムと「Design for Failure」の設計思想を解説。マルチAZや疎結合化など、ビジネスの継続性を高めるための具体的なアーキテクチャ設計と運用対策を紹介します。
![]()


「サーバーが応答しない!」そんな時、焦ってやみくもに再起動ボタンを押していませんか?その操作・状況によっては復旧を遅らせる原因になるかもしれません。
本コラムでは、AWS運用初心者や1人情シスの方に向けて、EC2ダウン時の対応フローを解説します。まずは深呼吸して、ステータスチェックを確認しましょう。「SSH/RDPでログインできるか」を分岐点に、OS内部の調査から、AWS基盤障害に有効な「Stop/Start」の判断まで、最短での復旧ルートをガイドします。

目次:
障害の一報を受けた際、最も怖いのは「パニックになり、確認不足で誤った操作を行い、事態を悪化させること」です。
焦る気持ちを抑え、まずは深呼吸をしましょう。その後の対応をスムーズに進めるため、以下の3点だけは動く前に確認します。
運用において極めて重要なのはコミュニケーションです。関係者に一次連絡を入れることです。調査を開始するのと同時に、必ず「問題が発生しており、現在調査中である」という一次報告を関係者に入れましょう。これにより、現場のパニックを防ぎ、同じ情報が何度も報告されるのを避けることができます。
慌ててEC2の再起動などの操作を行う前に、その問題が本当にEC2インスタンス自体に原因があるのかを確認することが重要です。
実際には、EC2ではなく以下の要因で接続できなくなっているケースが多々あります。
これらの外部要因を一つずつ潰すことが、復旧への最短ルートです。EC2が原因ではないのに操作を始めることこそが、復旧を遅らせる最大の要因になります。
ここで問題がEC2にありそうだと濃厚になったら次章からの作業に取り掛かりましょう。
外部要因を排除し、EC2に問題がありそうだと判断したら、いよいよAWSマネジメントコンソールのEC2ダッシュボードを開いて現状を確認します。
ターミナルで何度も接続を試行錯誤する前に、焦らずにまずは現状を確認することが第一となります。
そこでまずやるべきは、AWSマネジメントコンソールのEC2ダッシュボードを開いて現状を確認することです。
まずはEC2ダッシュボードでサーバーの外観を確認しましょう。ここで見るべきポイントはたったの2つです。
まずは基本中の基本です。対象のインスタンスがどのような状態にあるかを確認します。
ここが一番重要な診断ポイントです。 EC2コンソールの一覧にある「ステータスチェック」の列を見てください。正常時は「2/2 のチェックに合格しました」と緑色で表示されています。
もしこれが赤くなっていたり、「1/2」等になっている場合、AWSはすでに「どこがおかしいか」を教えてくれています。
各ステータスがそれぞれ何をして問題が起きた場合の対処法は以下の通りです。
| チェック項目 | 問題個所 | 想定される原因 | 対処法 |
|---|---|---|---|
| システム ステータス |
AWS |
|
|
| インスタンスステータス | 利用者 |
|
|
具体的な復旧作業(特に再起動や設定変更)を行う前に、必ず現在のサーバーの状態を保存してください。 「バックアップが取れているか分からない」「担当者が不在」という場合は、迷わず手動でバックアップ(AMI)を作成します。
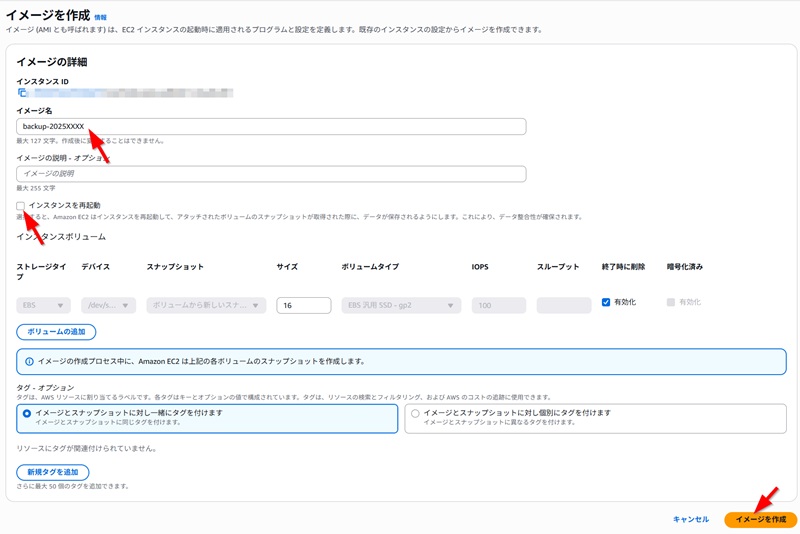
AWSマネジメントコンソールでステータスを確認したら、次は「実際にサーバーに接続できるか」を確認します。これが復旧方針を決める最大の分岐点となります。
通常の保守の際の導線でSSH/RDP等でサーバーに接続しはコンソール/画面に入れるかを確認してください。
ターミナル(SSH)やリモートデスクトップ(RDP)がつながるのであれば、OSは死んでいません。 「とりあえず再起動」する前に、原因を特定しましょう。原因を潰さずに再起動しても、またすぐに同じ症状(ディスクフルなど)でダウンしてしまいます。
ログファイルが肥大化し、ディスク使用率が100%になるとサーバーは正常に動作しません。
$ df -h コマンドで Use% が100%になっているパーティションがないか確認。特定のプログラムがリソースを食いつぶしている可能性があります。
$ top または $ htop コマンドを実行。CPUやMemoryの使用率が高いプロセスを特定し、必要であれば $ kill します。Webサーバー(Apache/Nginx)やDB(MySQL/PostgreSQL)のプロセスが落ちているだけかもしれません。
$ systemctl status nginx などで Active: active (running) になっているか確認。落ちていれば再起動(systemctl restart ...)を試みます。SSHやRDPがタイムアウトする場合、外から手を入れることができません。AWSマネジメントコンソール(外側)からのアプローチが必要です。
AWSマネジメントコンソールの「インスタンスを再起動(Reboot)」は、パソコンの再起動と同じく、OSレベルでのソフトリセットです。 一時的なメモリリークや、プロセスのフリーズであればこれで直ることが多いです。まずはこれを試しましょう。
ここが一番のポイントです。Rebootで直らない、または「システムステータスチェック」が失敗している場合、一度「停止(Stop)」し、完全に停止してから「開始(Start)」を行ってください。
Reboot と Stop/Start の違い
Stop/Start の注意点(必ず読んでください)
ログインできない原因が「Windows Updateが終わらない」「カーネルパニック」などの場合、外部からは分かりません。以下の機能で画面を確認します。
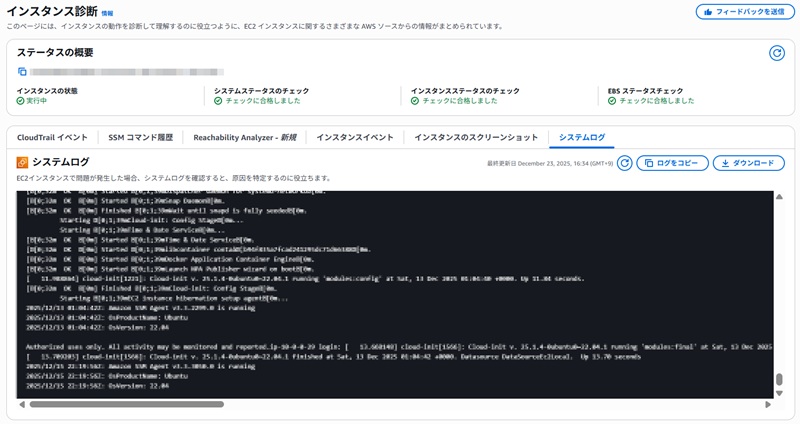
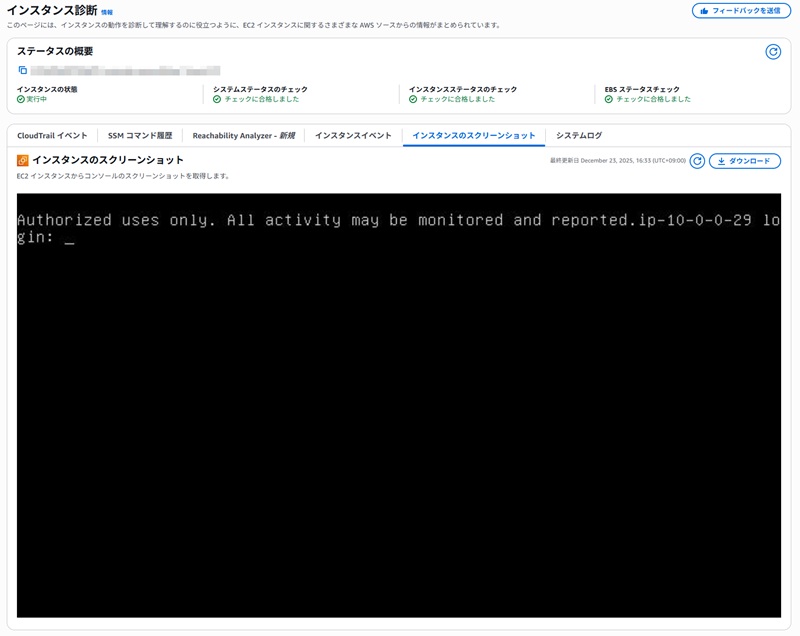
無事にサーバーが復旧したら、最後に「二度と同じ苦労をしないための仕組み」を作りましょう。 AWSのようなクラウドを使う最大のメリットは、「障害をゼロにすること」ではなく、「障害が起きても勝手に直るようにできること」です。
ここでは、1台構成のサーバー(SPOF構成)でも導入できる、3つの「自動化」設定を紹介します。
「Webサイトが見れないんですけど」というユーザーからのクレームでサーバーダウンに気づくのは、管理者として最も避けたい事態です。サーバーが応答しなくなったら、即座にスマホへ通知が飛ぶように設定しましょう。
これで、少なくとも「誰かに言われる前に」調査を開始できます。
通知が来ても、深夜3時に起きてパソコンを開き、再起動ボタンを押すのは苦痛です。この「再起動」作業すらAWSに任せてしまいましょう。
フェーズ2で解説した「システムステータスチェック(AWS側の障害)」が失敗した際に、AWSが自動的に復旧措置を行ってくれる機能です。
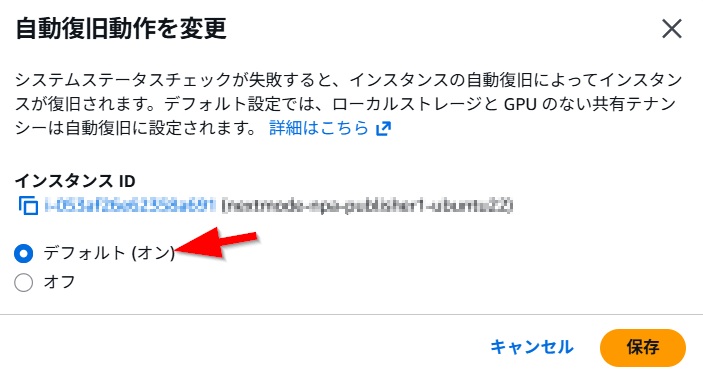
さらに進んだ運用として、「Auto Scaling Group」の使用を強く推奨します。通常は負荷分散(スケーリング)に使われますが、1台構成(最小:1、最大:1)で使うことで強力な「自動蘇生装置」になります。
今回の障害対応で、「いつ取ったか分からないバックアップ」に肝を冷やしませんでしたか? 手動バックアップは必ず忘れます。また、オペレーションミスや、近年急増しているランサムウェア被害から身を守る最後の砦はバックアップだけです。
「何かあったら、昨日の夜の状態に戻せばいい」という安心感があれば、障害対応時の精神的負担は劇的に軽くなります。
サーバーダウンのアラートが鳴った瞬間、心拍数が上がるのはベテランエンジニアでも同じです。しかし、正しい手順を知っていれば、パニックは「冷静な対応」へと変わります。
「1台構成(SPOF)」のリスクと向き合う
もし今回の障害で業務が完全にストップしてしまったのなら、それはサーバー単体(SPOF:単一障害点)に依存しすぎていたサインかもしれません。
物理的な機械である以上、サーバーはいつか必ず壊れます。しかし、AWSのようなクラウドの醍醐味は、「壊れないように祈る」のではなく、「壊れても勝手に直る(あるいは予備が動く)ように設計できる」ことにあります。
今回のトラブルを教訓に、CloudWatchでの監視やAuto Recoveryの設定、あるいはマルチAZ構成への移行など、少しずつインフラを「眠れる構成」へとアップデートしていきましょう。
このコラムが、あなたの緊急対応を助け、より堅牢なシステムを作るきっかけになれば幸いです。
NTT東日本ではAWSの導入・移行・運用の支援を行っております。詳しくはこちらからお問い合わせください。





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


