
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


コンタクトセンター業務では、オペレーターの業務効率化や、顧客情報の運用管理が十分に効率化されていないといった課題が生じがちです。多くのコンタクトセンターでCRMが導入されていますが、十分に活用できておらず、顧客対応に必要な情報が手作業で管理されているため、問い合わせごとにシステムを切り替えたり、情報を検索する手間が増え、業務負荷や対応速度の低下につながっています。また、顧客情報の検索や問い合わせ履歴の確認に時間がかかるだけでなく、情報の手動登録もオペレーターの負担が大きく、最終的には顧客満足度にも影響が出るケースが多く見られます。
このため、顧客情報を効率的に管理し、電話応対時に迅速に情報を検索できるとともに、顧客の問い合わせ情報を自動的に登録できる仕組みが求められます。
こうした課題を解決する一例として、クラウド型コンタクトセンターサービスのAmazon ConnectとCRMのKintoneを連携させ、顧客情報を効率的に検索や、AI機能を活用した通話内容の要約、自動登録する方法をご紹介します。
NTT東日本ではAmazon ConnectとCRMツールとの連携や、生成AIを活用した電話業務の効率化を支援しておりますので詳細はこちらをご覧ください。
関連コラム

目次:
本コラムでは、以下の構成でAmazon ConnectとKintoneの連携を行います。
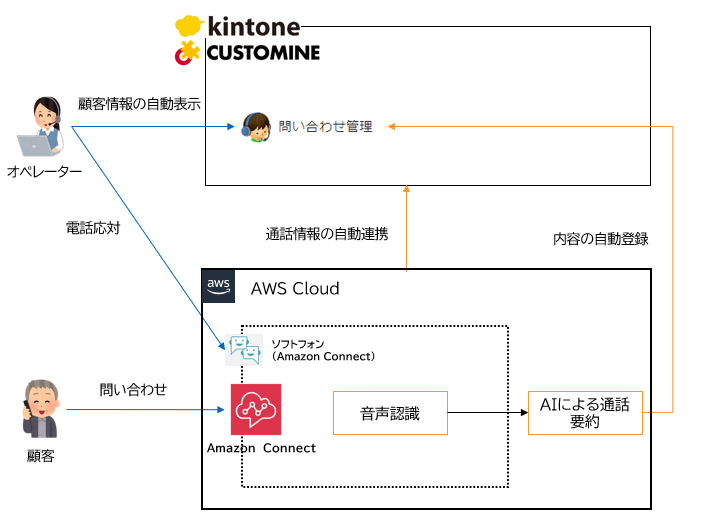
顧客からの問い合わせが入ると、自動的に既存の顧客情報がKintoneから検索・表示されるため、オペレーターは迅速かつ正確に対応できるようになります。新規顧客の場合も、Kintoneに顧客の関連情報が自動的に作成・登録されるため、対応後の記録作業が簡便化されます。この仕組みにより、顧客対応の質が向上し、オペレーターの負担も軽減される効果が期待できます。
さらに、Amazon Connectでは通話内容がリアルタイムで音声認識され、AIによって要約が自動生成されます。この要約や通話情報はKintoneに自動登録され、問い合わせ履歴として保存されるため、オペレーターが手動で入力する手間が省け、業務効率が大幅に向上します。
Amazon Connectと生成AIを活用した電話業務効率化ソリューションはこちら!
この仕組みを実現するための具体的な方法を以下の1〜3のステップの順で説明します。
① Amazon ConnectとKintone間のシステム連携のセットアップ
② 着信時の顧客問い合わせ履歴の処理
Kintoneに問い合わせ履歴を自動で新規作成し、顧客情報を登録
電話番号をもとに既存顧客の履歴を検索し、自動で画面に表示
③ 電話応対完了後、通話内容をAIで要約し、Kintoneに自動登録
本手順では、以下のサービスを利用できることが前提となります。
KintoneやGusuku Customineは有料サービスとなりますが、無料のお試しプランもあるため、検証等にご活用ください。
なお、上記サービスの契約や初期構築は本手順の対象外となります。ご不明な点がある場合は、各サービスの公式ドキュメントを参照してください。
まずKintoneアプリの準備とAmazon Connect ⇔ Kintone間の連携設定を行います。
Kintoneにログインし、ポータルのアプリから「+」をクリックします。
Kintoneアプリストアから応対履歴を管理するためのアプリを作成します。
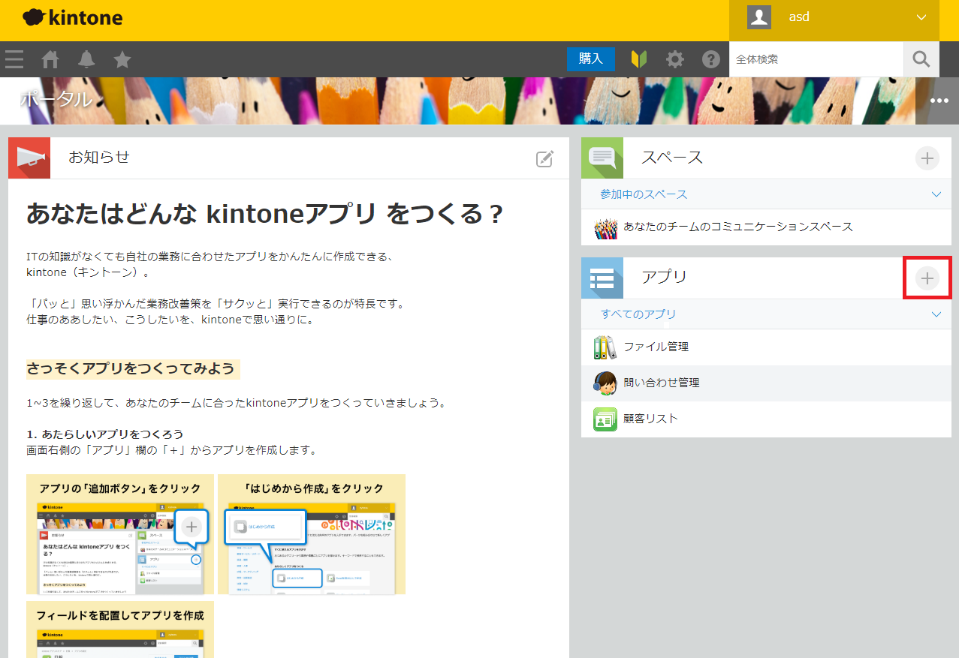
本コラムでは顧客応対履歴を管理するためのアプリ「問い合わせ管理」を使用します。
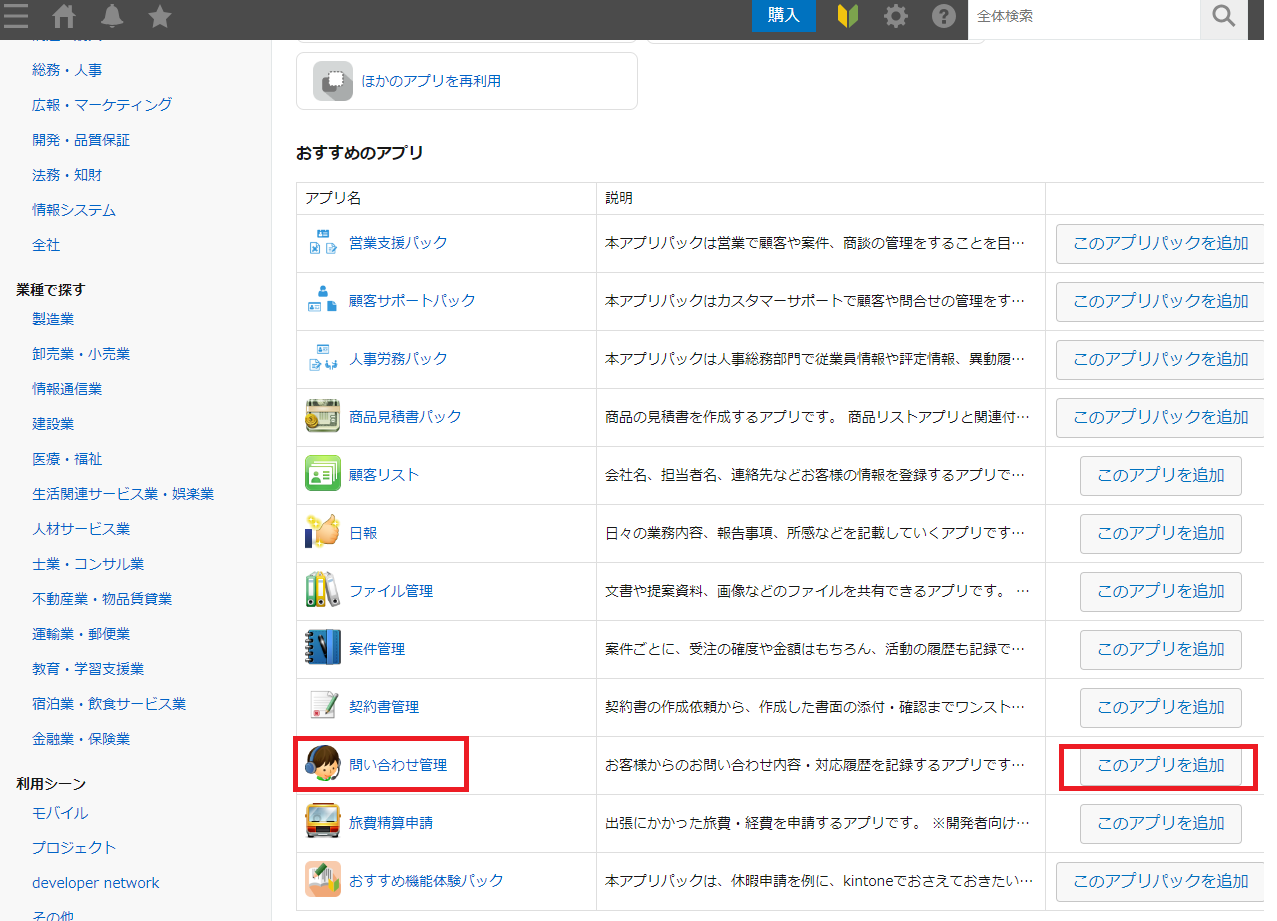
AWS マネジメントコンソールで Amazon Connect コンソールを開き、利用中のAmazon Connectを選択します。
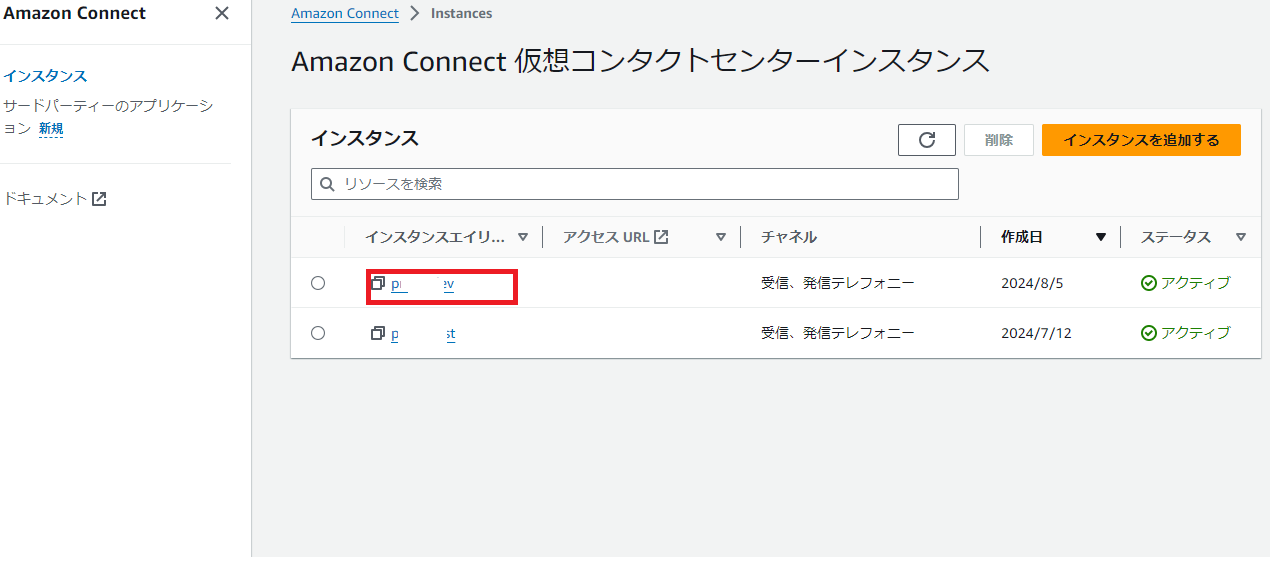
(もし利用中のAmazon Connectがない場合、「インスタンスを追加する」を選択して、Amazon Connectインスタンスを新規作成します。)
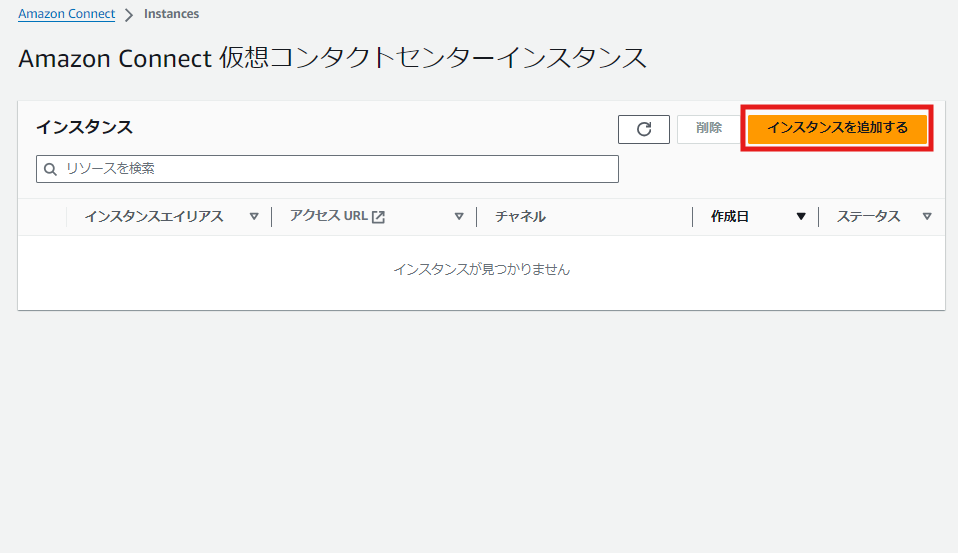
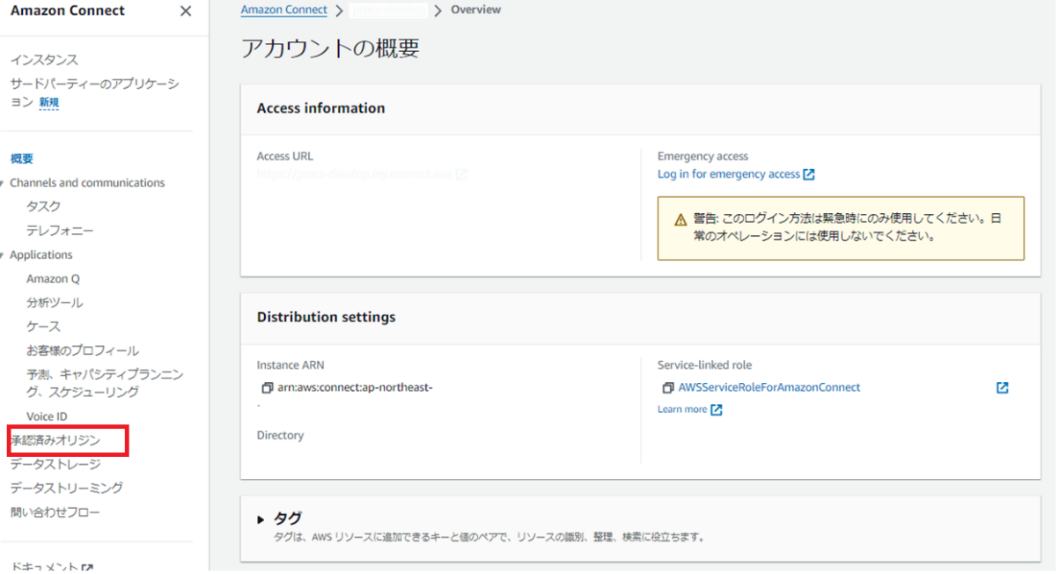
次にAmazon Connectのインスタンス概要から「承認済みオリジン」を選択します。
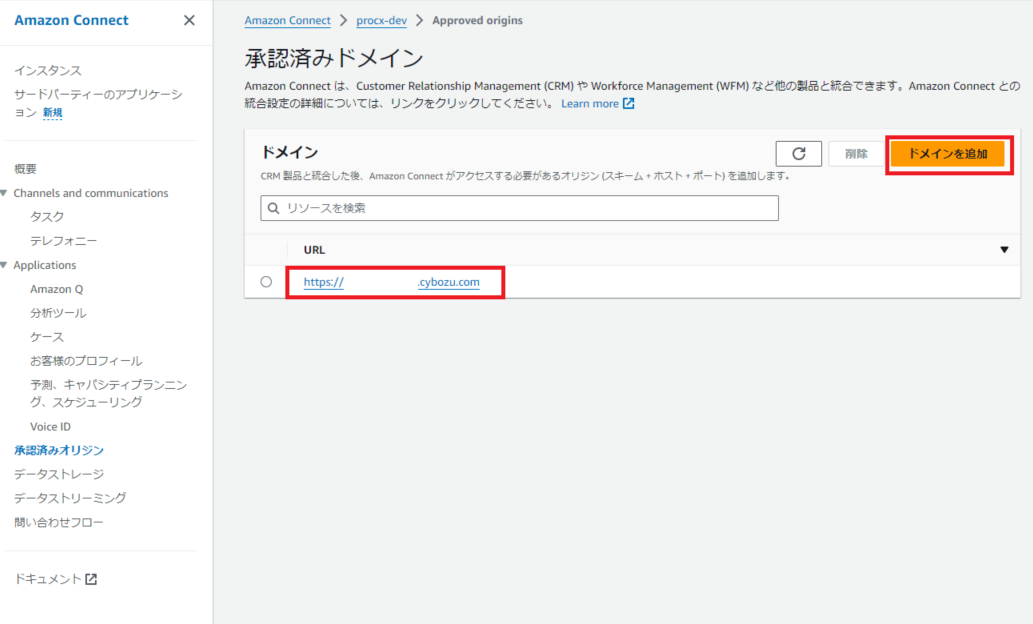
「ドメインを追加」を選択して、Kintoneのドメイン名を登録します。
https://<契約テナント名>.cybozu.com
電話応対の際には、新規顧客と既存顧客の2つのケースが考えられるでしょう。
① 新規顧客の場合、Kintoneに問い合わせ履歴を自動で新規作成し、顧客情報を登録する必要があります。
② 一方で、既存顧客の場合には、既存の顧客情報を検索し、自動で画面に表示する仕組みがあると対応の効率化が図れます。
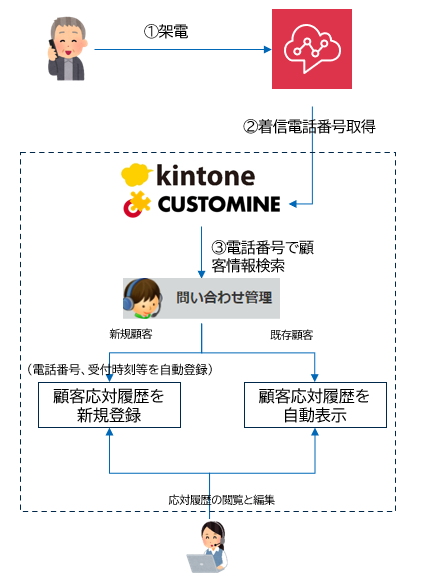
上記は、顧客から着信があった際の処理フローを示しています。
① 架電:顧客からの電話がAmazon Connectに入ります。
② 着信電話番号等の情報取得:Amazon Connectが顧客の電話番号等の情報を取得します。
③ 顧客情報検索:取得した電話番号をもとに、Kintoneの「問い合わせ管理」アプリから顧客の問い合わせ履歴を検索します。
新規顧客の場合:電話番号や受付時刻等の新規顧客の問い合わせ履歴を自動作成して表示します。
既存顧客の場合:既存の顧客問い合わせ履歴を表示します。
では、このフローを実現するための設定手順を見ていきましょう。
3-1.で作成したKintoneアプリを開き、設定アイコンを選択します。
(本検証で使用するKintone上のデータはサイボウズ社が提供するデモデータを使用しております。)
フォームに「文字列(1行)」を追加して、設定画面を開きます。
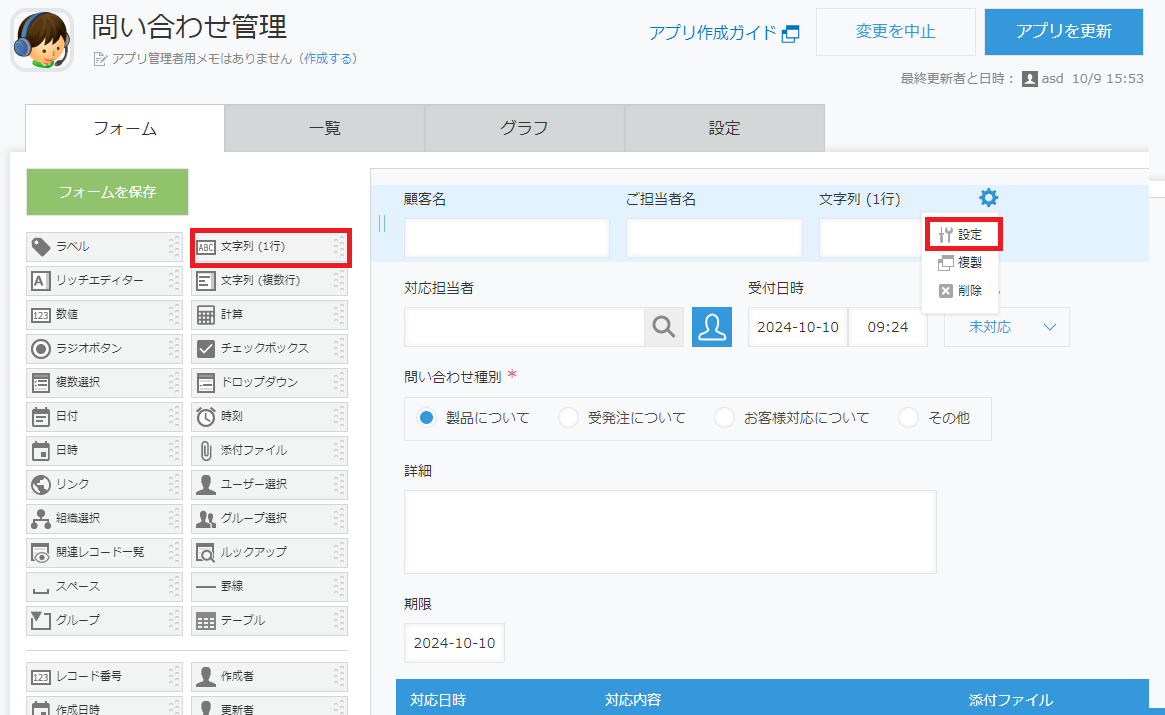
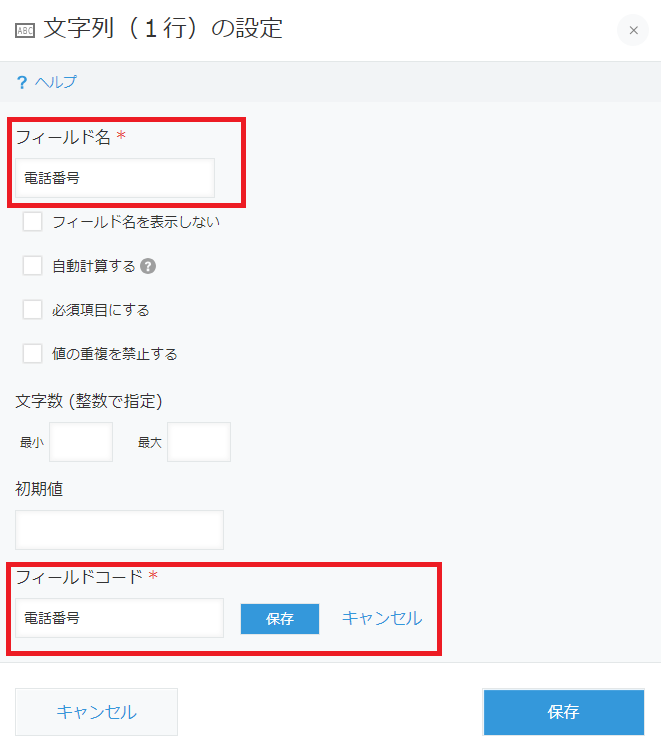
「フィールド名」と「フィールドコード」を電話番号に変更して、保存します。
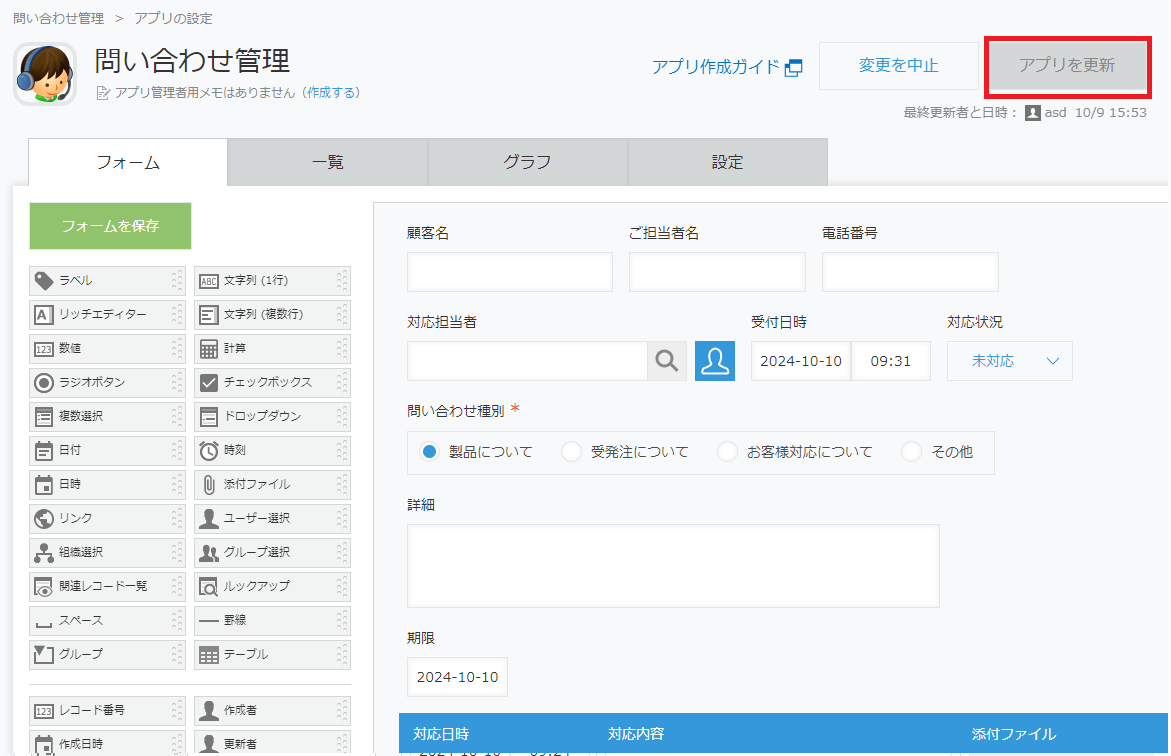
「アプリを更新」を選択して、変更を反映します。
Gusuku Customineとは、プログラミング不要でKintoneアプリにカスタマイズ機能を追加できるプラグインです。簡単な操作で自動入力や外部システム連携などが可能になります。
今回は、このGusuku Customineを使って、着信時の顧客情報検索などの処理フローを実装していきます。
Gusuku Customineにログインして「新規のカスタマイズ作成」から「Kintoneアプリのカスタマイズ」を選択します。

3-1.で作成した「問い合わせ管理」アプリを選択して、「選択決定」を選択します。
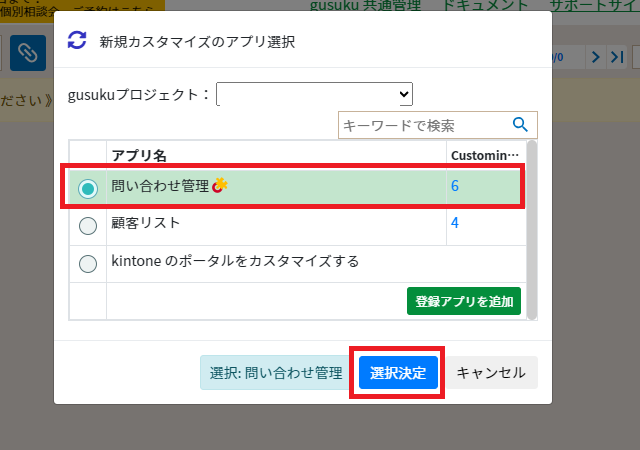
アプリのカスタマイズ画面が表示されますので、これから処理フローを作成していきます。
先にAWS マネジメントコンソールで Amazon Connect コンソールを開き、インスタンスエリアス名をメモします。
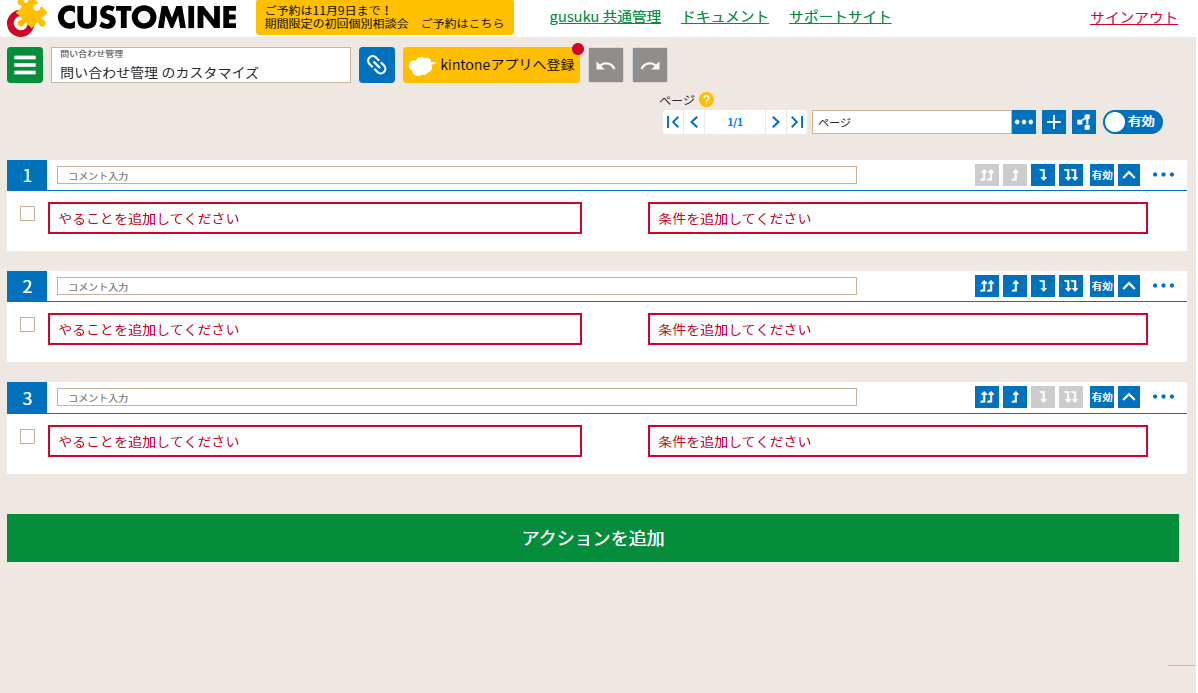
次にカスタマイズ画面に戻り、各ステージに以下のように「処理(やること)」と「条件」を入力します
|
<ステップ①>
<ステップ②>
<ステップ③>
|
|
|
<ステップ⑤>
<ステップ⑥>
|
顧客問い合わせ履歴が存在しない場合の分岐 |
|
<ステップ⑦>
|
顧客問い合わせ履歴が存在する場合の分岐 |
入力完了後の処理フローは以下の通りです。
最後に「Kintoneアプリへ登録」を選択して、変更を反映します。

Kintoneの「問い合わせ管理」に戻ります。
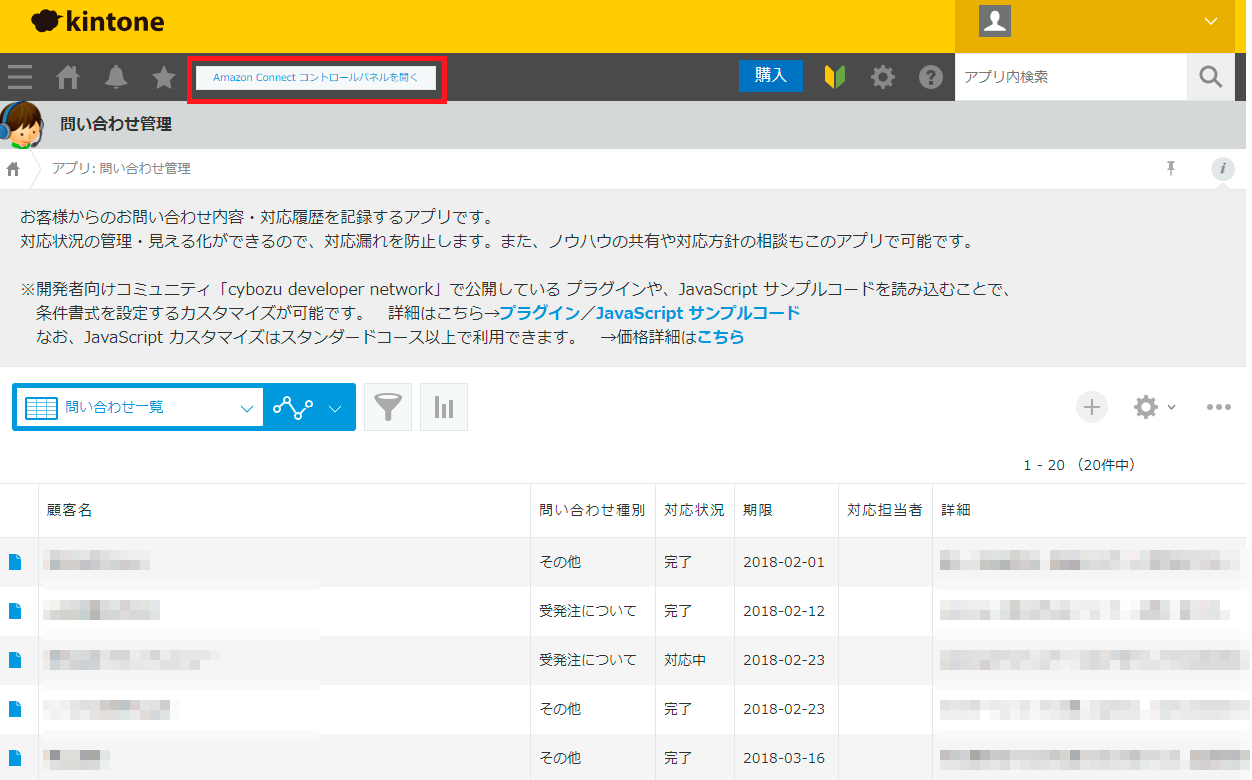
「Amazon Connect コントロールパネルを開く」というボタンが表示されるようになり、先ほどの設定が無事に反映されたことが確認できました。
(本検証で使用するKintone上のデータはサイボウズ社が提供するデモデータを使用しております。)
処理フローの設定は以上になります。
では、実際に着信があったときの動作を確認してみましょう!
Kintoneの「問い合わせ管理」から「Amazon Connect コントロールパネルを開く」を選択します。
ログインするとAmazon Connectのソフトフォンが表示されます。
先に新規の顧客の場合を見てみましょう!
携帯電話などからAmazon Connectの電話番号に発信すると、「着信がありました」というインフォメーションが表示されます。
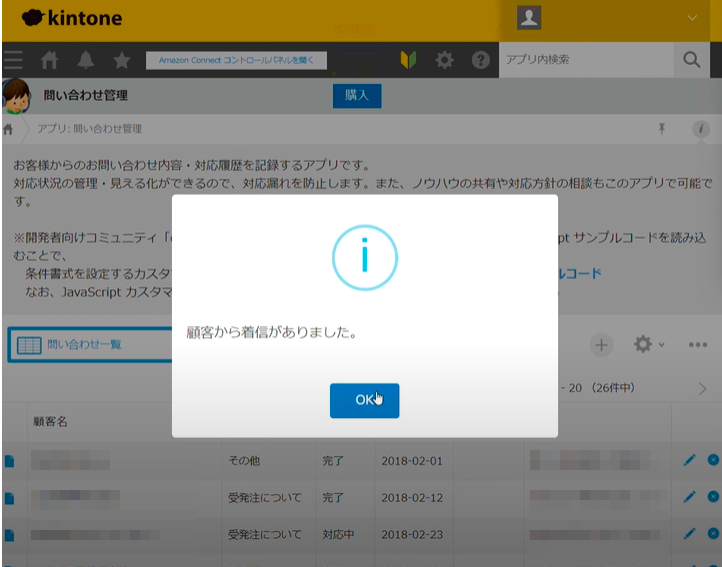
インフォメーションから「OK」を選択すると、新規顧客の問い合わせ履歴が自動的に作成されます。さらに、データには着信のあった顧客の電話番号や受付時刻が登録されていることが確認できます。これで、手動で電話番号などの顧客情報を記録したりメモしたりする手間が省けるでしょう
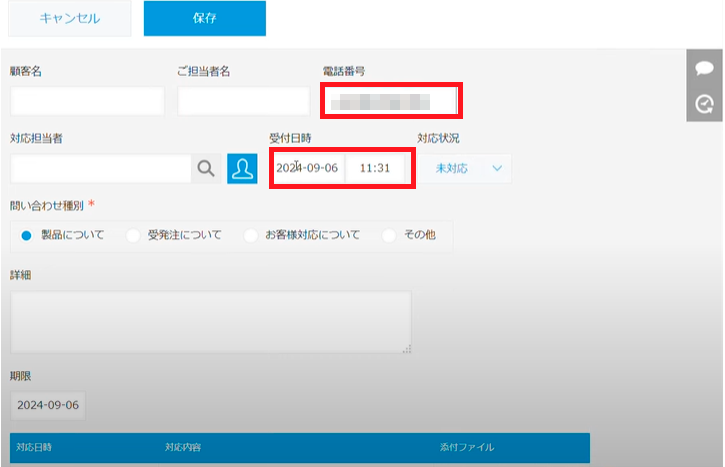
最後に、電話応対が完了して「保存」ボタンを選択すると、問い合わせ履歴が自動的に保存されます。
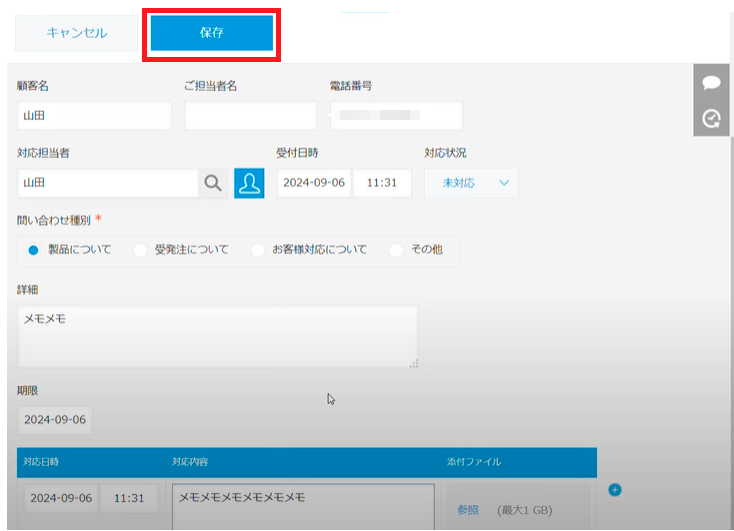
では、既存顧客の場合の動作も見てみましょう!
同じ電話番号から再度Amazon Connectに発信すると、インフォメーションが表示されます。
着信した電話番号がすでにKintoneアプリに登録されているため、それに紐づく顧客情報もインフォメーションに表示されるようになります。
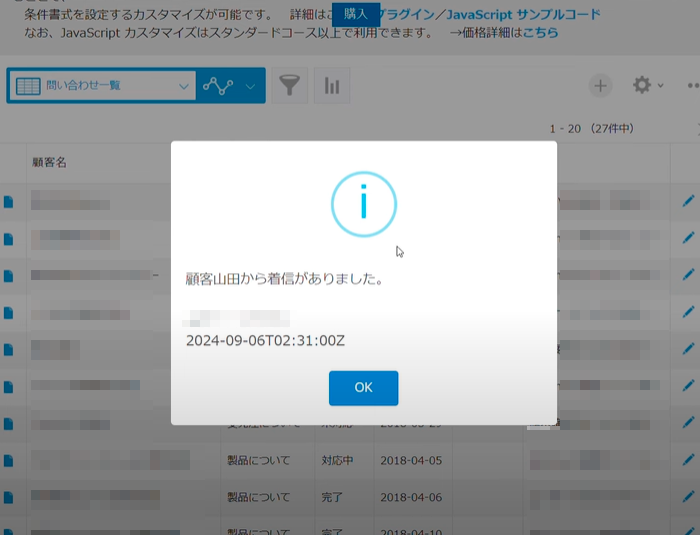
インフォメーションから「OK」を選択すると、顧客の登録済みデータが自動的に表示され、お客様情報や以前に登録した履歴などが確認できます。
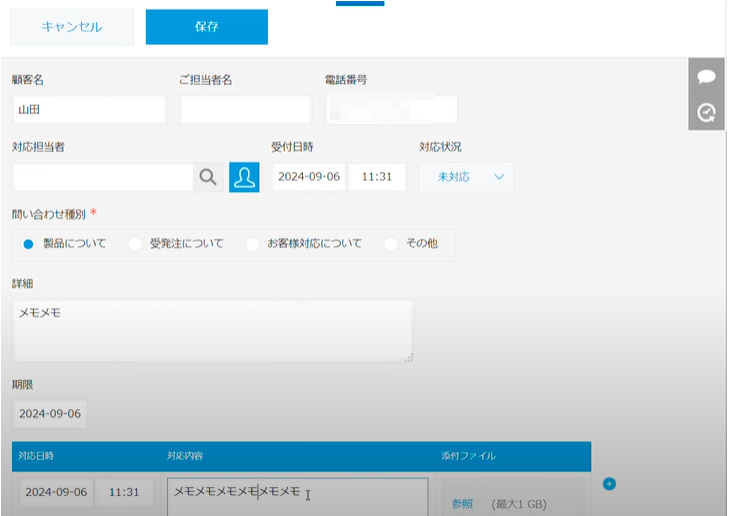
最後に応対メモや顧客情報等をアップデートして、「保存」ボタンを選択するとデータが反映されます。
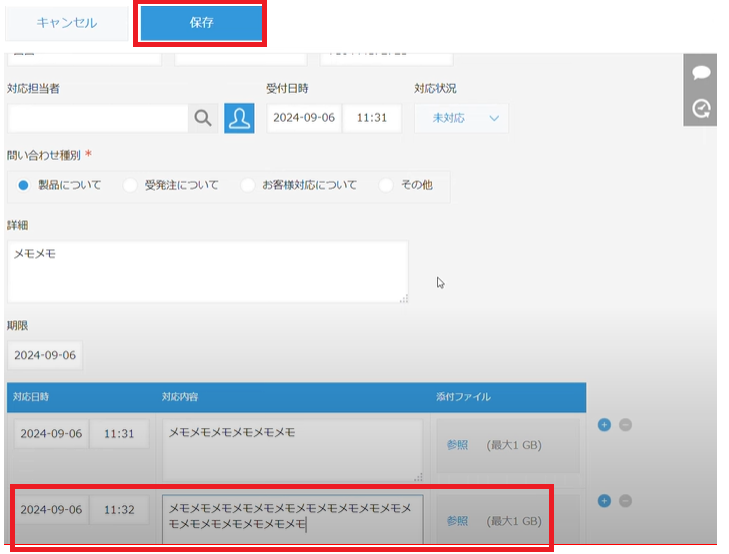
いかがでしょうか。これらの仕組みにより、着信時に顧客情報が自動表示され、新規顧客の場合は自動で履歴が作成され、既存顧客の場合は過去の履歴が即座に確認できるため、対応の質も向上し、業務の負担が軽減されるでしょう!
電話応対後に会話内容を記録する際、オペレーターが手動で要約を作成するのは確かに時間がかかり、業務負荷が増える要因になります。そこで、AIを活用して通話内容を自動的に要約し、Kintoneに自動登録することで、業務効率を向上させる仕組みを構築します。
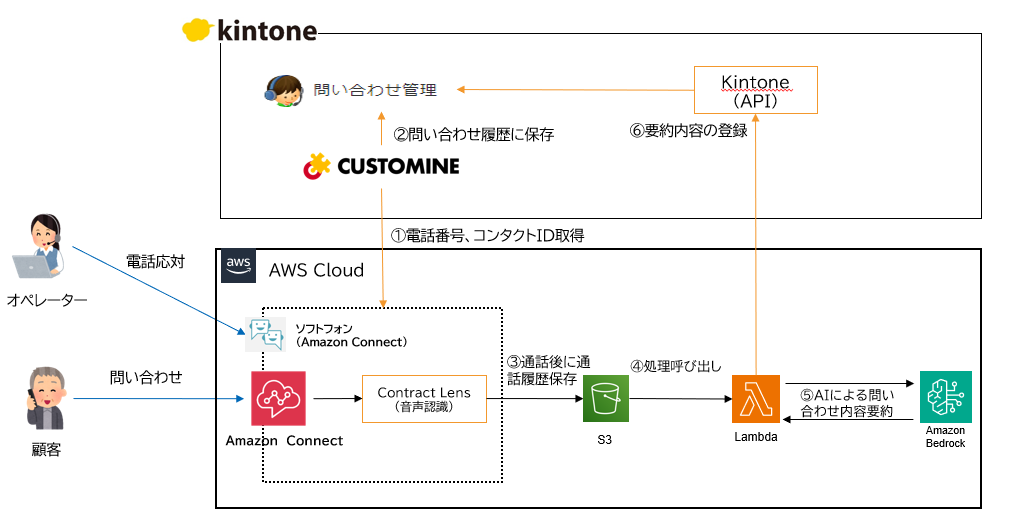
システム構成図は上記の通りです。顧客からの問い合わせがあると、Gusuku CustomineがAmazon ConnectからコンタクトIDなどの通話情報を取得し、Kintoneに問い合わせ履歴を自動登録します。この仕組みにより、問い合わせ履歴と顧客情報が確実に紐づけられます。通話終了後、通話内容はS3に保存され、LambdaとAmazon Bedrockを使用してAIで要約が生成され、APIを通してKintoneの問い合わせ管理アプリに登録されます。
3-1.で作成したKintoneアプリを開き、設定アイコンを選択します。
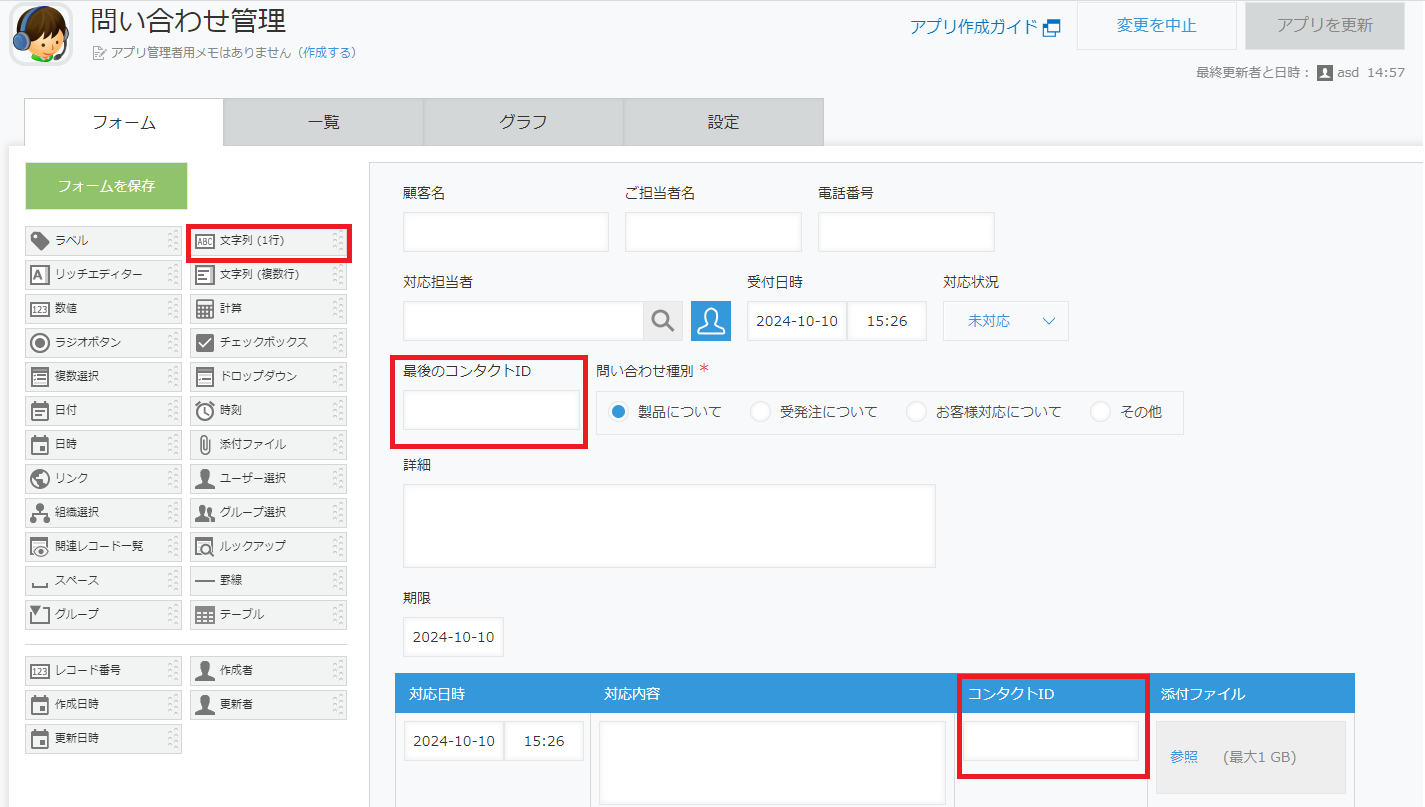
フォームに「文字列(1行)」を選択して、以下ように設定してください。
「アプリを更新」ボタンをクリックし、変更を反映します。
Gusuku Customineのアプリカスタマイズ設定を開き、以下の処理を追加します。
<ステップ⑧>
条件:Amazon Connect で通話を開始した時
<ステップ⑨>
処理:レコードを更新する(キーの値を直接指定)
条件:Amazon Connect で通話を終了した時
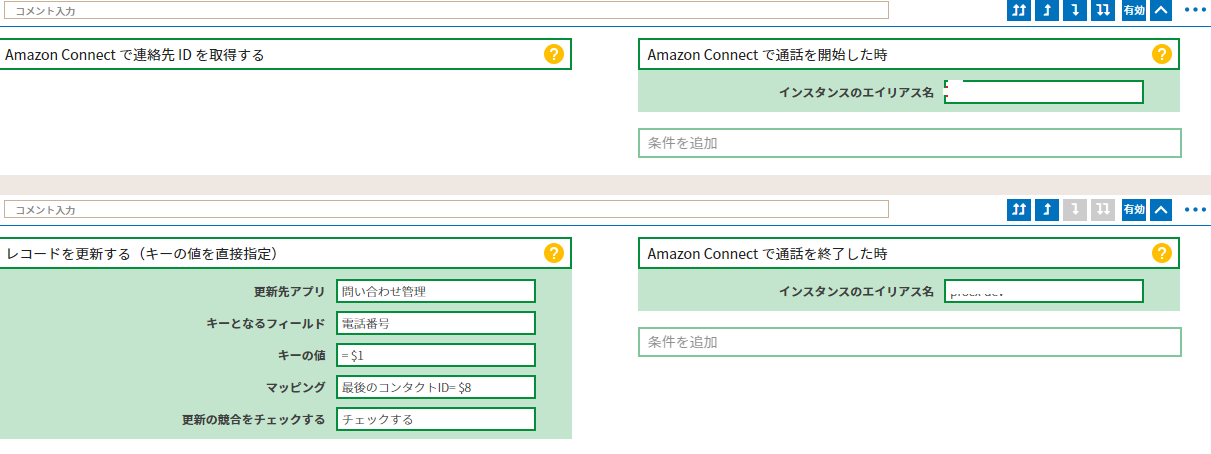
完了後に「Kintoneアプリへ登録」を選択して、変更を反映します。

Amazon Connect Lensは通話の文字起こしと通話要約機能を提供していますが、残念ながら通話要約機能は日本語をサポートしておりません。
そのため、今回は通話データを活用し、Bedrockを用いてAIで要約を生成する実装します。
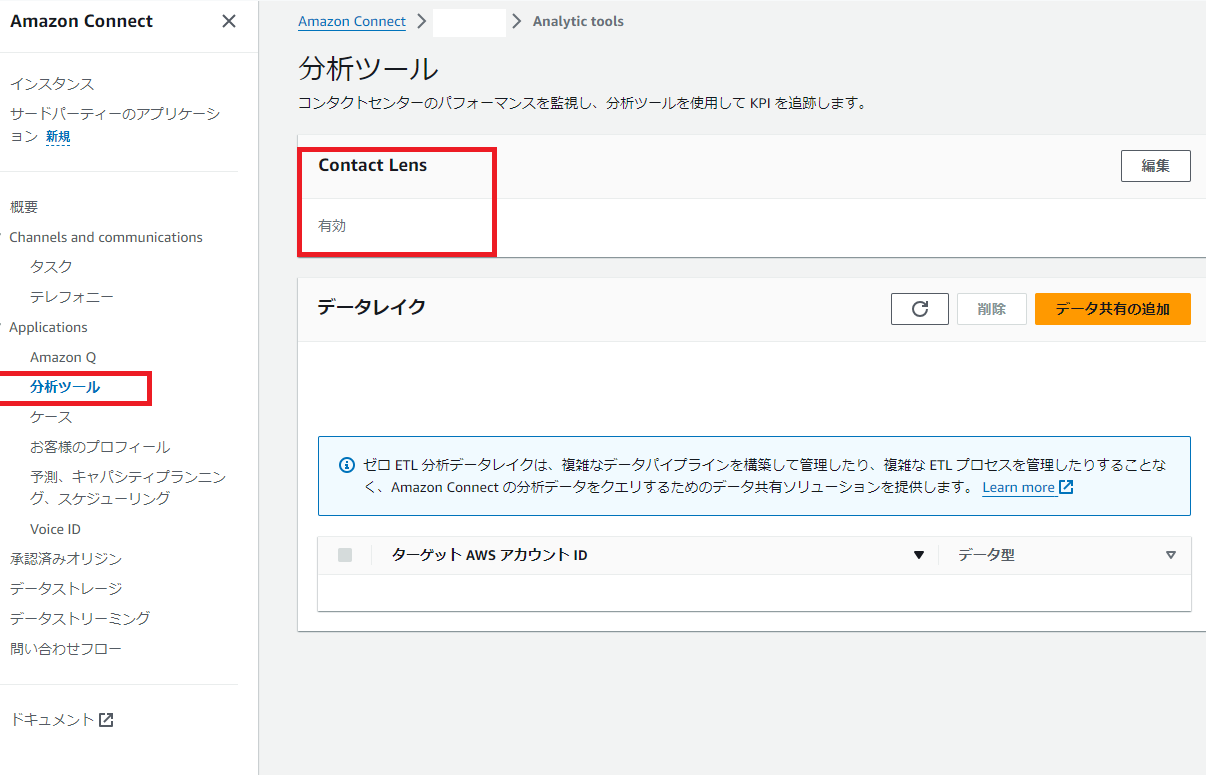
Amazon ConnectのWebコンソール画面を開き、Contract Lensを有効化にします。
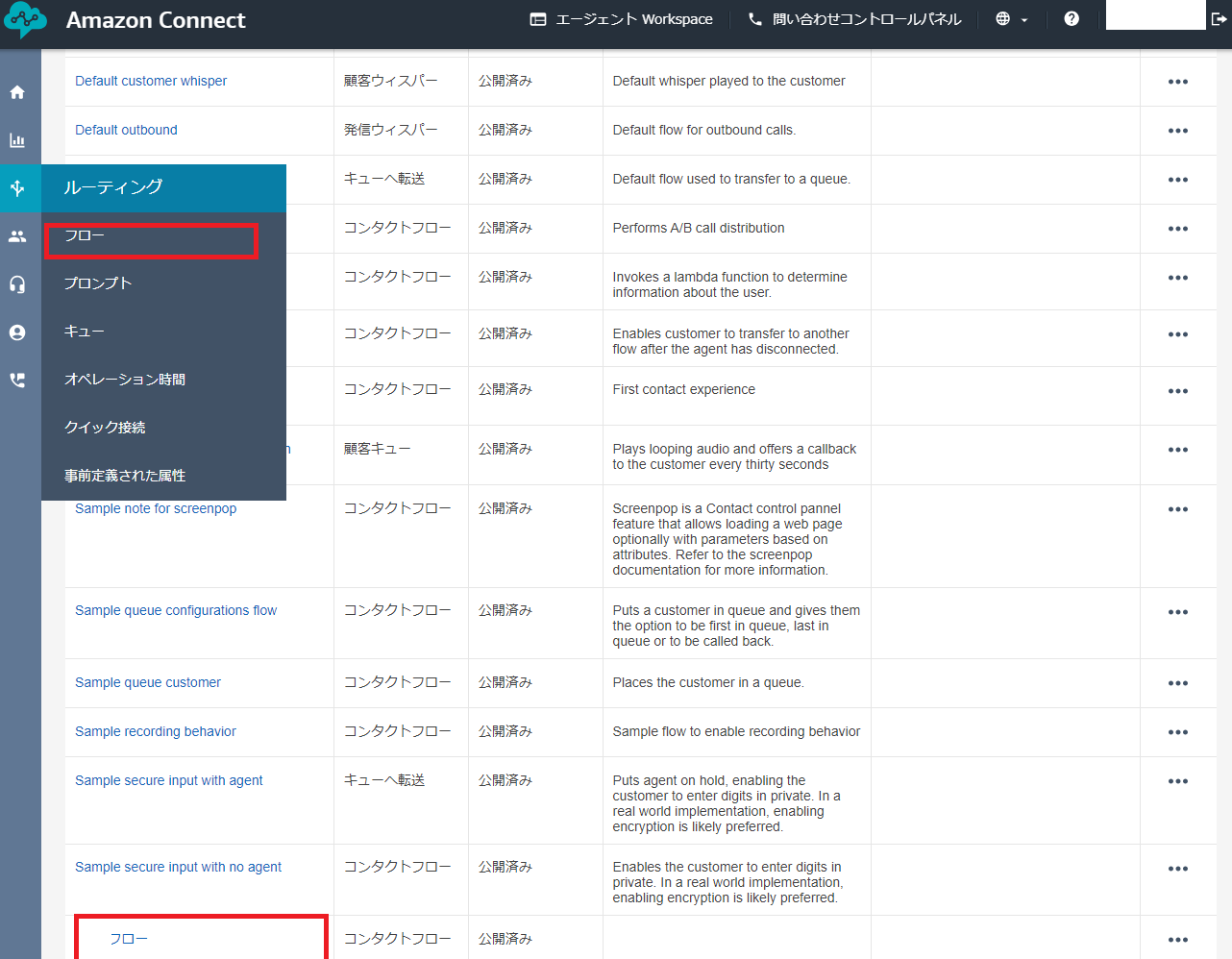
Amazon Connectの管理画面にログインして、コンタクトフローの編集画面を開きます。
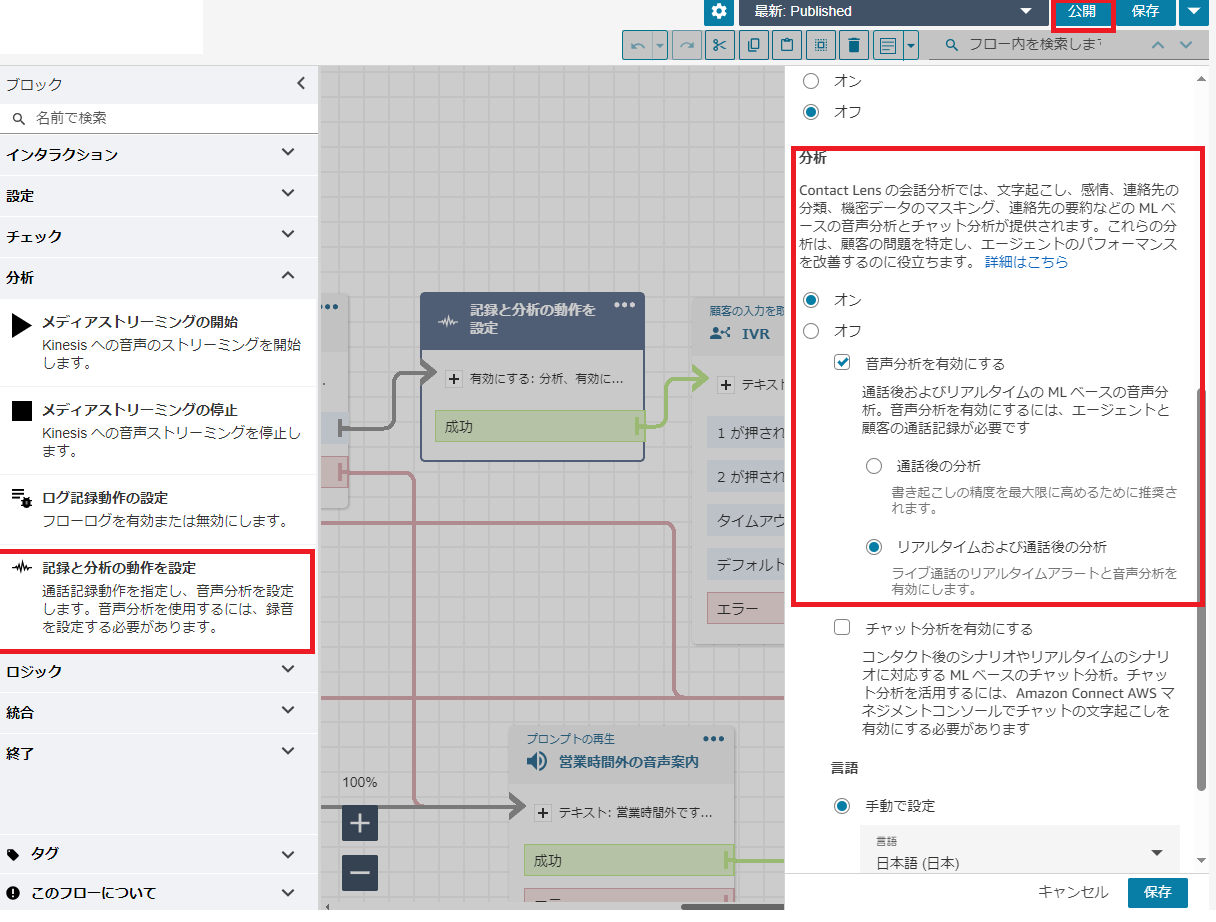
「記録と分析の動作を設定」をフローに追加して、音声分析機能の「リアルタイムおよび通話後の分析」を有効にしてフローを公開します。
通話内容はデフォルトでAmazon ConnectのS3に、以下の形式でJSONファイルとして保存されます。
s3://<S3バケット名>/Analysis/Voice/<日付>/<コンタクトID>_analysis_<タイムスタンプ>.json
JSONファイルには文字起こしされた通話内容が記録されており、これらのデータを用いてAIによる要約を行います。
<例>
・・・・
"Transcript": [
{
"BeginOffsetMillis": 7827,
"Content": "こんにちは、どのようなご用件でしょうか?",
"EndOffsetMillis": 8186,
"Id": "c96aa949-5836-447d-8f77-3064cc67b2b1",
"LoudnessScore": [
59.86,
0
],
"ParticipantId": "AGENT",
"Sentiment": "NEUTRAL"
},
{
"BeginOffsetMillis": 41870,
"Content": "商品の返金をお願いしたいのですが。",
"EndOffsetMillis": 42127,
"Id": "1ea9c10b-c80c-4a4f-9d60-f064996f4c21",
"LoudnessScore": [
0,
72.89
],
"ParticipantId": "CUSTOMER",
"Sentiment": "NEUTRAL"
},
・・・
次に、AIで要約を行うための処理をLambda関数で作成していきます。
AWS マネジメントコンソールで Lambdaを開き、「関数の作成」を選択します。
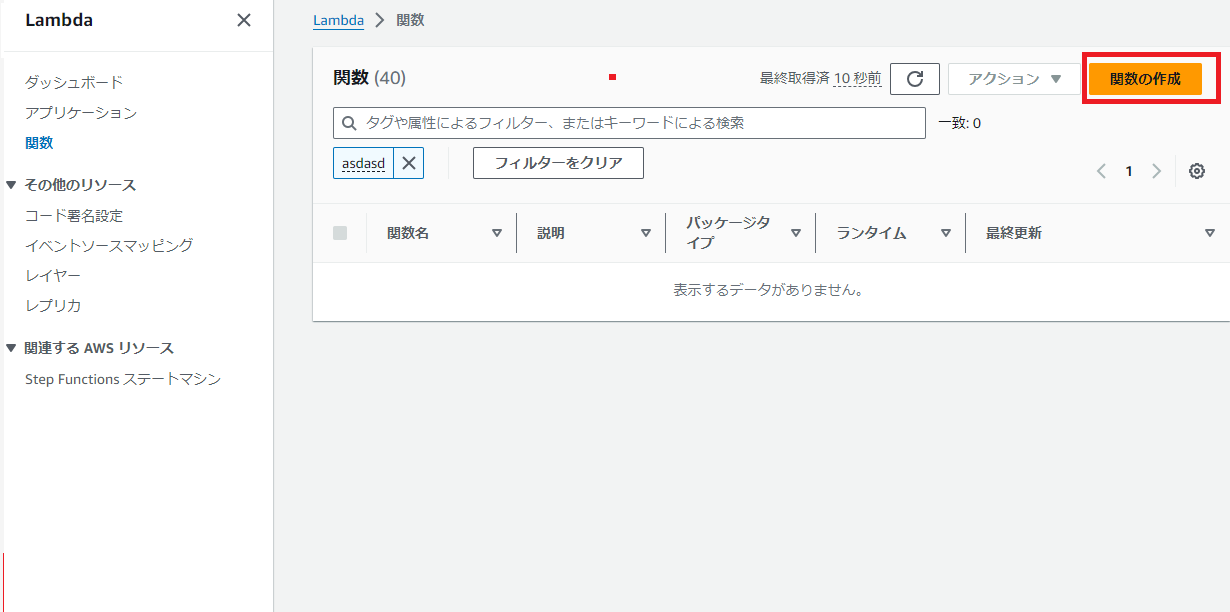
任意の関数名を入力し、ランタイムをPython 3.12に設定して、「関数の作成」を選択します。
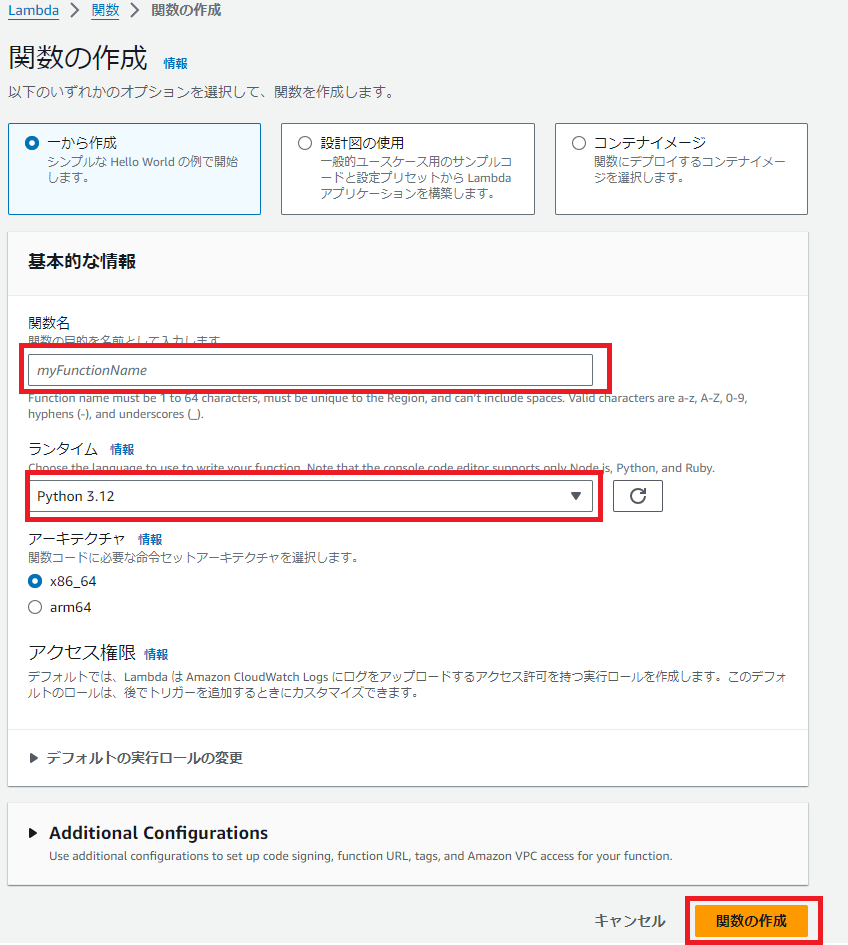
Lambda関数に以下のソースコードを貼り付け、「Deploy」を選択すると、Lambda関数が更新されます。
この関数は、通話データをS3から取得し、内容を要約するプロンプトを生成して、指定したBedrockのLLM(MODEL_ID)に送信します。要約が生成されると、その結果を出力します。
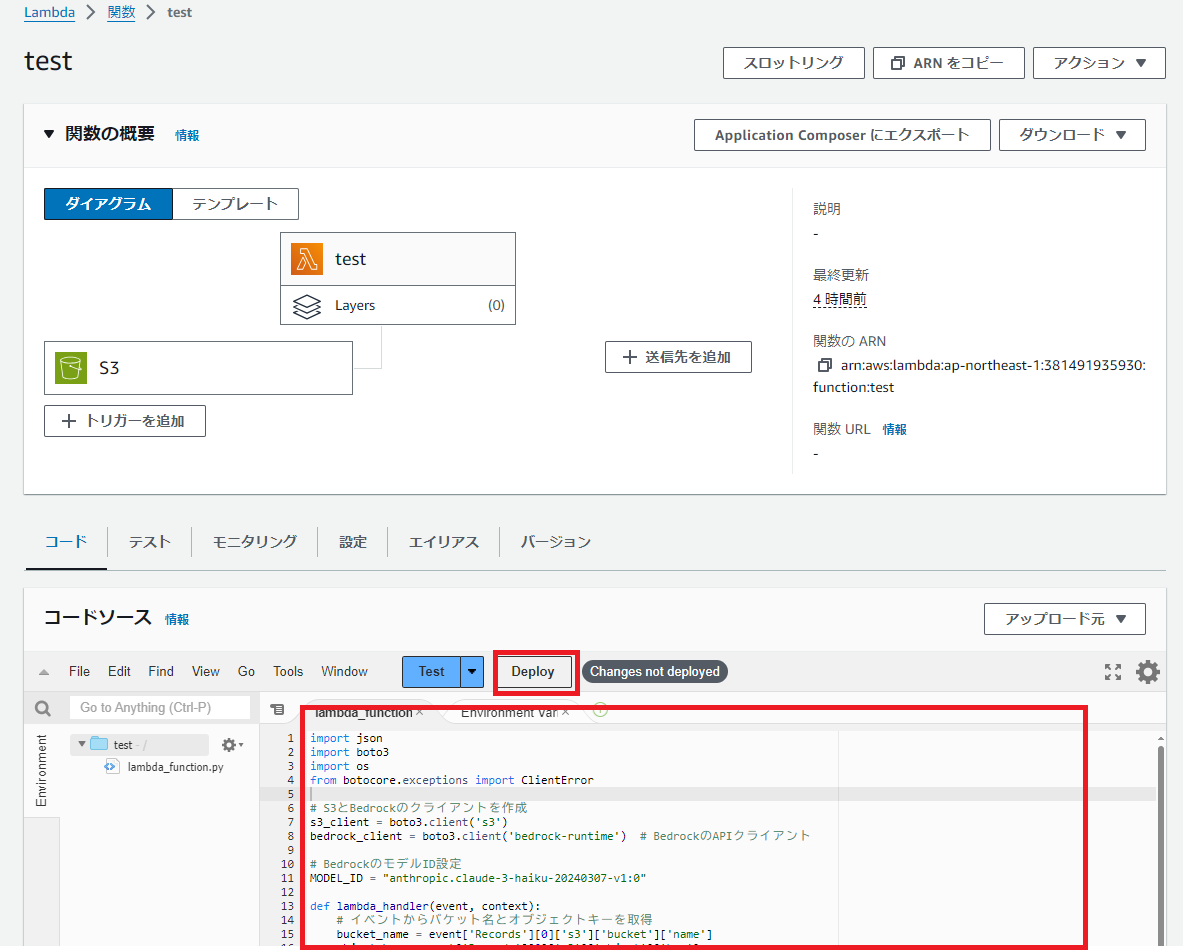
import json
import boto3
import os
from botocore.exceptions import ClientError
# S3とBedrockのクライアントを作成
s3_client = boto3.client('s3')
bedrock_client = boto3.client('bedrock-runtime')
# BedrockのモデルID設定
MODEL_ID = "anthropic.claude-3-haiku-20240307-v1:0"
def lambda_handler(event, context):
# イベントからバケット名とオブジェクトキーを取得
bucket_name = event['Records'][0]['s3']['bucket']['name']
object_key = event['Records'][0]['s3']['object']['key']
try:
# S3から通話内容のJSONファイルを取得
response = s3_client.get_object(Bucket=bucket_name, Key=object_key)
file_content = response['Body'].read().decode('utf-8')
conversation_data = json.loads(file_content)
# 会話内容を一文の要約プロンプトとしてBedrockに送信
summary = summarize_conversation_with_bedrock(conversation_data)
# 要約結果を出力
print("要約結果:", summary)
return {
'statusCode': 200,
'body': json.dumps('Summary successfully generated.')
}
except ClientError as e:
print(f"Error fetching object from S3: {e}")
return {
'statusCode': 500,
'body': json.dumps('Error processing conversation data.')
}
def summarize_conversation_with_bedrock(conversation_data):
# 会話内容から一文の要約用プロンプトを生成
transcript = conversation_data.get('Transcript', [])
conversation_text = "\n".join([f"{item['ParticipantId']}: {item['Content']}" for item in transcript])
prompt = (
f"以下の会話を、顧客対応の要点と詳細な情報が含まれるように一文で要約してください。"
f"会話の中で重要なやり取りや背景が伝わるようにし、不要な説明や前置きは含めないでください:\n\n"
f"{conversation_text}\n\n要約:"
)
# Bedrockのリクエストボディ作成
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4000,
"messages": [{"role": "user", "content": prompt}]
})
try:
# Bedrockの呼び出し
response = bedrock_client.invoke_model(
body=body,
modelId=MODEL_ID
)
# Bedrock呼び出し結果の抽出
response_body = json.loads(response.get('body').read())
summary = response_body["content"][0]["text"]
return summary
except ClientError as e:
print(f"Error calling Bedrock API: {e}")
raise
通話終了後に通話内容がS3に保存された際、このLambda関数を自動で実行するために、S3トリガーを使用します。
AWS マネジメントコンソールで S3を開き、「プロパティ」を選択します。
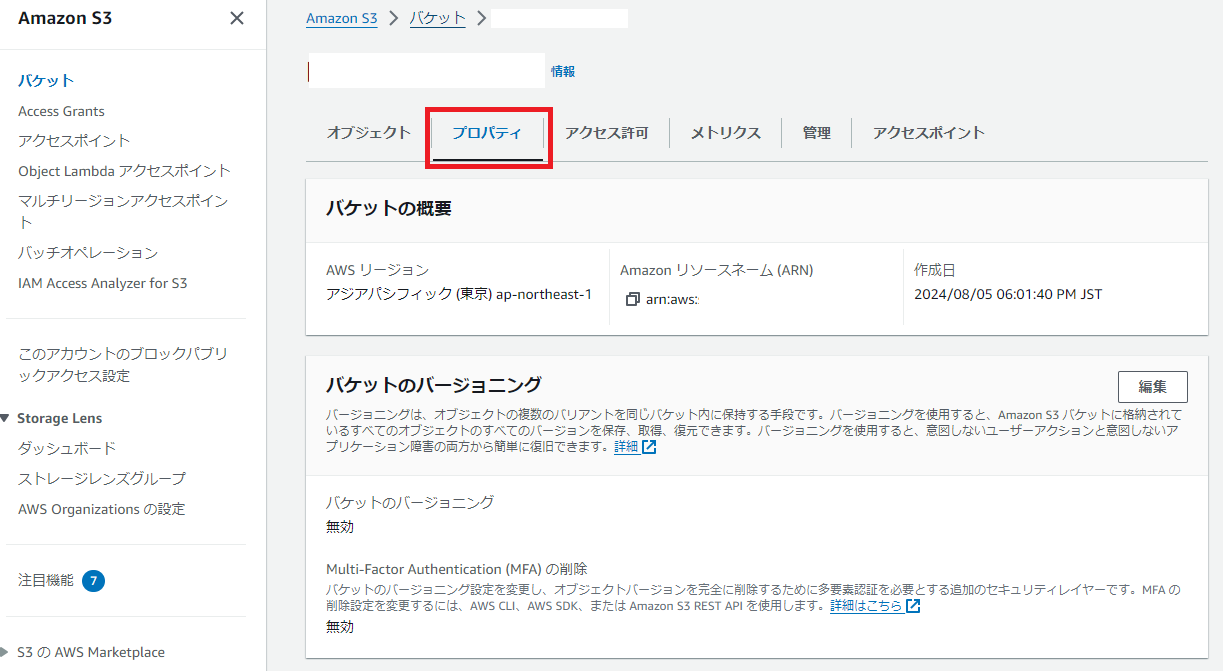
「イベント通知を作成」からイベント名を入力して、イベントタイプを「すべてのオブジェクト作成イベント」を選択します。
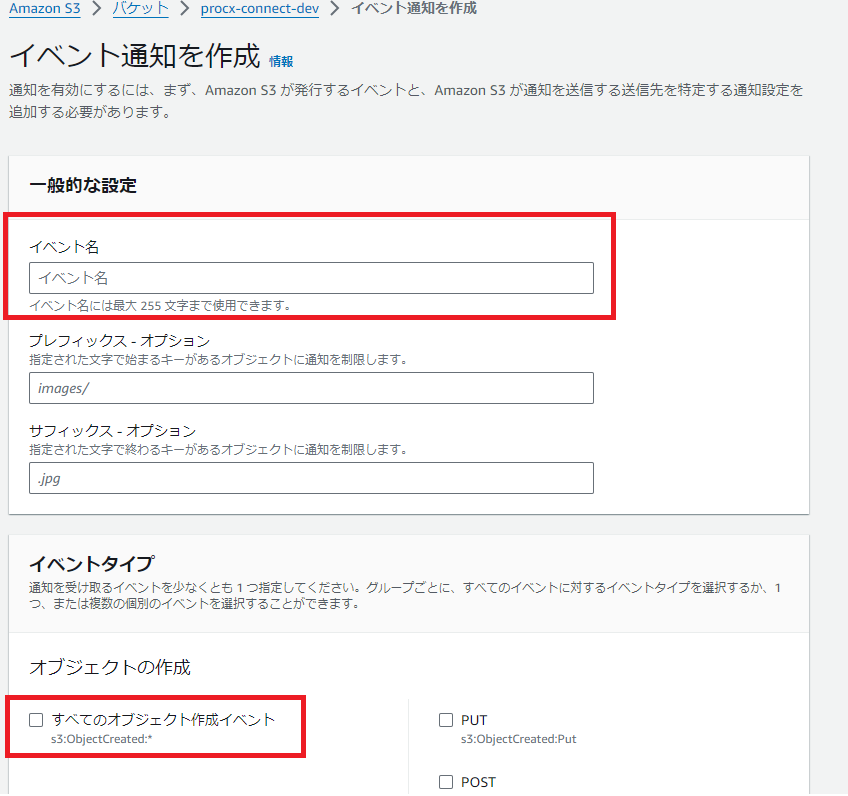
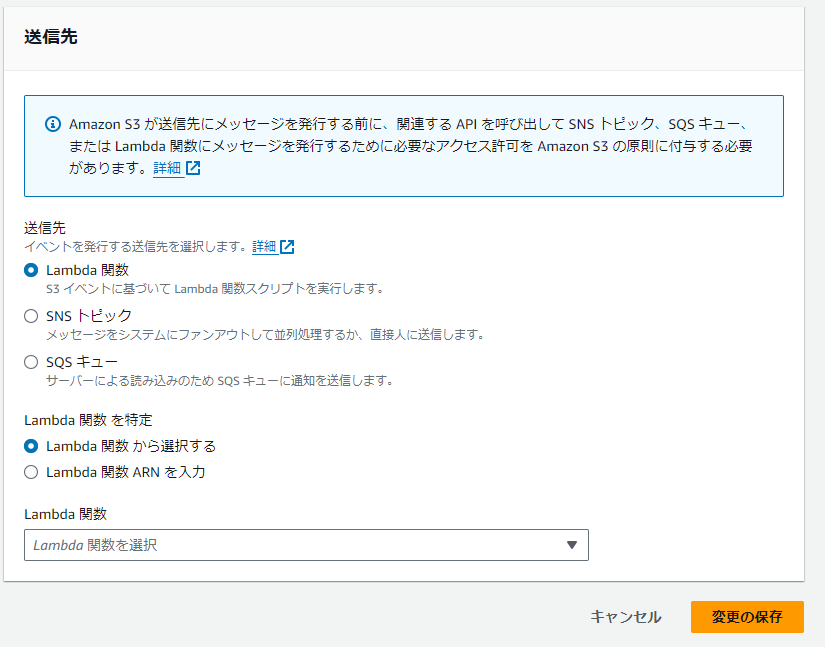
送信先を先ほどの作成したLambda関数に設定して、「変更の保存」を選択しますとS3イベントトリガーが作成されます。
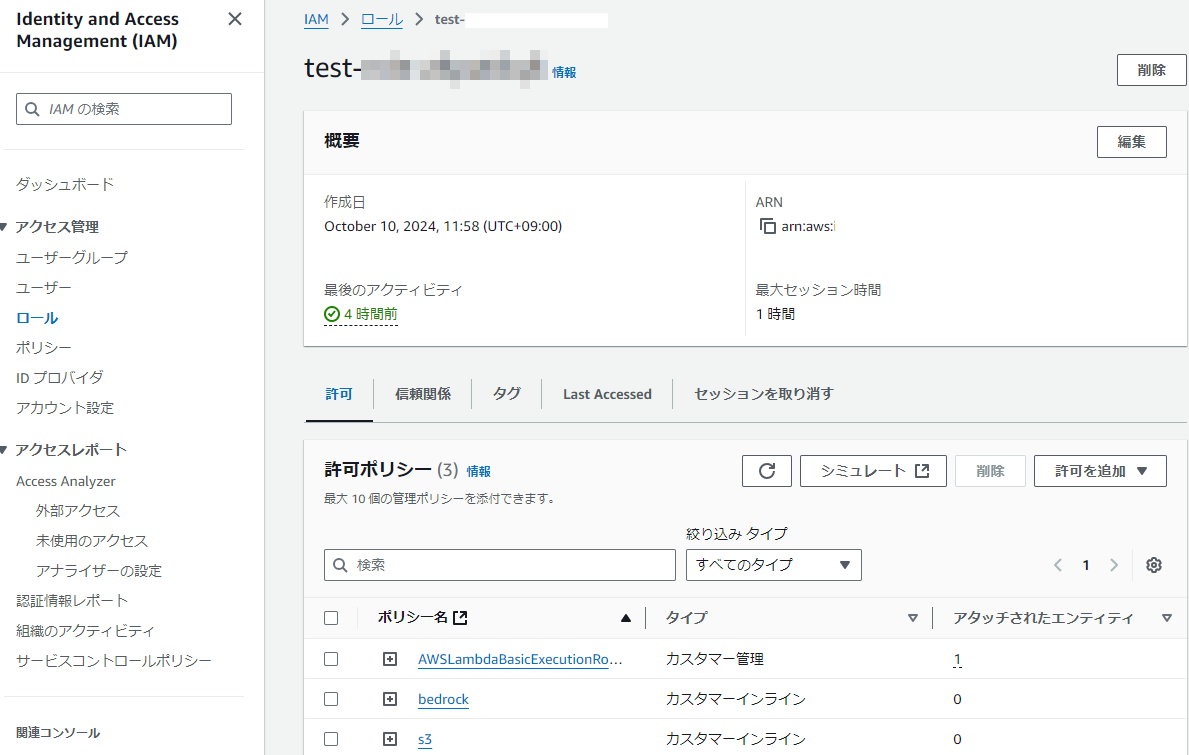
最後はLambda関数のロールにS3とBedrockにアクセスできるためのポリシーを付与します。
通話内容のAI要約機能はこれで完了となりました。通話終了後、Lambdaから要約内容が出力されます。

要約内容の出力フォーマットや詳細の粒度は、LLMのプロンプト等を調整することで変更が可能です。ぜひ試してみてください!
通話内容の要約が生成された後、この要約内容をKintoneアプリへ自動的に登録する手順を説明します。
登録するためのKintone APIのtokenを発行します。
Kintoneアプリの設定画面から、「APIトークン」を選択します。
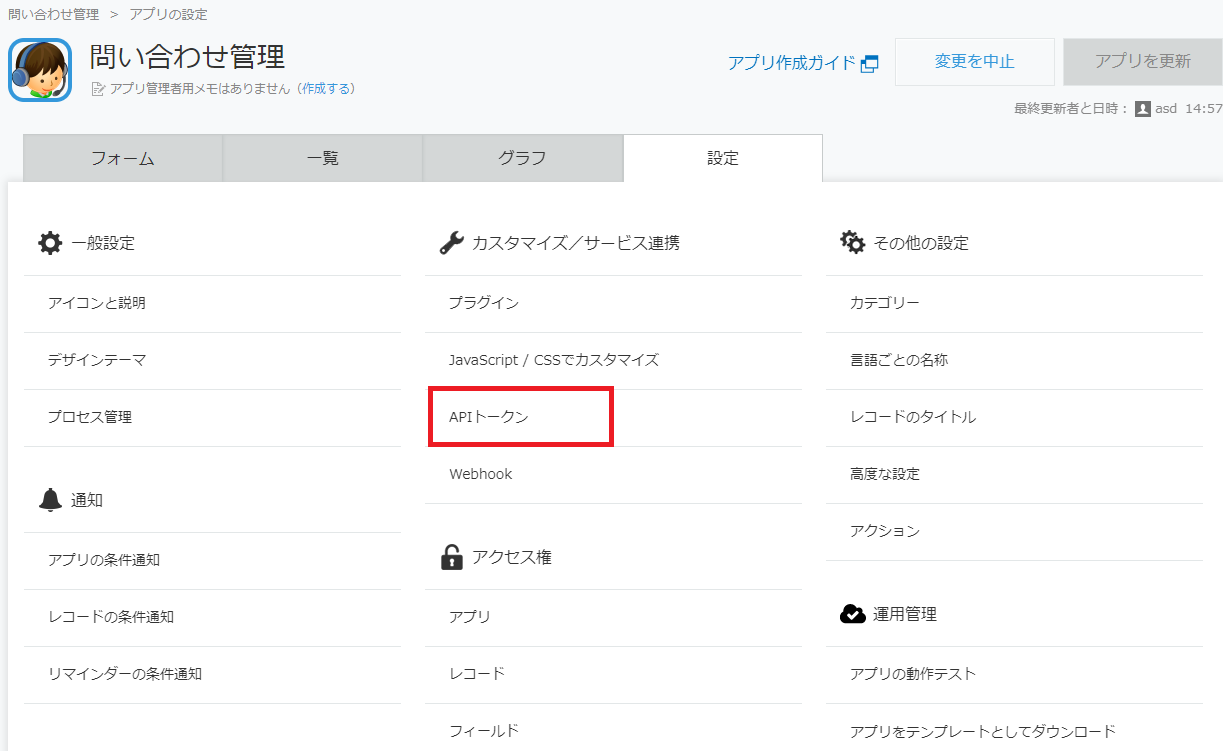
「生成する」ボタンをクリックするAPI用トークンが発行されます。アクセス権限「レコード閲覧」、「レコード編集」にチェックを入れて「保存」を選択します。
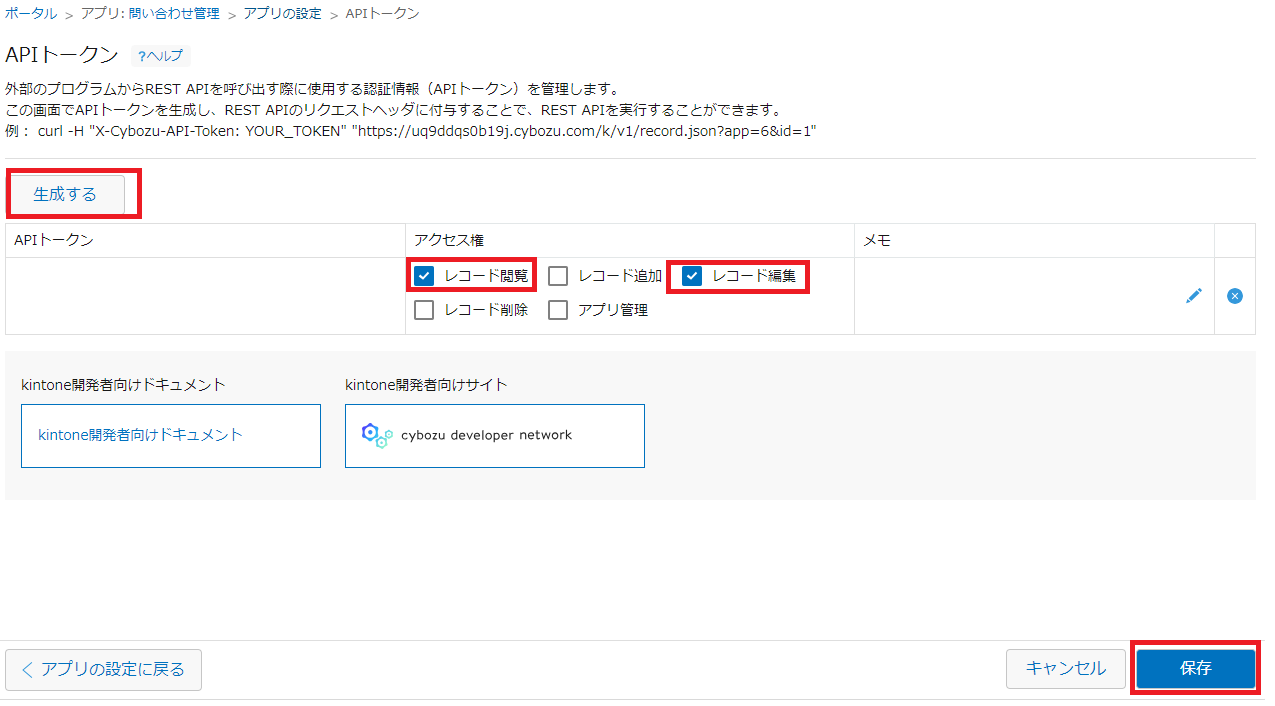
最後はアプリの設定TOP画面から「アプリを更新」をクリックして変更を反映します。
これでKintoneアプリに登録するためのAPI用の認証情報が作成できました。5-3.で作成したLambda関数に、以下のKintone API登録処理を追加することで、問い合わせ履歴の自動登録が可能となります。
(以下は一例です。詳細なKintone APIの登録方法については公式ドキュメントをご確認ください。)
import requests
import json
AI要約処理・・・
app_id = < アプリID>
api_token = <APIトークン>
subdomain = <Kintoneドメイン>
# APIエンドポイントとヘッダー設定
url_get_records = f"https://{subdomain}.cybozu.com/k/v1/records.json"
url_update_record = f"https://{subdomain}.cybozu.com/k/v1/record.json"
headers = {
"X-Cybozu-API-Token": api_token,
"Content-Type": "application/json"
}
query = '最後のコンタクトID = "<AmazonConnect通話のコンタクトID>"'
get_data = {"app": app_id, "query": query, "fields": ["レコード番号", "最後のコンタクトID", "対応詳細"]}
try:
response_get = requests.get(url_get_records, headers=headers, json=get_data)
response_get.raise_for_status()
records = response_get.json().get("records", [])
if not records:
print("該当するコンタクトIDのレコードが見つかりません。")
exit()
record_id = records[0].get("レコード番号", {}).get("value")
contact_id = records[0].get("最後のコンタクトID", {}).get("value")
current_subtable = records[0].get("対応詳細", {}).get("value", [])
new_subtable_entry = {
"value": {
"対応内容": {
"value": summary
},
"コンタクトID": {
"value": contact_id
}
}
}
current_subtable.append(new_subtable_entry)
update_data = {
"app": app_id,
"id": record_id,
"record": {
"対応詳細": {
"value": current_subtable
}
}
}
response_update = requests.put(url_update_record, headers=headers, json=update_data)
response_update.raise_for_status()
except requests.exceptions.RequestException as e:
print(f"リクエストエラーが発生しました: {e}")
except ValueError:
print("レスポンスをJSONとして解析できませんでした。")
お疲れ様でした!以上で設定手順は完了です。最後は実際に電話をかけて、問い合わせ履歴の自動登録を確認してみましょう!
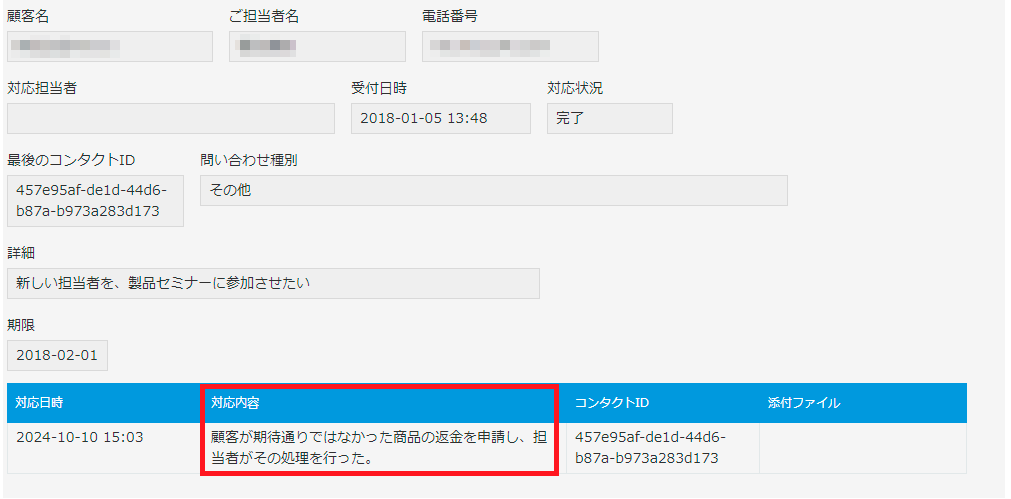
AIが要約した問い合わせ内容が無事にKintoneに登録されていますね!これで、通話内容のAI自動要約と問い合わせ内履歴の自動登録が実現しました。ぜひ、この機能を活用して業務の効率化にお役立てください!
今回は、Amazon ConnectとKintoneを連携し、コンタクトセンター業務の効率化を図る方法について解説しました。このような仕組みを活用することで、顧客対応の迅速化や業務の負担軽減が期待できます。また、他にもさまざまな連携方法やカスタマイズが可能ですので、Amazon Connectの活用や電話業務の効率化・高度化に関心がある方はNTT東日本にお気軽にご連絡ください。






相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

