
AWSサポートプランを徹底解説!サポート範囲やプランの違い、問い合わせ方法まで解説します
AWSのサポートプランは「ベーシック」、「開発者(デベロッパー)」、「ビジネス」、「エンタープライズ」の4種類に分かれております。本コラムでは、AWSのサポートプランの概要からプランごと違いや選び方について徹底解説します。
![]()


 |
こんにちは。エンジニアの森と申します。 |
|---|
Amazon Web Services(AWS)のサーバーレスストリーミングデータサービスでるKinesis Data Streamsは、2023年11月22日にリソースベースのポリシーがサポートされました。
これにより、柔軟なアクセスコントロールやクロスアカウントアクセスの簡素化が可能となるなど、さらに便利なサービスとなりました。
このKinesis Data Streamsには、拡張ファンアウトコンシューマー(コンシューマー)という機能があり、通常のKinesis Data Streamsよりも高いスループットを発揮することができます。
コンシューマーの詳細は、AWS公式webサイトをご確認ください。
コンシューマーを使用した場合もリソースベースのクロスアカウントアクセスをすることは可能になっていますが、少し特殊な設定が必要になるため、若干分かりづらくなっています。
そこで本記事では、Kinesis Data Streamsの拡張ファンアウトコンシューマーをリソースベースのクロスアカウントアクセスを設定する方法について画像付きで解説していきます。
クラウド活用に関するさまざま情報をお届けするメルマガを毎週配信しておりますので、ぜひこの機会にご登録ください。

目次:
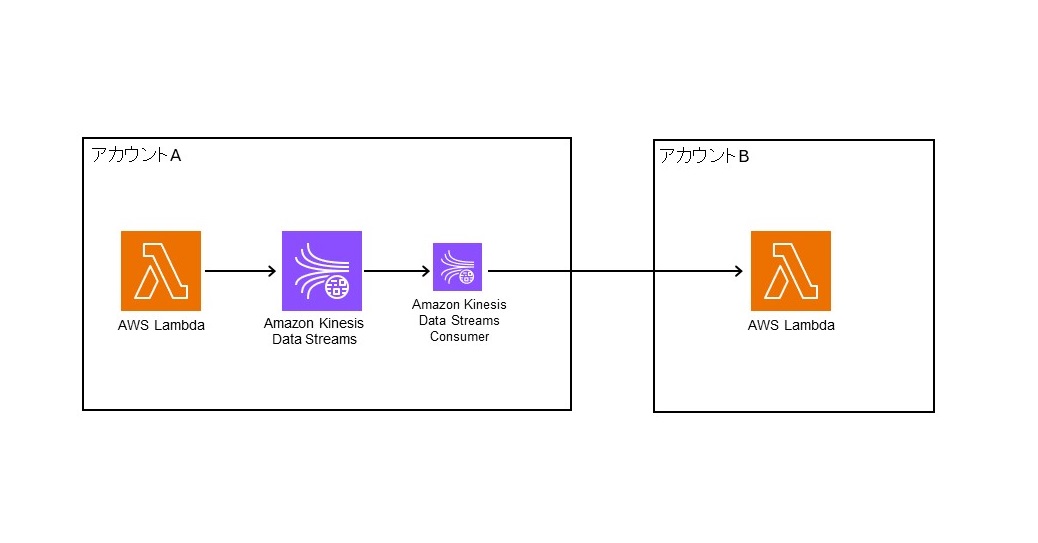
今回構築するアーキテクチャは画像の通りとなります。
まず、データ発行元のアカウントAに構築したLambdaからテキストデータをKinesis Data Streamsにストリーミングします。
ストリーミングされたデータをコンシューマー経由でデータ受信側のアカウントBのLambdaで受け、結果を表示するといった簡単なアーキテクチャとします。
Kinesis Data Streams本体とコンシューマーはどちらもデータ発行元であるアカウントAに構築することが重要です。
それでは実際に上記アーキテクチャの実装を解説していきますが、AWSアカウントの作成やAWS CLIの設定は済んでいるものとして進めていきますので事前に設定をお願いいたします。
まずは、Kinesis Data Streamsとコンシューマーを作成しなければ始まりませんので作成していきます。
Kinesis Data Streamsとコンシューマーは、アカウントAで作成します。
AWSマネジメントコンソールにアクセスし、Kinesisを検索→ダッシュボードを表示します。
「データストリームを作成」ボタンをクリックします。
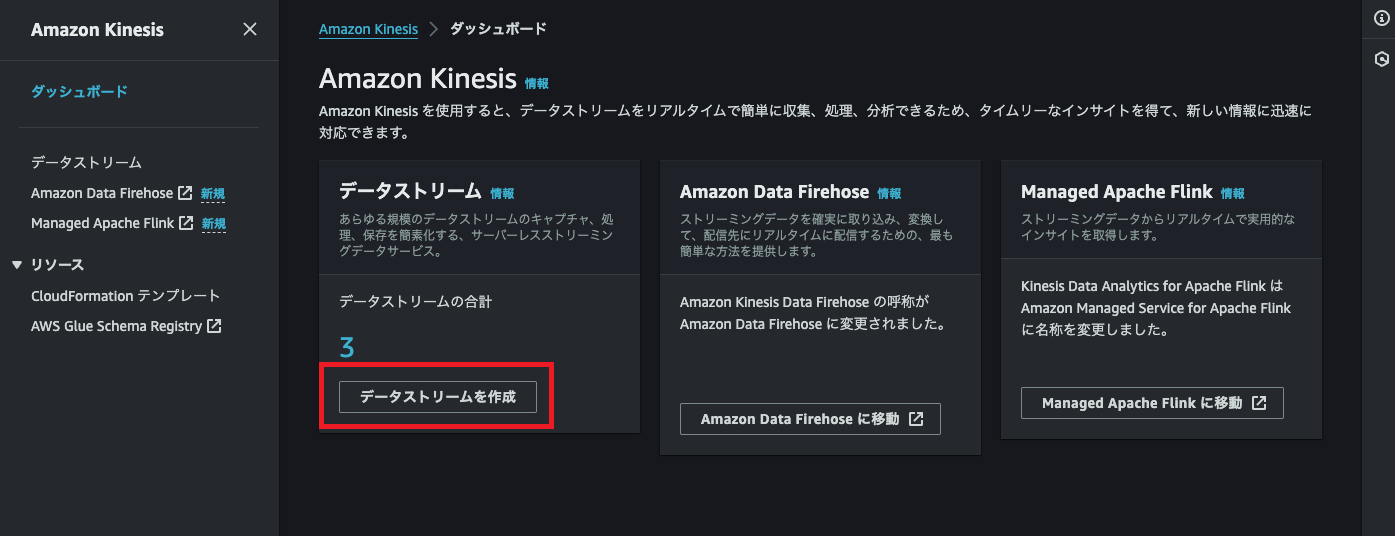
お好きなデータストリーム名を入力し、「データストリームの作成」ボタンをクリックします。
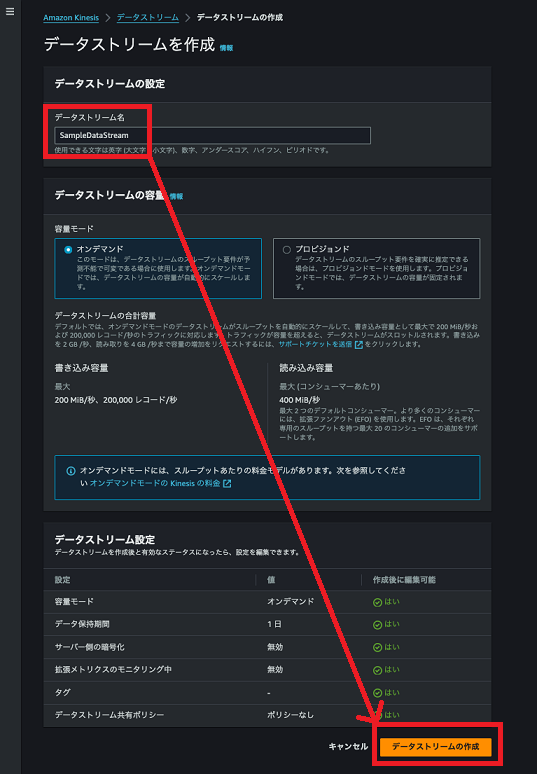
データストリームが正常に作成されましたの表示が出ればOKです。
コンシューマーを作成していきます。
コンシューマーはマネジメントコンソールからは作成できないようなのでAWS CLIを使用します。
CLIに以下のコマンドを実行します。
aws kinesis register-stream-consumer --stream-arn arn:aws:kinesis:ap-northeast-1:[AccountID]:stream/SampleDataStream --consumer-name SampleDataStreamConsumer
AccountIDの部分は置き換えてください。
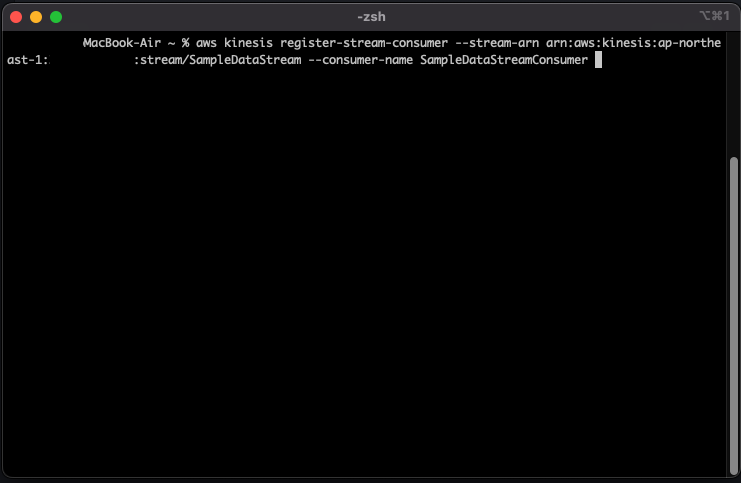
実行後、以下のような表示になるはずです。
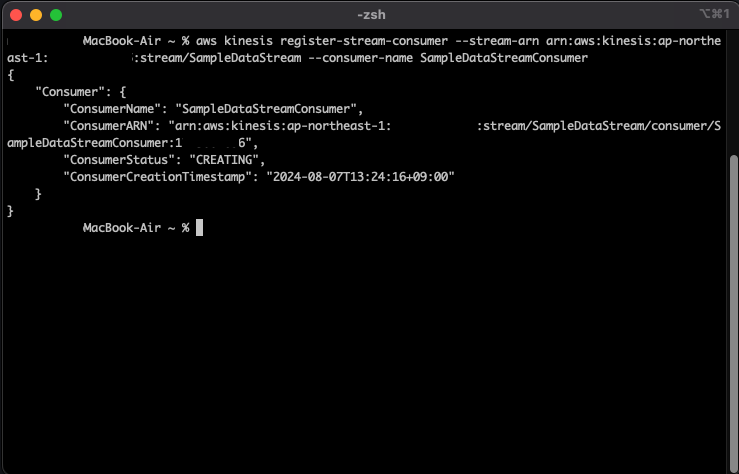
マネジメントコンソールからもコンシューマーが作成され、登録ステータスがアクティブになっていることを確認できます。
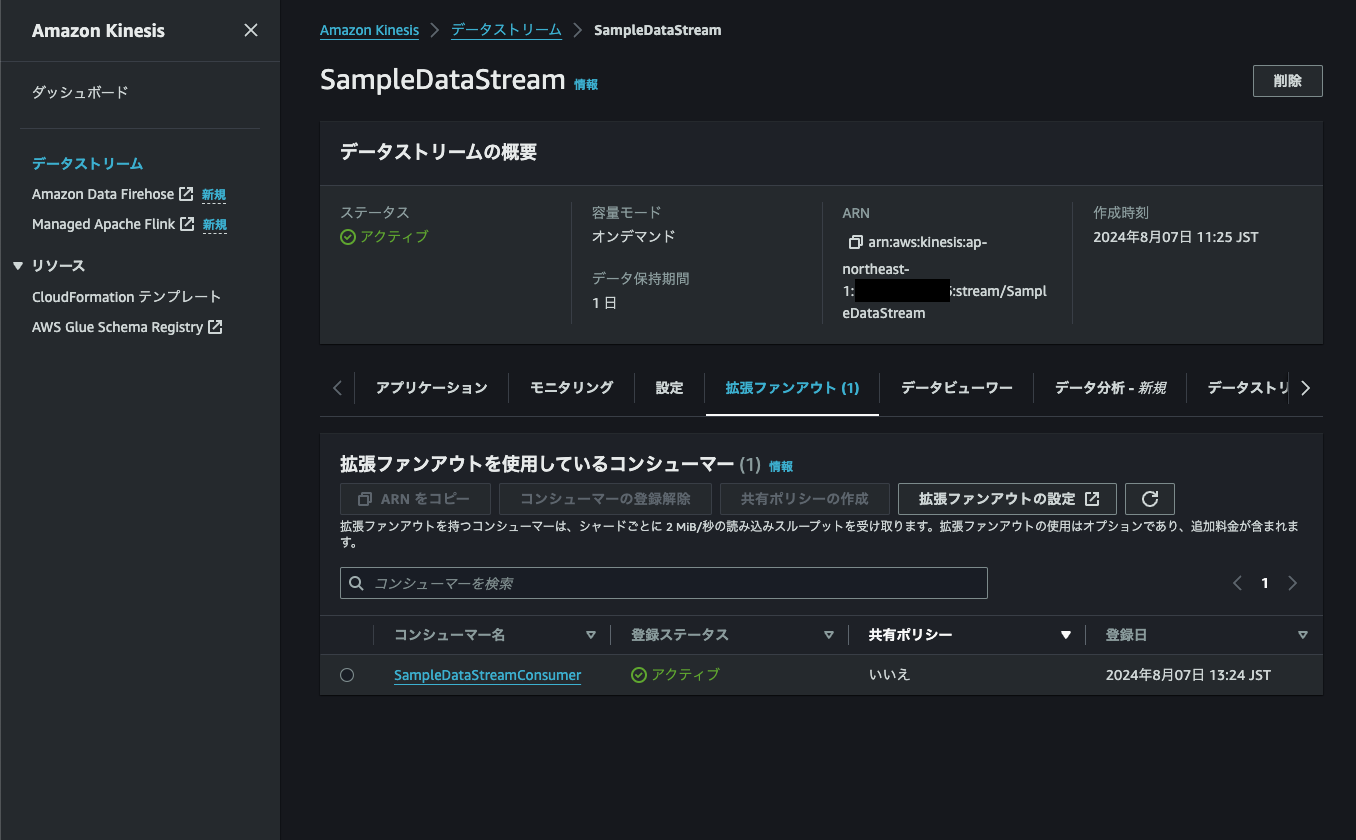
コンシューマーをクロスアカウントアクセスするための設定を行います。
コンシューマーをクロスアカウントアクセスするには、Kinesis Data Streamsとコンシューマーの両方に設定を行う必要があります。
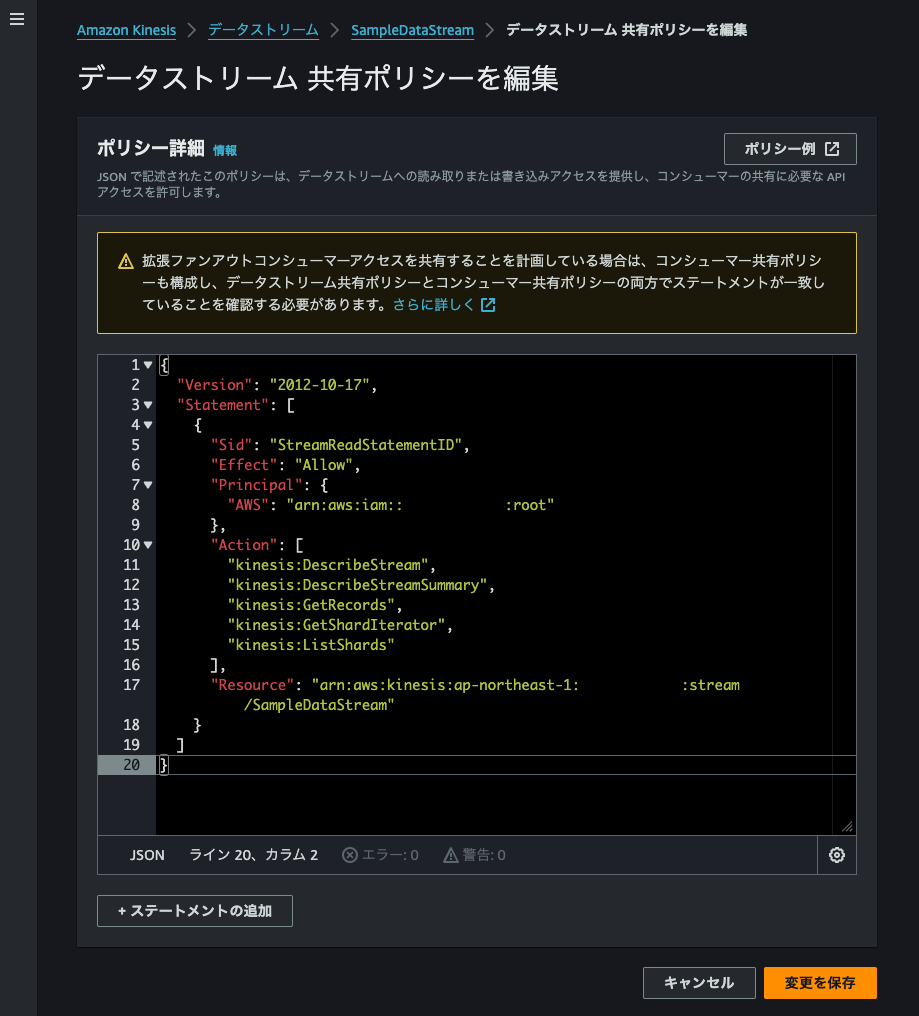
まず、2-1で作成したKinesis Data Streamにアクセスし、データストリーム共有タブを選択→ポリシーの作成を選択します。
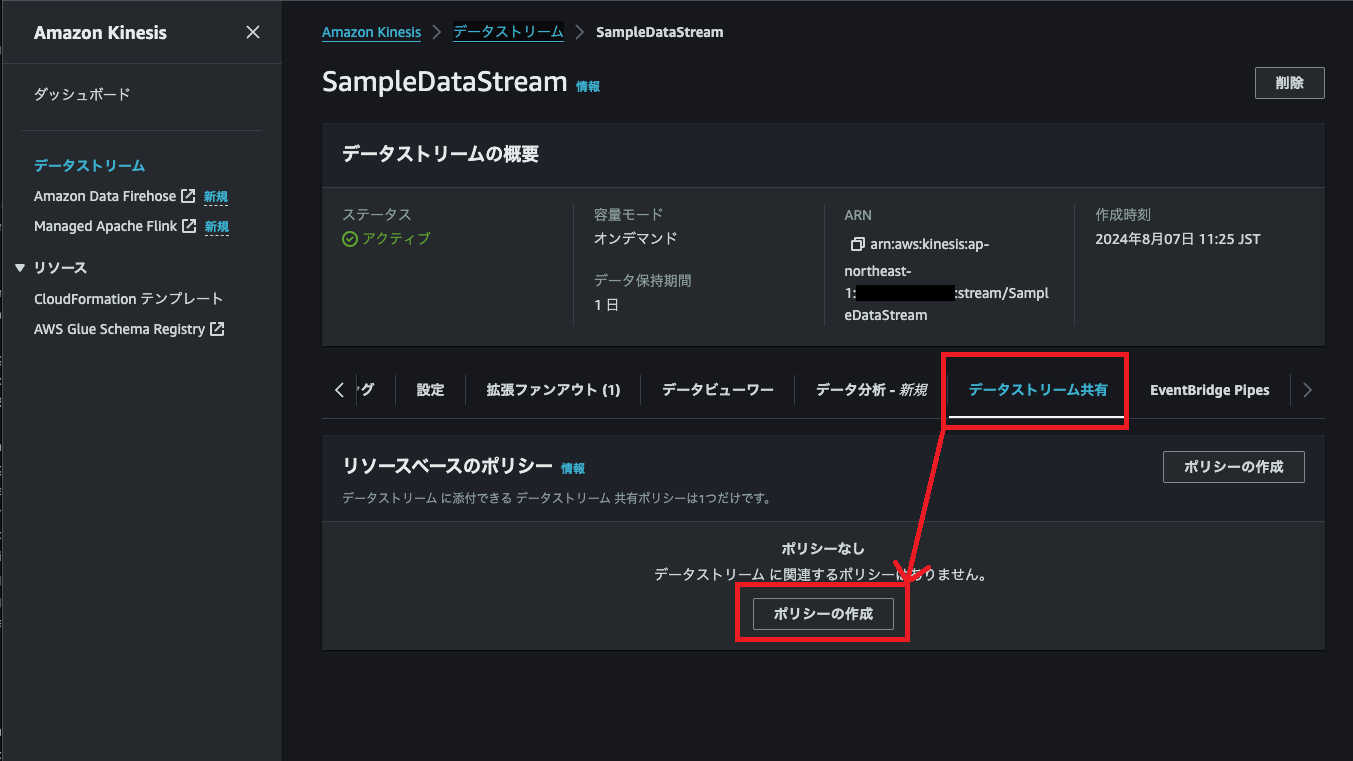
共有ポリシーを入力します。今回は、JSON形式で入力しました。
Actionには、これら5つを入力します。
入力終了後、保存して画面を閉じます。
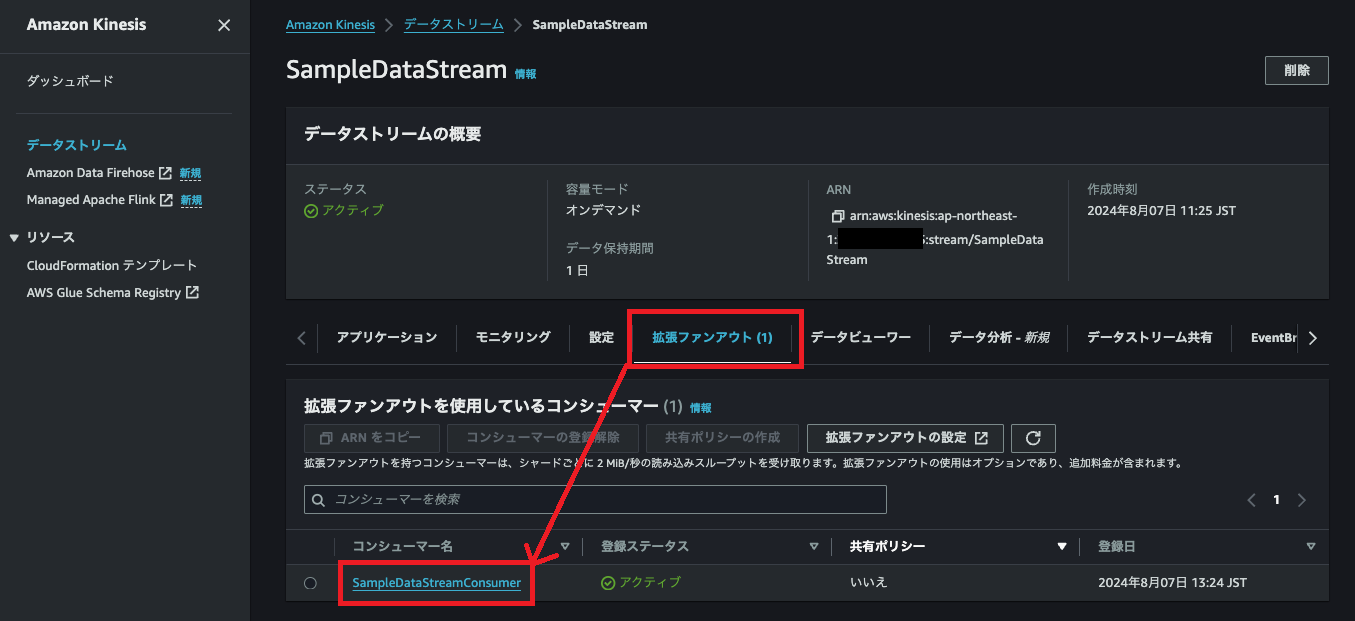
次にコンシューマーの共有設定です。
作成したKinesis Data Streamsの詳細画面の拡張ファンアウトタブ→作成したコンシューマーを選択して詳細画面に遷移します。
コンシューマー共有タブ→ポリシーの作成を選択します。
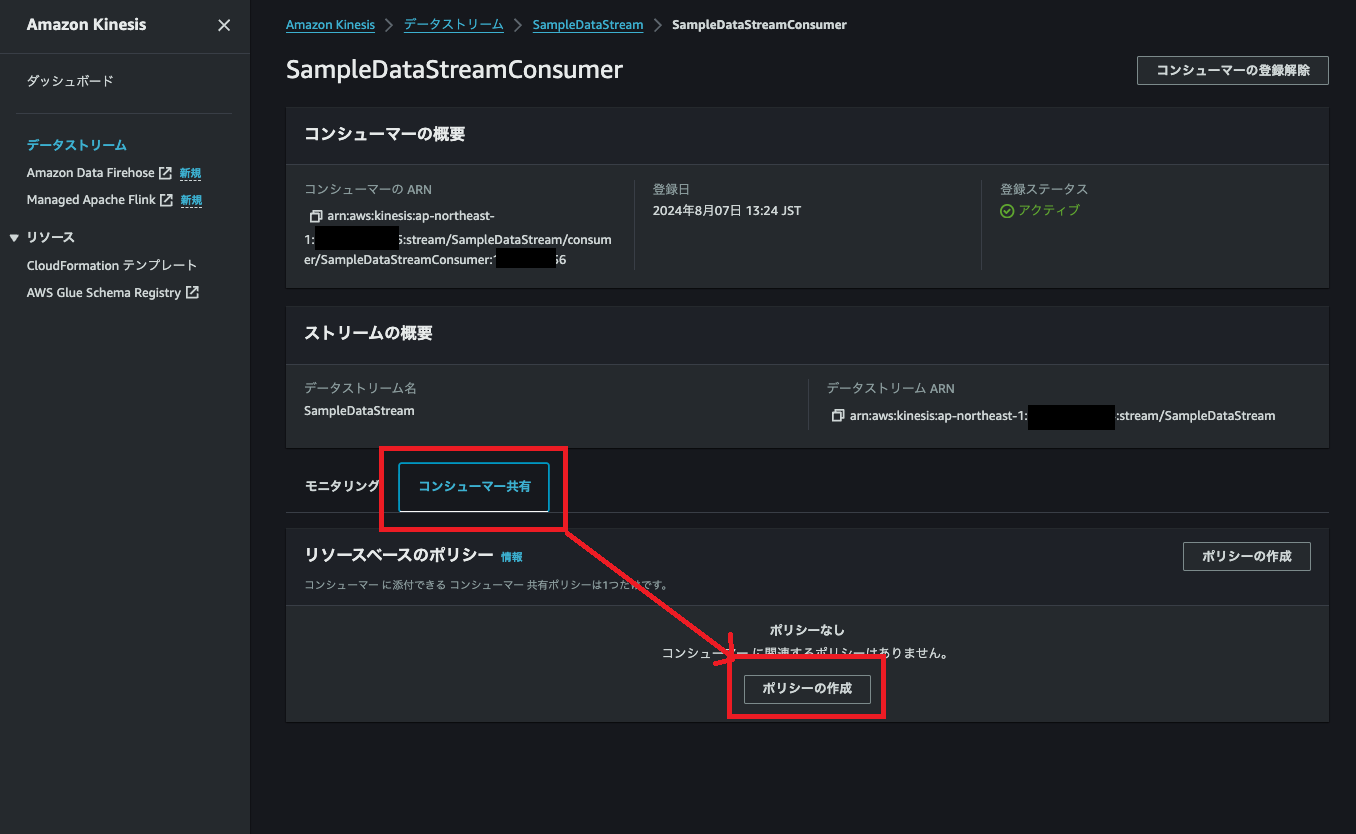
ここでもJSON形式で入力しています。
Actionには、これら2つを入力します。
入力後、ポリシーの作成をクリックします。
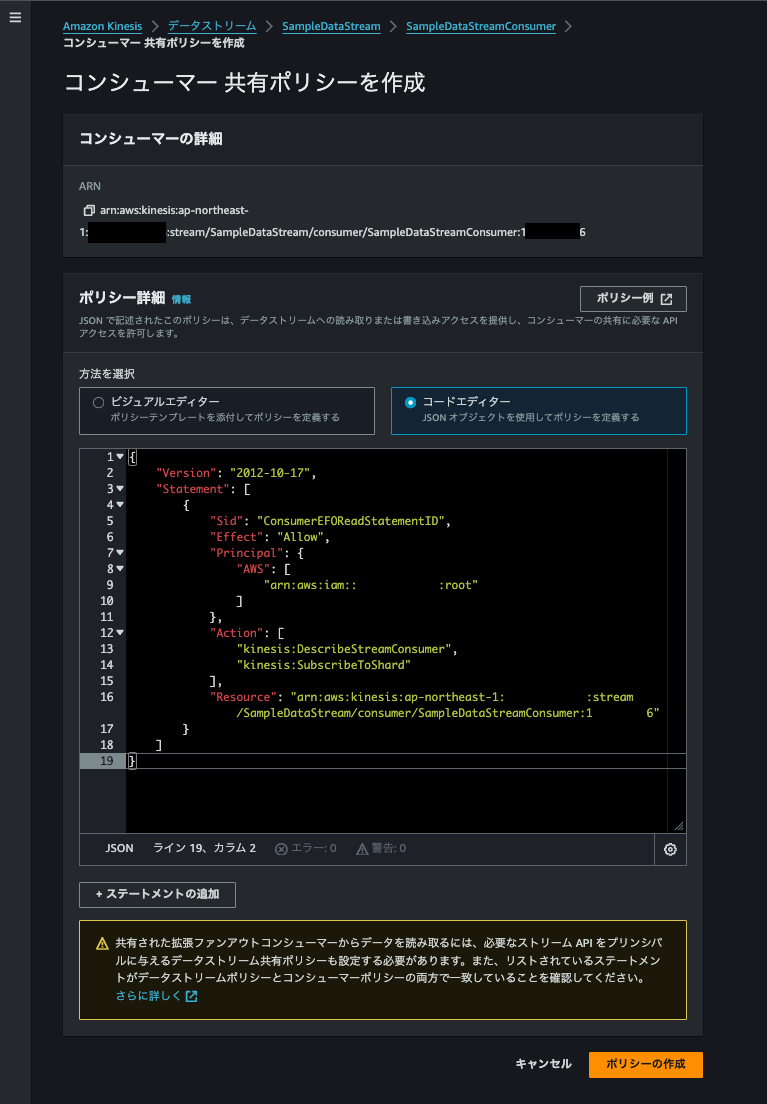
これでクロスアカウントアクセスのポリシー設定は完了です。
ストリーミングデータを発行するためのLambda関数を作成します。
Pythonを用いて10個のレコードをKinesis Data Streamsにputするコードとなります。
作成したKinesis Data Streamsの名前に合わせてSTREAM_NAMEを適宜変更ください。
import json
import boto3
import datetime
# Kinesis client
kinesis_client = boto3.client('kinesis')
# Kinesis stream name
STREAM_NAME = 'SampleDataStream'
def generate_test_data(i):
return {
'message': f'私は、NTT東日本の森です。{i}',
'timestamp': datetime.datetime.now().isoformat()
}
def lambda_handler(event, context):
# Number of records to put
num_records = 10
records = []
for i in range(num_records):
data = generate_test_data(i)
record = {
'Data': json.dumps(data),
'PartitionKey': str(i)
}
records.append(record)
# Put records to Kinesis Data Stream
response = kinesis_client.put_records(
Records=records,
StreamName=STREAM_NAME
)
# Check if all records were put successfully
failed_record_count = response['FailedRecordCount']
if failed_record_count > 0:
print(f"Failed to put {failed_record_count} records.")
else:
print(f"Successfully put {num_records} records to Kinesis Data Stream.")
return {
'statusCode': 200,
'body': json.dumps('Test data put to Kinesis Data Stream')
}
Lambda関数のロールにはAmazonKinesisFullAccessのポリシーを追加しておきます。
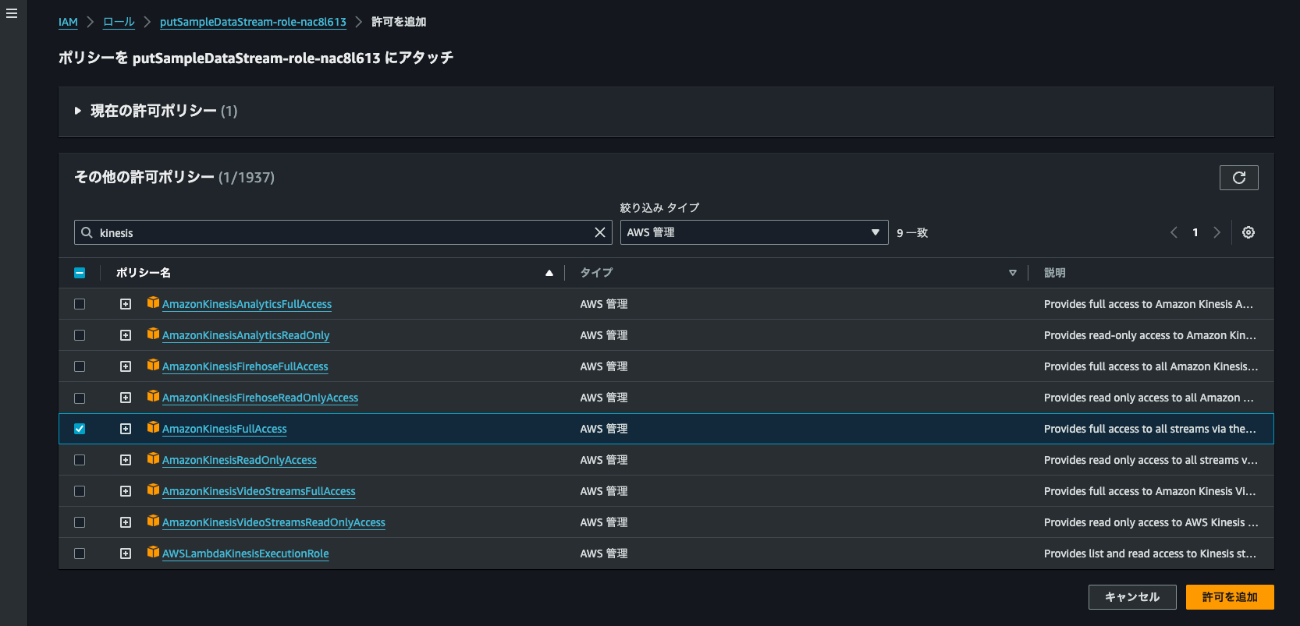
アカウントBにてデータを受信し、Print文で表示する簡単なLambda関数を作成します。
こちらもPythonで作成しています。
import json
import base64
import boto3
def lambda_handler(event, context):
kinesis_client = boto3.client('kinesis')
for record in event['Records']:
payload = base64.b64decode(record["kinesis"]["data"])
try:
data = json.loads(payload)
print(f"Received data: {data}")
if 'temperature' in data:
temperature = data['temperature']
print(f"Temperature: {temperature}")
except json.JSONDecodeError:
print(f"Failed to parse JSON: {payload}")
continue
return {
'statusCode': 200,
'body': json.dumps('Successfully processed {} records'.format(len(event['Records'])))
}
作成したLambda関数のロールにAWSLambdaKinesisExecutionRoleポリシーを追加しておきます。
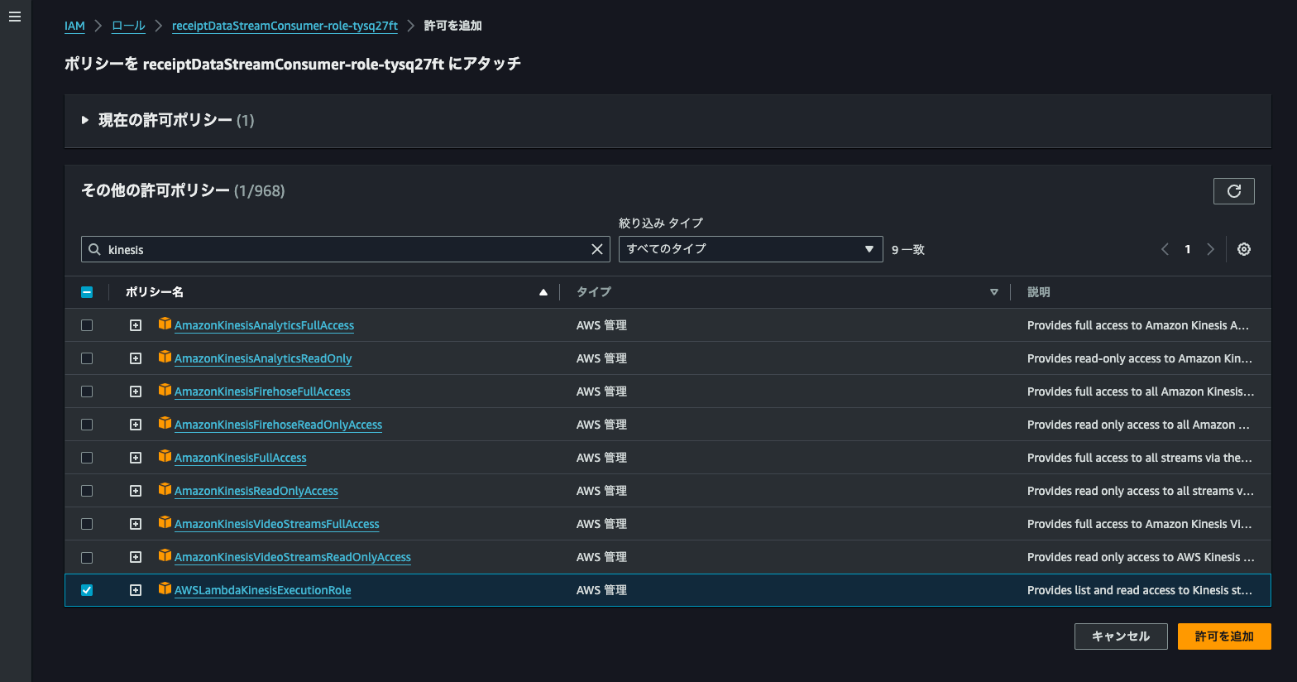
トリガーにコンシューマーを指定します。
プルダウンでKinesisを指定し、KinesisストリームのボックスにアカウントAで作成したコンシューマーのARNを入力します。
トリガーをアクティブ化のチェックが入っていることを確認します。(デフォルトでチェックが入っているはずです)
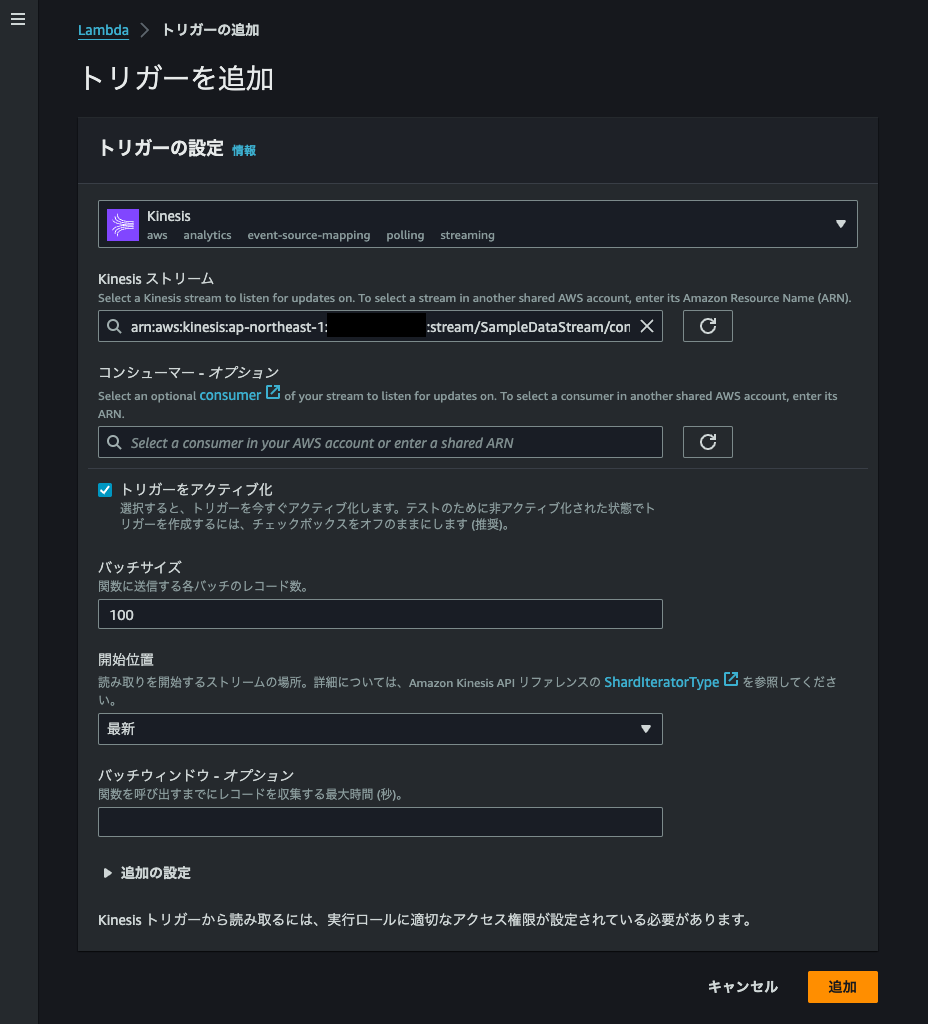
これですべての準備は完了となります。
実際に動かしてみます。
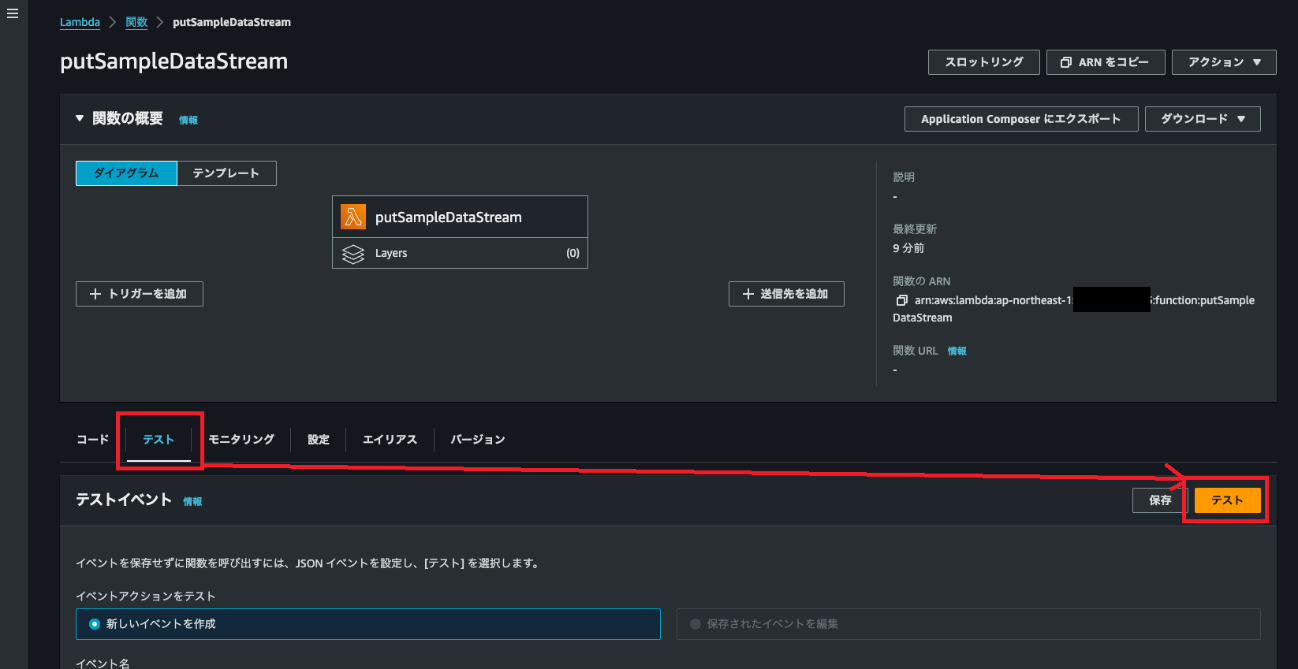
アカウントAに作成したLambda関数のテストを実施します。
この関数はパラメータは必要ありませんのでそのままテストボタンを押します。
アカウントBのLambda関数のCloudWatch Logsを確認してみるとこのようにログが表示されていることで、クロスアカウントアクセスができていることが確認できます。
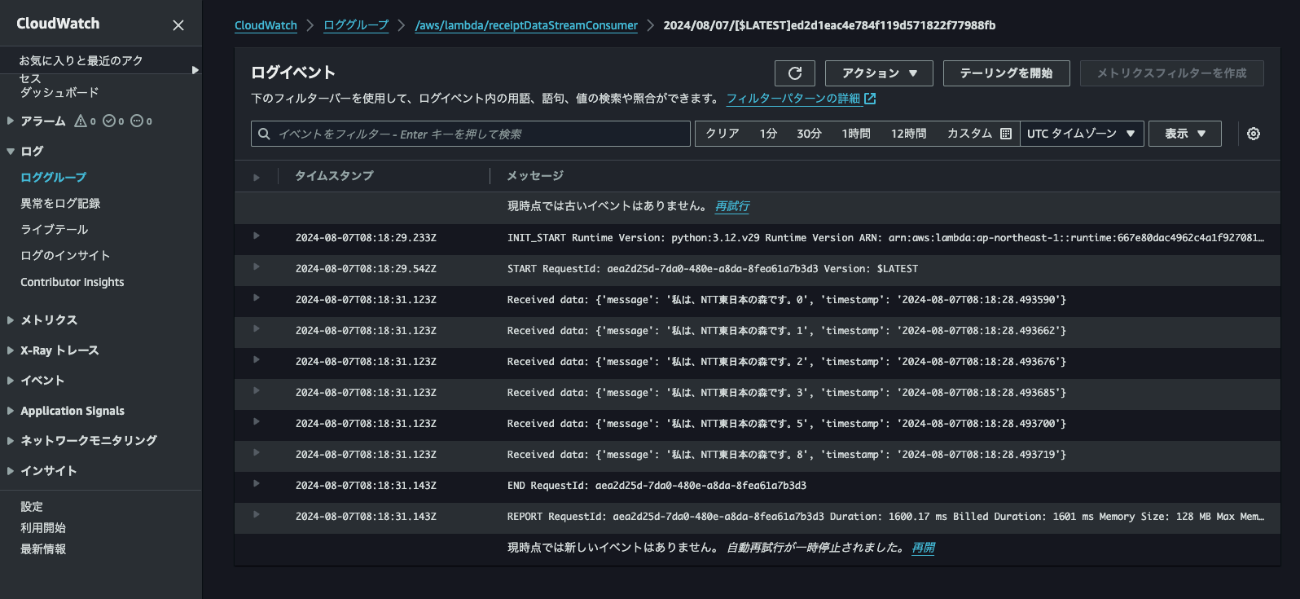
本記事では、Kinesis Data Streamsの拡張ファンアウトコンシューマーのリソースベースのクロスアカウントアクセスの実装例をご紹介しました。
今回の構成によりLambdaは、Kinesis Data Streamsに発行されたデータをコンシューマー経由で受信することができるようになります。
コンシューマーを使用することでKinesis Data Streams単体よりも厳しい要件にマッチさせることができますのでぜひお試しください。
NTT東日本は、今回ご紹介したAWSを始めとしたパブリッククラウドを用いたソリューション開発に力を入れています。
クラウド導入に興味がある、検討しているという方はぜひお問い合わせください。
Amazon Web Services(AWSおよび記載のあるAWSの各サービス名)は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。






相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。

