
Amazon Connect Contact Lensで英語を始めとした多言語問い合わせ対応を検証してみた
本コラムでは、Amazon Connect Contact Lensの機能・料金体系について解説、また多言語での問い合わせを想定した音声文字起こし機能の精度を検証してみましたのでご紹介します。
![]()


こんにちは、田口です。
本コラムでは、AIエージェントの基礎からAmazon Bedrock Agentsの活用方法について解説していきます。

AIエージェントとは、AWS公式ドキュメントでは、以下のように説明されています。
“ 人工知能 (AI) エージェントは、環境と対話し、データを収集し、そのデータを使用して自己決定タスクを実行して、事前に決められた目標を達成するためのソフトウェアプログラムです。”
つまり、AIエージェントとは人から受けた命令を達成するために、必要なタスクを自己決定して、最適なアクションを独自で判断し実行する自立型のAIをさします。
例えば、トレンドの洋服を購入したいという指示をAIエージェントに与えたとき、AIエージェントはファッション関連のWebサイト、SNSなどをスキャンして最新のトレンド情報を収集し、トレンドアイテムの一覧や金額、ショップのリンクを提供します。またユーザーの好み(ブランドや色など)の情報を得ている場合、その情報を基にパーソナライズされた洋服の提案をします。
もしユーザーの事前情報がない場合は、AIエージェントからユーザーに対して質問を実施し、好みを把握して洋服を提案してくれます。
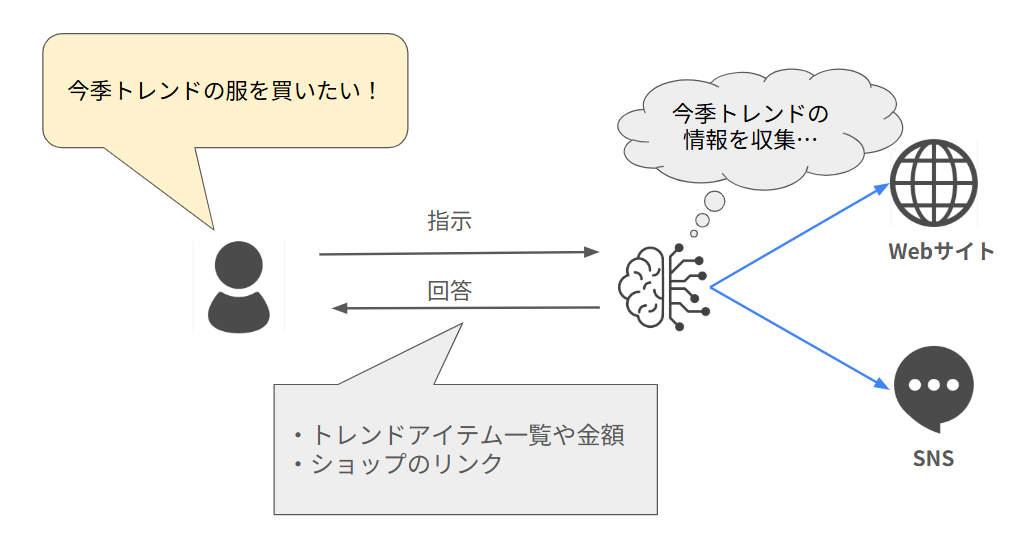
対話型AI(ChatGPTやBingなど)は人間のように自然言語で会話し、ユーザーからの質問に対して柔軟に回答することができますが、会話することを目的としているため、何かお願いしたい場合は、ユーザー側でタスクを検討し指示する必要があります。AIエージェントはユーザーから与えられたタスクを遂行するため、AI自身がタスクを判断して実行するという点が大きく異なっています。
前述の通り、AIエージェントはタスクを自己決定し、AI自身で実行します。そんなAIエージェントですが大まかには以下のような仕組みで動いています。
AIエージェントはユーザーから指示を受け取ると、最終的なユーザーへの回答が関連性高く有用なものとするため、タスクを計画し、タスクを分割してそれらを実行していきます。
AIエージェントは計画したタスクを正常に実行するためにWebや場合によっては社内情報などから情報収集を行います。
十分なデータが収集できたらAIエージェントはタスクを系統立てて順々に実行していきます。
Amazon Bedrock AgentsはAmazon Bedrockが提供する機能の一部です。
エージェント機能をフルマネージドで提供し、API呼び出しやRAG(Retrieval Augmented Generation)から情報を引き出し、取得した情報を用いてユーザーからの指示やタスクに返答することができます。
Amazon Bedrock Agentsはサーバレスかつフルマネージドで提供され、追加料金なしにAgentを使用することができます。またAgentに関しても様々なモデルを利用することができます。
またAgentはノーコードで簡単に作成でき、Lambda関数を利用してアクションを作りこむことで色々な用途に活用することができます。
参考:Amazon Bedrock Agents 自律型 AI の実現に向けて: 検討編 【Amazon Bedrock Series #04a】
では実際にAmazon Bedrock Agentsを利用して、Web上にあるサイトから情報を取得して内容を要約する仕組みを作成してみようと思います。
まずはAWSコンソールにアクセスし、Amazon Bedrockを開きます。
Amazon Bedrock が利用できるリージョンは以下にて参照することができますが、今回はオレゴンリージョンにて構築を進めていこうと思います。
Amazon Bedrock でサポートされている AWS リージョン
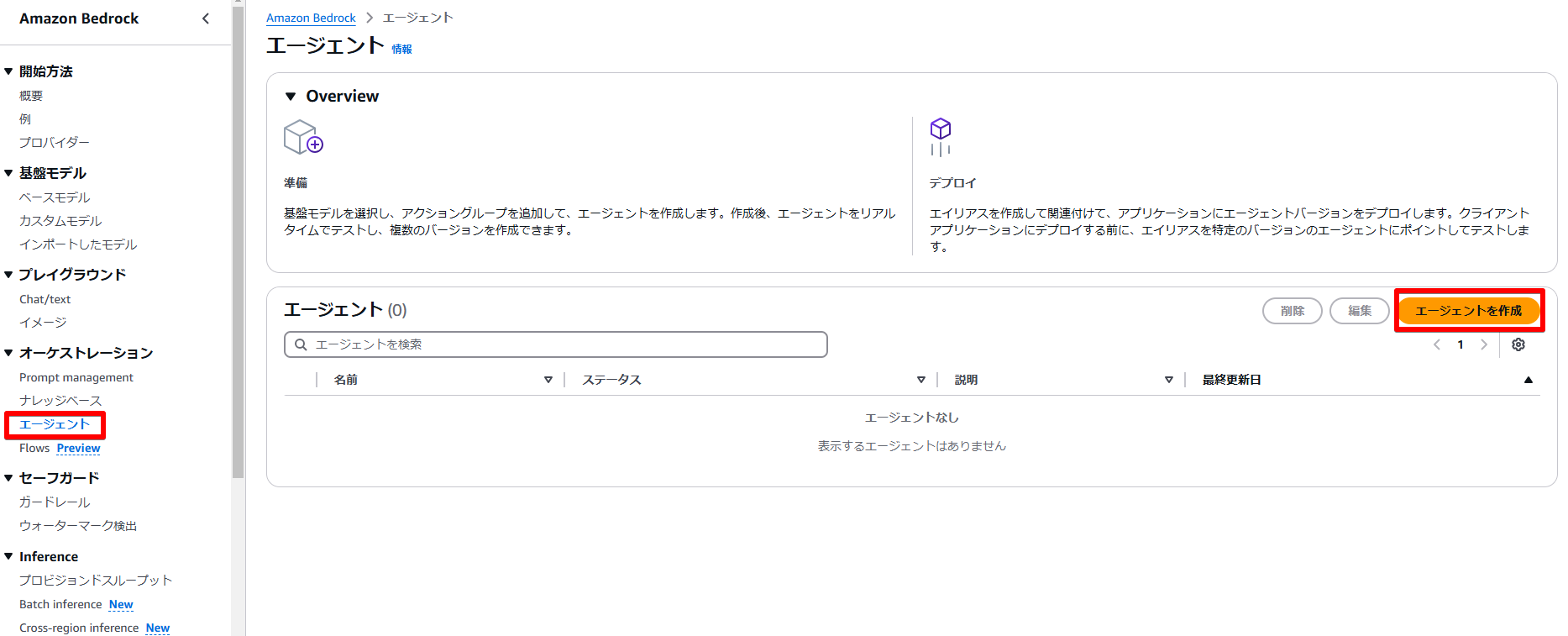
左側に表示されているメニューから「エージェント」を選び、「エージェントを作成」をクリックします。
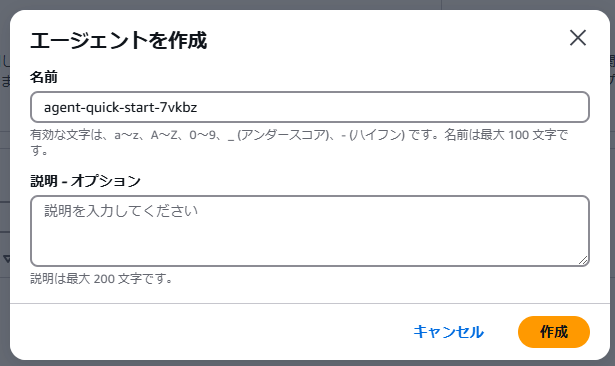
エージェント名は任意のものを入力し、「作成」をクリックします。
エージェントリソースロールは「新しいサービスロールを作成して使用」を選択します。
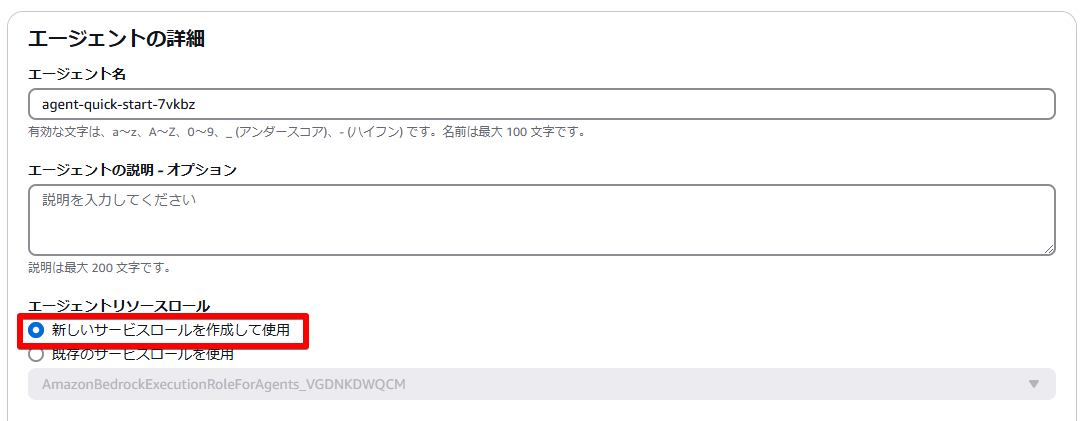
サービスロールには利用するモデルの許可設定が含まれます。
もし、こちらが利用したいモデルとなっていない場合は修正しましょう。
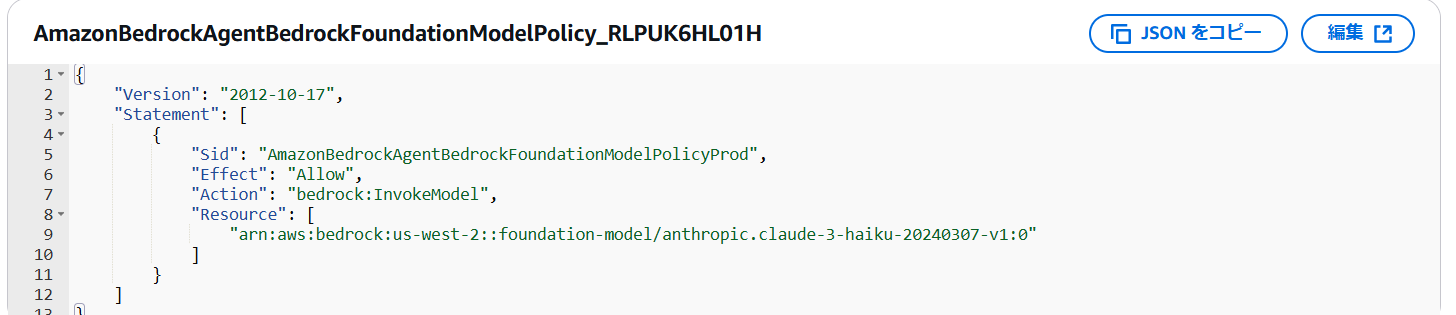
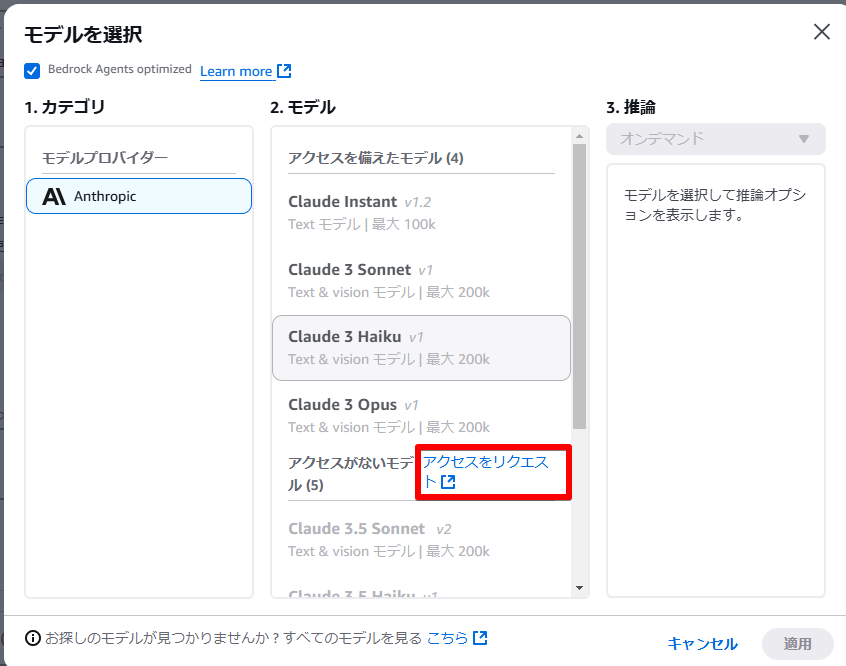
今回の検証では「Claude 3 Haiku」を利用しましたが、任意のモデルを選んでください。なお、モデルによっては申請によってアクセス権をリクエストする必要があります。
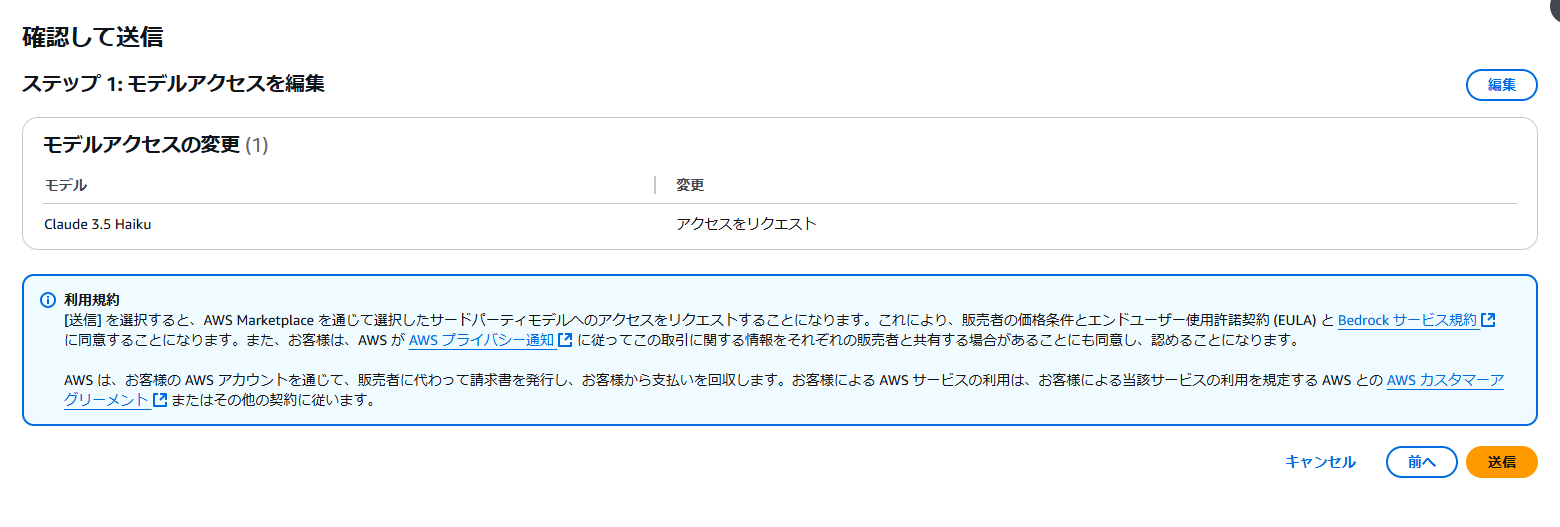
その場合は同じ画面内の「アクセスをリクエスト」からリクエスト画面に遷移いただき、利用したいモデルの「リクエスト可能」箇所をクリックし、「モデルアクセスをリクエスト」を選択すると、対象のモデルが選択された状態の画面となります。そのまま「次へ」をクリックするとリクエスト送信の確認画面となりますので、内容が問題ないことを確認し、「送信」をクリックすることでリクエストは完了します。

次にエージェント向けの指示を入力していきます。
今回はWebページから情報を収集し要約してほしいため以下のような指示としました。

次にユーザーからURLを受け取り、そのURLが指すページの本文を解析・抽出し、APIレスポンスとして返すためにアクショングループを設定していきます。
あらかじめ以下記事を参考に以下のAPIをLambdaに作成しておきました。
(なお、BeautifulSoup と chardetをカスタムレイヤーにアップロードしておきます。)
import json
import urllib.request
import chardet
from bs4 import BeautifulSoup
def get_news_url(src_url):
with urllib.request.urlopen(src_url) as res:
url = res.geturl()
return url
def get_article_body(url: str) -> str:
url = get_news_url(url)
req = urllib.request.Request(url)
with urllib.request.urlopen(req) as res:
body = res.read()
# check encoding
chardet_result = chardet.detect(body)
encoding = chardet_result['encoding']
html_doc = body.decode(encoding)
soup = BeautifulSoup(html_doc, 'html.parser')
contents = soup.find('body')
texts = [c.get_text() for c in contents.find_all('p')]
texts = "\n\n".join(texts)
return texts[:5000]
def lambda_handler(event, context):
api_path = event['apiPath']
url = ''
if api_path == '/summarize_article':
properties = event['requestBody']['content']['application/json']['properties']
for item in properties:
if item['name'] == 'url':
url = item['value']
article = {"article": get_article_body(url)}
response_body = {"application/json": {"body": json.dumps(article, ensure_ascii=False)}}
action_response = {
"actionGroup": event["actionGroup"],
"apiPath": event["apiPath"],
"httpMethod": event["httpMethod"],
"httpStatusCode": 200,
"responseBody": response_body,
}
api_response = {"messageVersion": "1.0", "response": action_response}
return api_response
Agents for Amazon BedrockでWeb上のブログやニュースを要約する
注意点として、Amazon BedrockからLambda関数を呼び出すためにリソースベースポリシー側にAmazon Bedrockからの許可ポリシーを設定する必要があります。
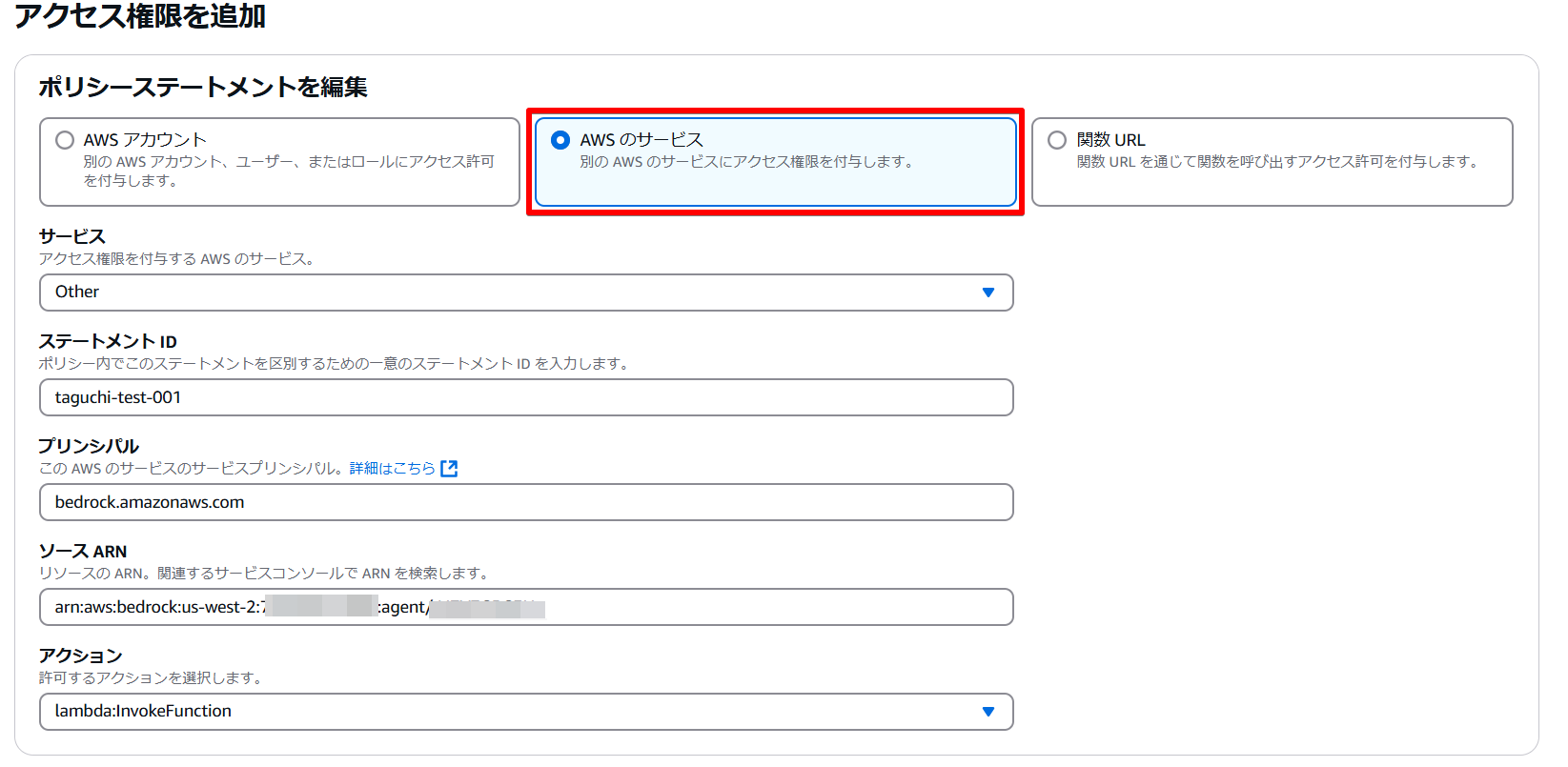
Lambda関数の設定タブから「アクセス権限」をクリックし、リソースベースのポリシーステートメントの「アクセス権限を追加」をクリックします。
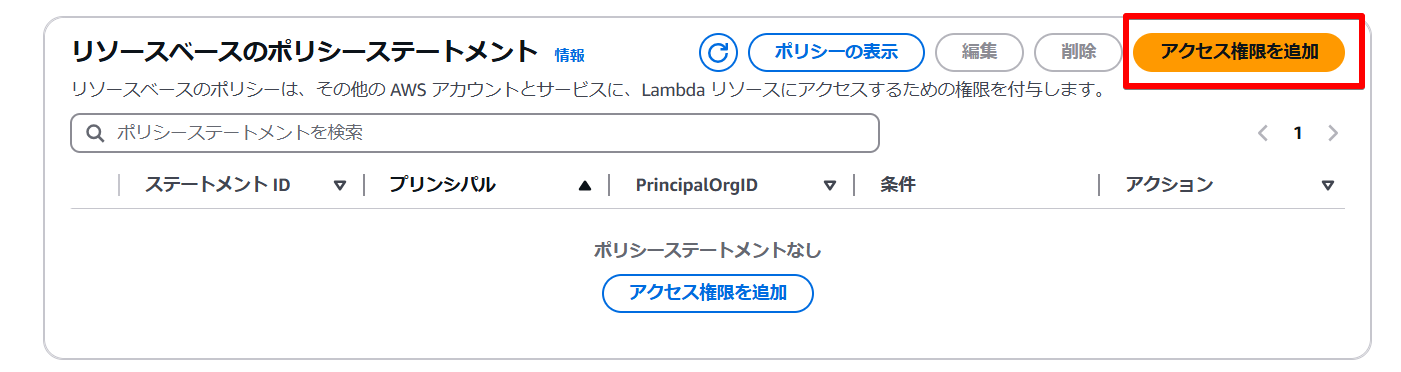
次に「AWSのサービス」を選択し、サービスは「Other」を選択します。
ステートメントIDは任意の値を入力し、プリンシパルには「bedrock.amazonaws.com」と入力します。
ソースARNにAgentのARNを入力し、アクションは「lambda:InvokeFunction」を選択し、「保存」をクリックします。
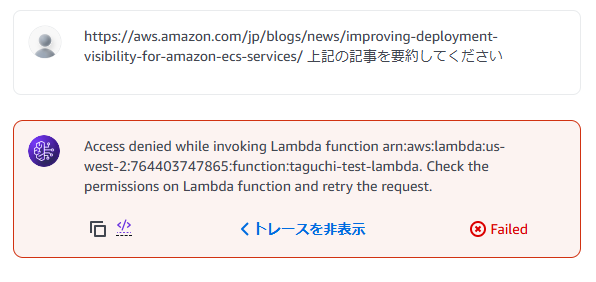
ちなみに、Lambda側にリソースベースポリシーがうまく設定されていないと、Agentを利用したときに以下のようなエラーメッセージが表示されます。画面内でエラーの内容がわかるのでとても便利に思えます。
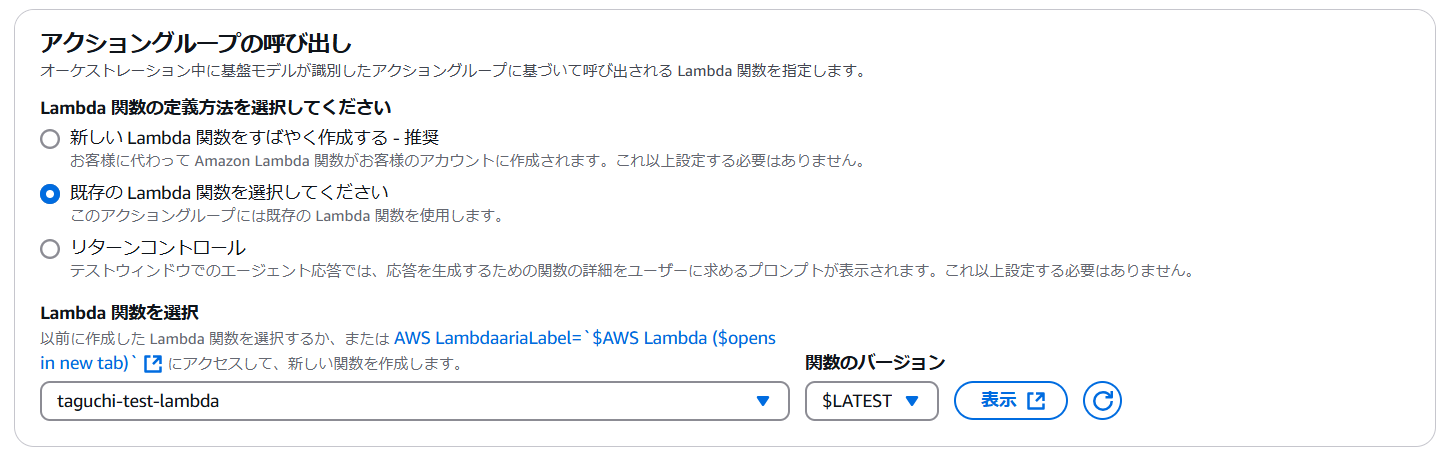
では、Agentにアクショングループを追加していきます。
アクショングループの「追加」をクリックし、任意のアクショングループ名を入力します。
アクショングループタイプには「関数の詳細で定義」と「APIスキーマで定義」の二種類あります。
「関数の詳細で定義」は比較的新しくできた方法で、アクション実行のためにエージェントにユーザーから引き出すパラメータを定義するだけで今まで必要だったOpenAIスキーマを設定せずにAgentを作成することができます。「APIスキーマで定義」は従来どおりOpenAIスキーマを用いてAgentを作成します。

今回は「APIスキーマで定義」を選択しました。
アクショングループの呼び出しで「既存のLambda関数を選択してください」を選択し、事前に作成したLambda関数を選択します。
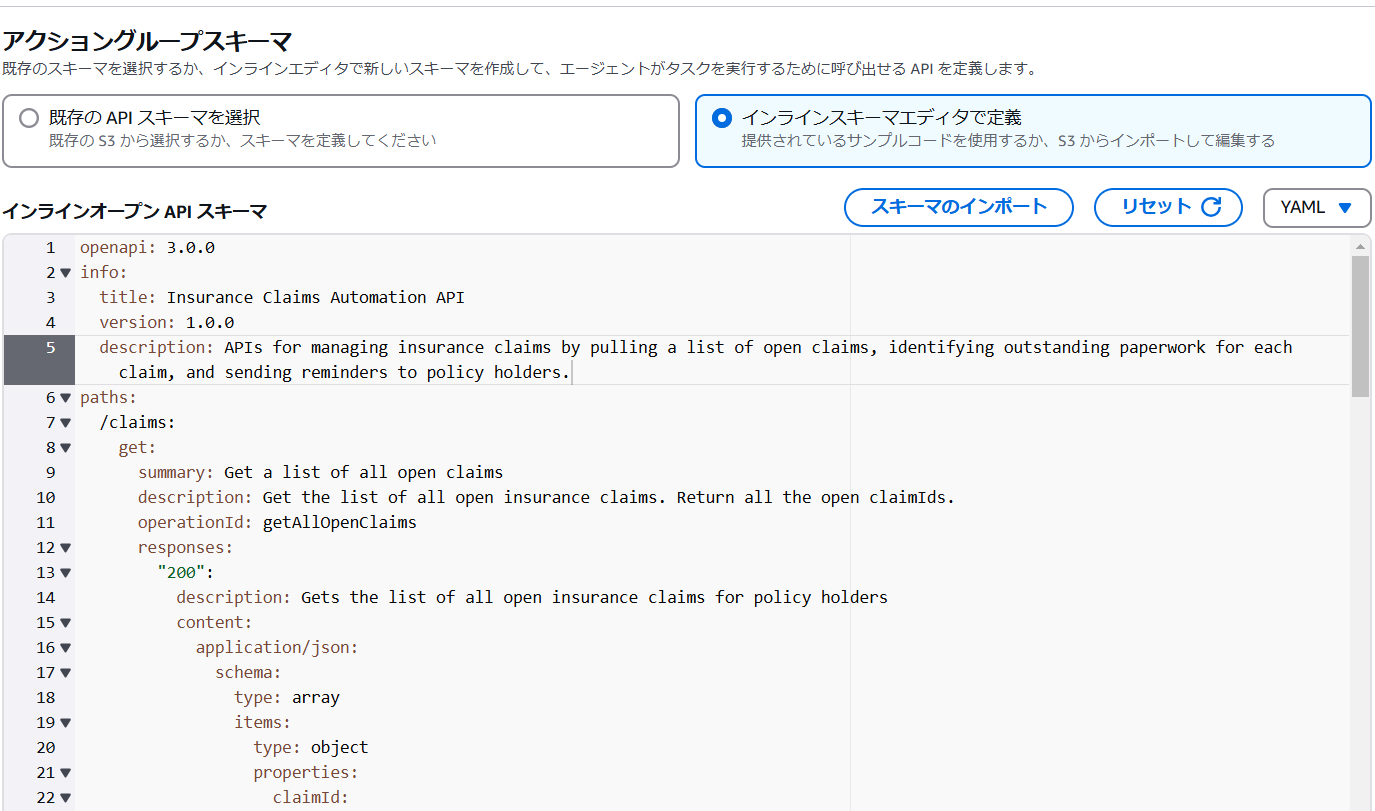
アクショングループスキーマは「インラインスキーマエディタで定義」を選択するとサンプルコードが提供されるため今回はこちらを利用します。
なお、こちらのスキーマをそのままコンソール上で編集することも可能です。
ここまで設定したら「作成」をクリックします。
アクショングループまで設定したら「保存して終了」をクリックします。
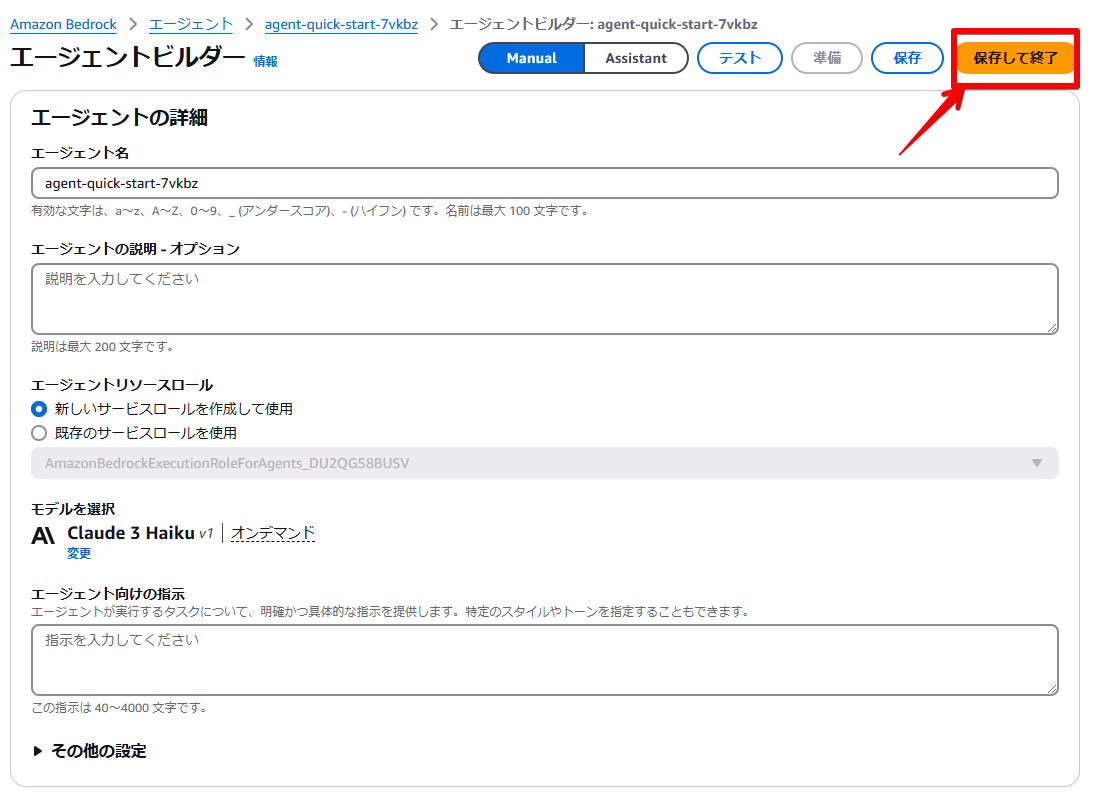
保存すると画面右側に「準備」というボタンが表示されるため、こちらをクリックします。
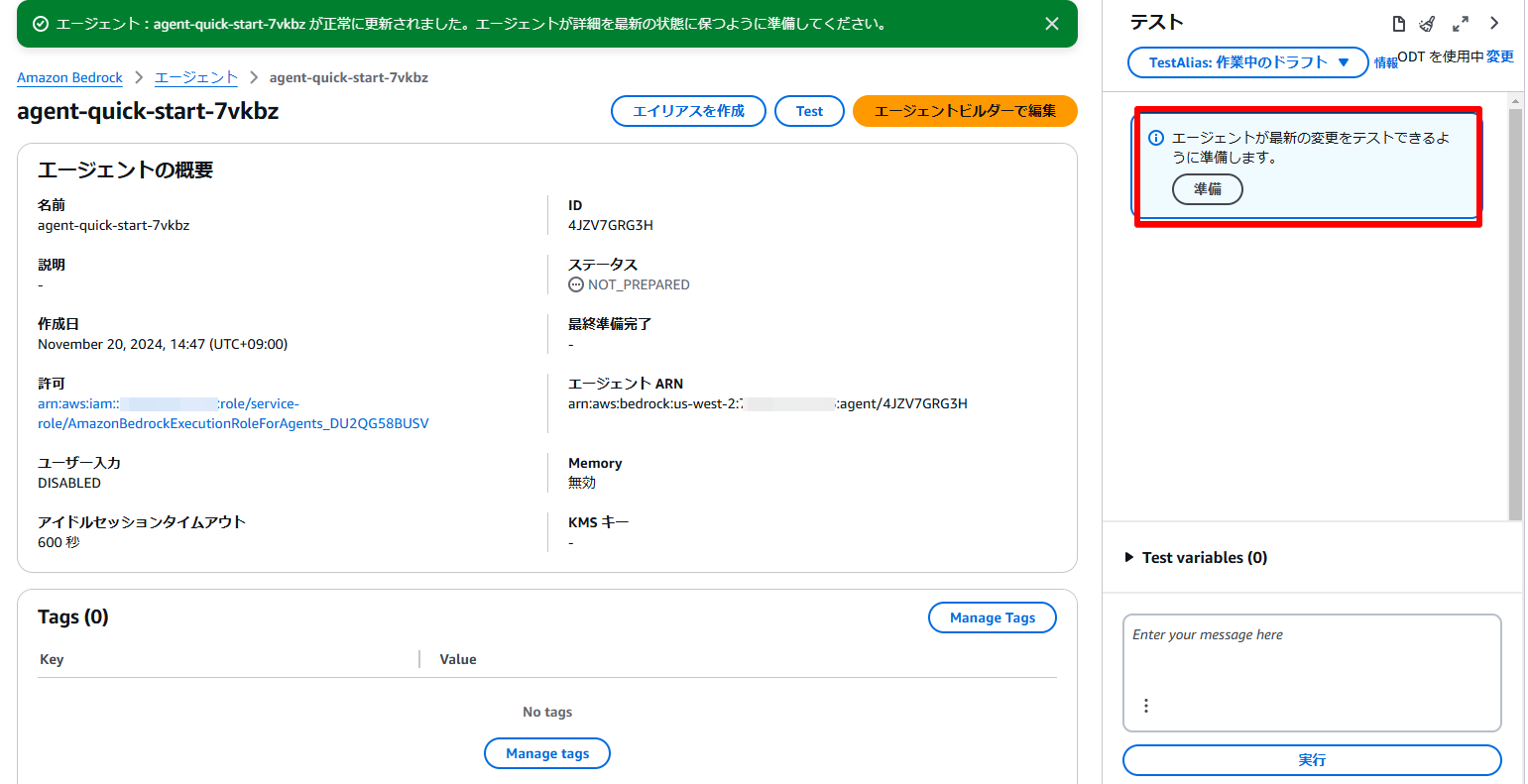
そうするとAgentが利用できる状態となるため、右側のテスト欄で動作テストを行ってみます。
試しに以下のブログを要約するよう指示してみたところ、以下のように記事の内容を要約してくれました。
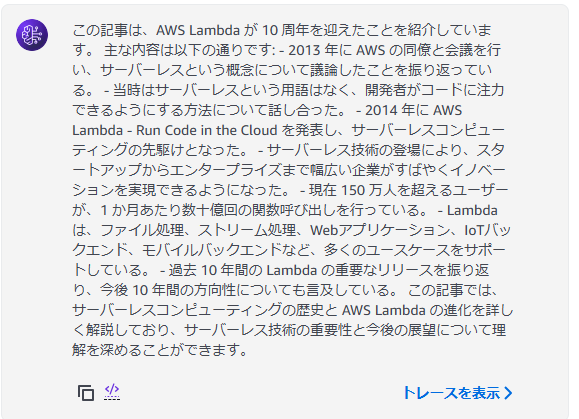
10 周年を迎えた AWS Lambda – 過去を振り返り、未来を見据えて
出来上がったAgentをSlackにつないでSlackから実行できるようにしてみます。
Slack連携の詳細は以下のコラムで紹介しています。よろしければこちらもご覧ください。
Slack×Amazon Bedrock Slack上にチャットbotを作ってみた
まずエイリアスを作成します。エイリアス名は任意のものを入力します。
まだバージョンがない場合は「新しいバージョンを作成し、このエイリアスに関連付けます。」のみ選べる状態となっています。スループットを選択では「On-demand」でエイリアスを作成します。
出来上がると以下の画像のように自動で「バージョン1」が作成されます。

AWS ChatbotとSlackを連携し、SlackとAgentを連携するため以下のコマンドを打ちます。
@aws connector add {コネクター名} {Bedrockエージェントのエージェント ARN} {BedrockエージェントのエイリアスID}
成功すると「Connector successfully added.」というメッセージが返ってきます。
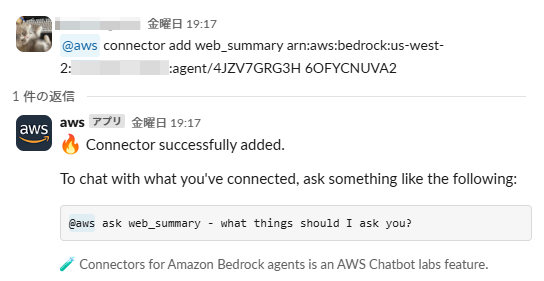
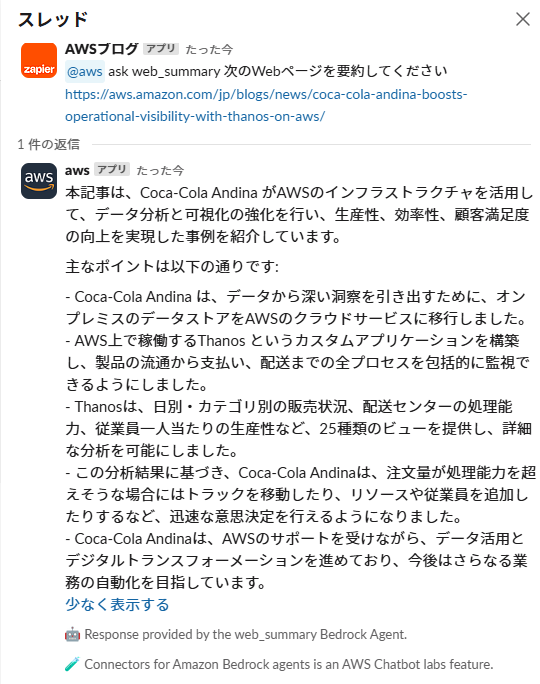
それではSlack上からWeb要約を試してみます。
以下のコマンドを実行し、AgentにWebページを要約してもらうようお願いしてみます。
@aws ask {コネクター名} 指示内容

こちらも問題なく要約された内容が返ってきました。
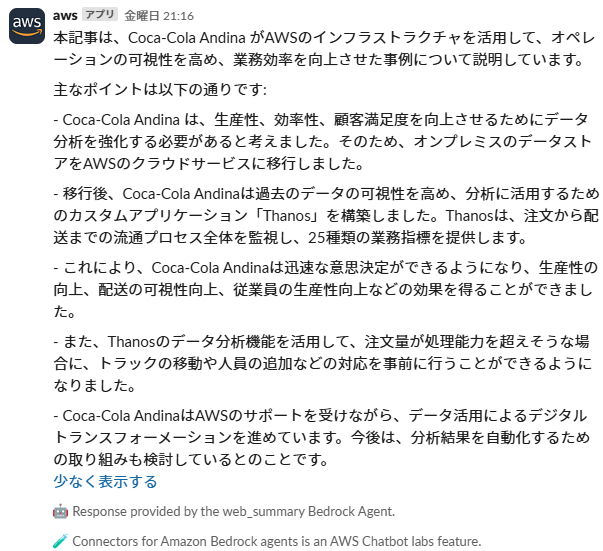
例えばiPaaSと連携することで、ほぼノーコードでWebページ要約の自動化の仕組みを作成することも可能です。
参考:会話エージェントを使用してアプリケーションのタスクを自動化する
また上記以外にもAmazon ConnectとAmazon LexとAmazon Bedrock Agentsを連携させ、Amazon Connectで受けた電話の内容をLexが文字起こしを行い、文字起こしした内容をLambda関数経由でAmazon Bedrock Agentsに連携し、アクションを実行するという活用方法もあります。
以下のコラムにて詳しく解説しておりますので、こちらもぜひご覧ください。
Amazon Bedrock Agentsを用いたアプリケーション実装例をご紹介!【Amazon Connect × 生成AI】
今回はAIエージェントについて、またAmazon Bedrockが提供する機能の一つであるAmazon Bedrock Agentsを利用し、Webページ要約の仕組みを作成してみました。
Amazon Bedrock Agentsを活用することにより、柔軟性の高いLambda関数との連携によって、効率的なタスク管理や業務効率化を図れるようになります。
またNTT東日本では、生成AIやAIエージェントを使用したCCaaSプロダクト開発に力を入れています。






自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


