
Amazon Q BusinessでPDFのインデックス化をやってみた
本コラムでは、Amazon Q Businessを活用してPDFをインデックス化する方法をご紹介します。
![]()


みなさん、こんにちは。クラウドエンジニアの鮎澤です。
業務効率化の一環として留守番電話を受け付けて、録音内容を要約してもらうと音声を聞かずとも大体の要件を把握できることもあると思います。
本コラムではAmazon Connectと生成AIサービスを組み合わせて、構築から検証までやってみましたので、ぜひ最後までご覧いただければと思います。

Amazon Connectとは、Amazon Web Services(AWS)が提供するクラウド型コンタクトセンターサービスです。柔軟なカスタマイズが可能で、自動音声応答(IVR)やコールフローを用途に応じて設定できます。
Amazon Lexなどの AI サービスとの統合により、音声認識や自然言語処理機能を活用した効率的なカスタマーサポートを実現できます。さらに、Amazon ConnectはAmazon Kinesis、Amazon QuickSightなどの他のAWSサービスとも連携し、リアルタイムの分析やレポート作成が可能です。
また、Amazon Connectでは従量課金制を採用しているため、使用した分だけ課金が発生し、初期投資なしで低コストでサービスを利用できます。また、オンプレミスのコールセンターシステムと比較して、ハードウェアの管理や保守の手間が不要なため、運用コストの削減にも貢献します。
Amazon Connectの詳しい内容については、こちらの記事をご確認ください。
Amazon Connectとは|導入時のメリット・注意点を解説
Amazon Connectに関するご相談や機能の詳しいご説明をご希望の方はお気軽にNTT東日本までお問い合わせください。
Amazon Bedrock(以下、Bedrock)は、APIを介してAnthropic、AI21 Labs、Stability AI、Amazonなどの基盤モデルを選択し利用できるAWSが提供するフルマネージド型の生成AIサービスです。Bedrockを利用することで、テキストの生成、要約、画像生成、コード生成などのAI機能を活用することができます。また、これらの機能を利用して独自の生成AIアプリケーションを構築することが可能です。
Bedrockは、企業が生成AIを迅速かつ安全に導入し、革新的なアプリケーションやサービスを開発するための強力なプラットフォームとなっています。
Bedrockの詳しい内容については、こちらの記事をご確認ください。
Amazon Connectは使用した分だけ料金が発生する従量課金制を採用しています。
最低月額料金や前払いライセンス料は不要で、無駄なコストを支払う必要がないので、企業は納得感のなる使用量を支払うことができます。
Amazon Connectの料金詳細については、Amazon Connect料金ページで構築予定のリージョンを選択していただき料金をご覧ください。
AWSでは無料利用枠の一環として、Amazon Connectを無料で利用することができます。AWS無料利用枠の詳細については、AWS無料利用枠の項目にてご確認ください。
Amazon Connectに関するご相談や機能の詳しいご説明をご希望の方はお気軽にNTT東日本までお問い合わせください。
Bedrockの料金体系は現在、以下の5つに分けられています。
| オンデマンドモード |
|
|---|---|
| バッチモード |
|
| プロビジョンドスループットモード |
|
| カスタマイズ |
|
| モデルの評価 |
|
2024年9月現在の料金体系です。
上記の料金体系は使用する基盤モデルやリージョンによって異なりますので、Bedrockの料金ページで詳細をご確認ください。
ここからはAmazon Connectで取得した留守番電話の録音データをBedrockで要約し、Amazon SNS(以下、SNS)を使ってオペレーターに通知するところまでやってみます。
本コラムではAWS Lambda(以下、Lambda)のコードを載せていますが、ご利用される場合はリージョン名やバケット名は適切な値に変更してください。
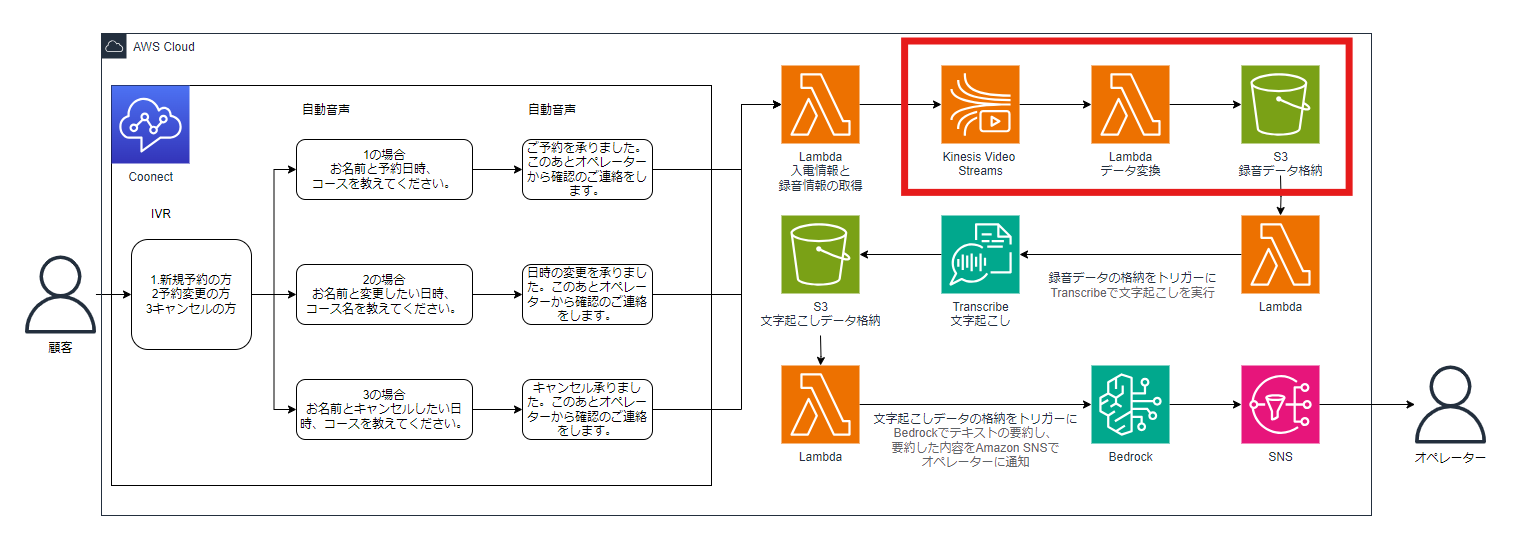
今回の構成は下図の通りです。
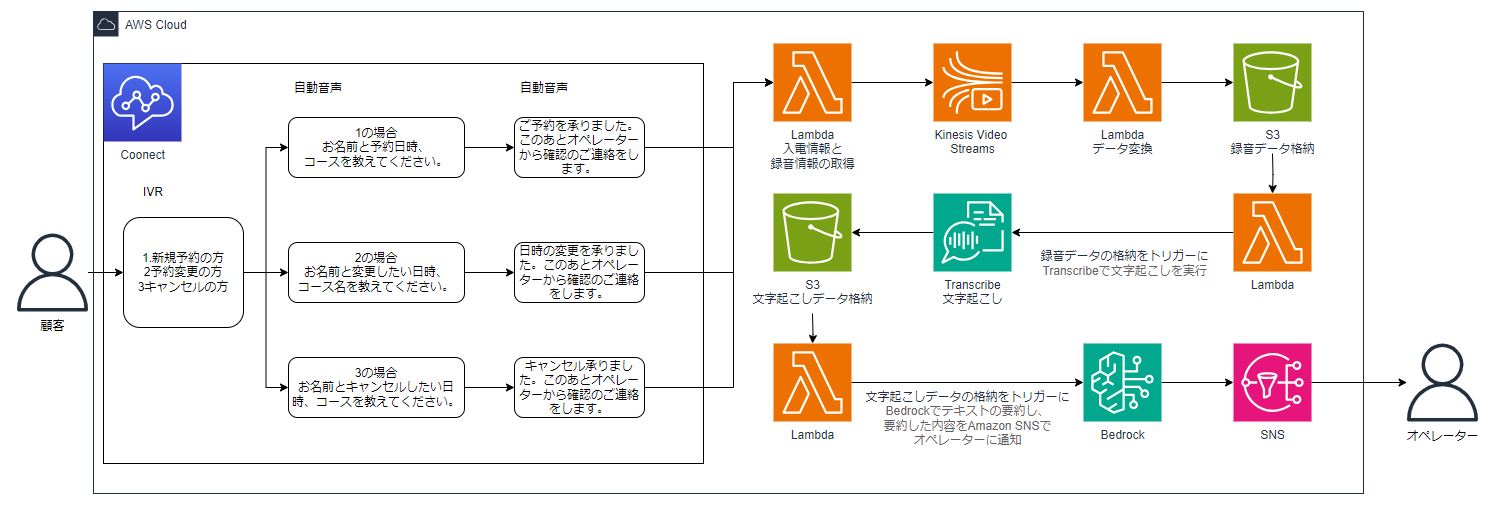
こちらの構成図について説明します。
Amazon Connectの留守番電話で予約内容を受け付けた後、LambdaでAmazon Kinesis Video Streams(以下、KVS)データ取得用情報を作成しS3バケットに格納します。録音データはKVSにMKV形式で保存されるので、後続の録音データから文字起こしをするために、LambdaでMKV形式からWAV形式に変換しS3バケットにデータを保存するようにしました。
WAV形式のデータが格納されたことをトリガーに次のLambdaが実行され、録音データの内容をAmazon Transcribe(以下、Transcribe)で文字に起こします。文字に起こしたデータは、文字起こしデータ格納用S3バケットに保存されます。
さらに文字起こしデータが格納されたことをトリガーに次のLambdaが実行され、文字起こしデータの内容をBedrockで要約しSNSでオペレーターのメールアドレス宛に通知する仕組みとなっています。
今回構築したリージョンはバージニア北部リージョンです。
バージニア北部リージョンでは同一のAmazon Connectで受発信できるため、検証がやりやすいというメリットがあります。
Bedrockの基盤モデルはAnthropic社のClaude 3 Haikuを利用しています。基盤モデルを利用するには、事前にアクセス許可のリクエストが必要です。BedrockでClaudeを使用する手順については、以下の記事をご参照ください。
【AWS】Amazon Bedrock で Claude 3 を利用したチャットを使ってみた
構築に使用しているLambdaのランタイムについて、本コラムを閲覧いただく時期によっては古くなっている可能性があります。その場合は、利用可能な最新のランタイムに合わせてコードを適宜修正してご利用ください。
また、本コラムにおいてLambdaの実行ロールには、アクセスが必要なサービスに対してフルアクセス権限を付与していますが、セキュリティ上のベストプラクティスとして、必要最小限のアクセス権限に絞ることをお勧めいたします。
ここから構築した内容について触れていきますが、構成図の流れと前後する部分がございますのでご了承ください。
はじめにKVSデータ取得用情報をS3バケットに格納するための手順をご紹介します。
構成図だと下図の赤枠の部分です。
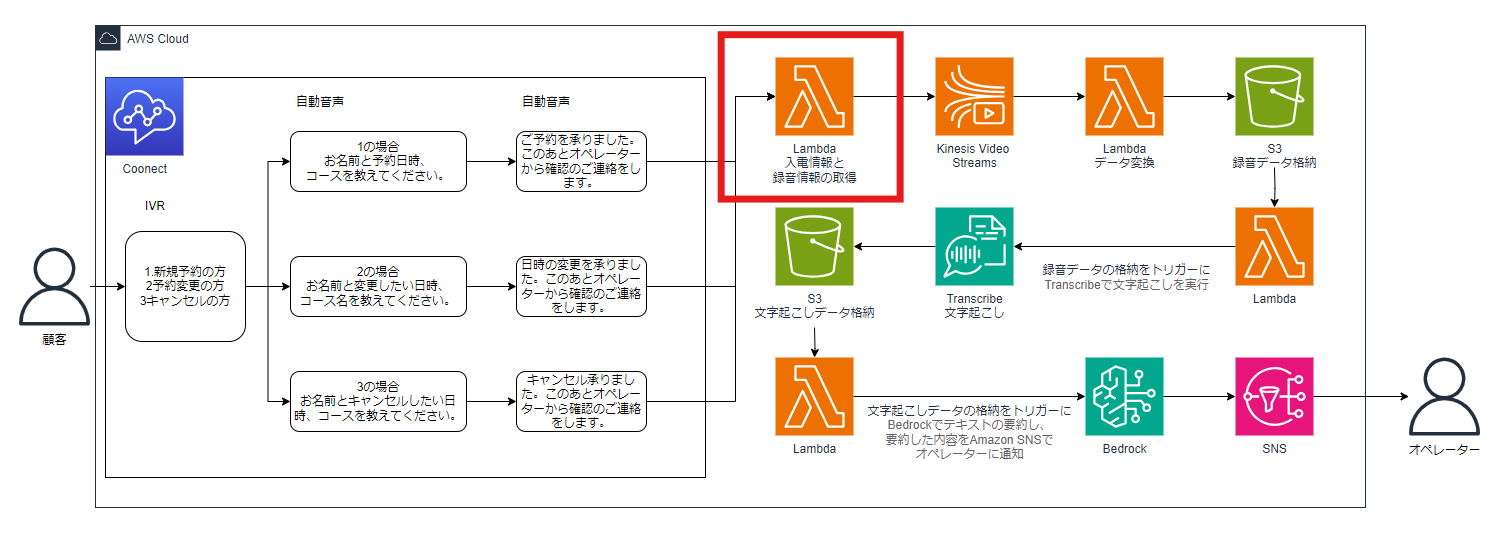
構成図にアイコンがありませんがKVSデータ取得用情報を格納するためのS3バケットが必要なので、先に構築するリージョンでS3バケットを作成します。S3バケットは以下のように構築しました。
S3バケットを作成したらバージニア北部リージョンでLambdaを作成します。
作成するLambdaのパラメーターは以下の通りです。
Lambdaを作成するとIAMロールが自動で作成されます。今回は下記のポリシーを追加しました。
コードは下記のとおりです。リージョン名やバケット名は適切な値に変更してください。
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
const region = 'リージョン名';
const bucketName = 'バケット名';
export const handler = async (event) => {
console.log(JSON.stringify(event));
// リクエストから必要データを取得する
let streamInformation = {};
const contactData = event.Details.ContactData;
streamInformation.contactId = contactData.ContactId; // コンタクトID
streamInformation.customerEndpoint = contactData.CustomerEndpoint.Address;
streamInformation.systemEndpoint = contactData.SystemEndpoint.Address;
const audio = contactData.MediaStreams.Customer.Audio;
streamInformation.startFragmentNumber = audio.StartFragmentNumber;
streamInformation.startTimestamp = audio.StartTimestamp;
streamInformation.stopFragmentNumber = audio.StopFragmentNumber;
streamInformation.stopTimestamp = audio.StopTimestamp;
streamInformation.streamARN = audio.StreamARN;
// S3に日付文字列をキーといして保存する
const s3Client = new S3Client({ region: region });
const Id = event.Details.ContactData.ContactId;
console.log(Id);
const key = createKeyName() + Id;
const body = JSON.stringify(streamInformation);
const params = {
Bucket: bucketName,
Key: key,
Body: body
};
await s3Client.send(new PutObjectCommand(params));
return {};
};
function createKeyName() {
const dt = new Date();
// 日本の時間に修正
dt.setTime(dt.getTime() + 32400000); // 1000 * 60 * 60 * 9(hour)
// 日付を数字として取り出す
const year = dt.getFullYear();
const month = String(dt.getMonth() + 1).padStart(2, '0');
const day = String(dt.getDate()).padStart(2, '0');
const hour = String(dt.getHours()).padStart(2, '0');
const min = String(dt.getMinutes()).padStart(2, '0');
const sec = String(dt.getSeconds()).padStart(2, '0');
return `${year}${month}${day}${hour}${min}${sec}`;
}
コードを入力したら「Deploy」をクリックしてLambdaの作成は完了です。
続いてAmazon Connectを作成します。構成図だと下図の赤枠の部分です。
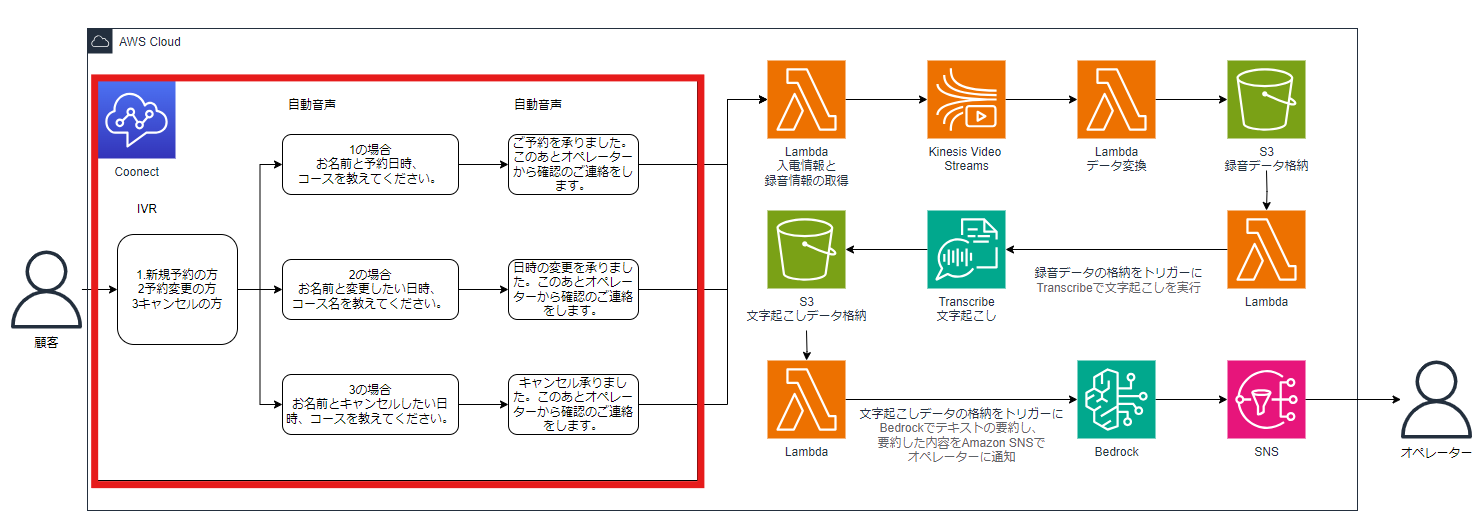
Amazon Connectを新規で作成する場合、「インスタンスを追加する」をクリックして必要なパラメーターを入力していきます。下図を参考にパラメーターを入力してみてください。
ステップ1
アクセスURLは、任意の値を入力してください。
ステップ2
姓名、ユーザー名も任意の値を入力してください。
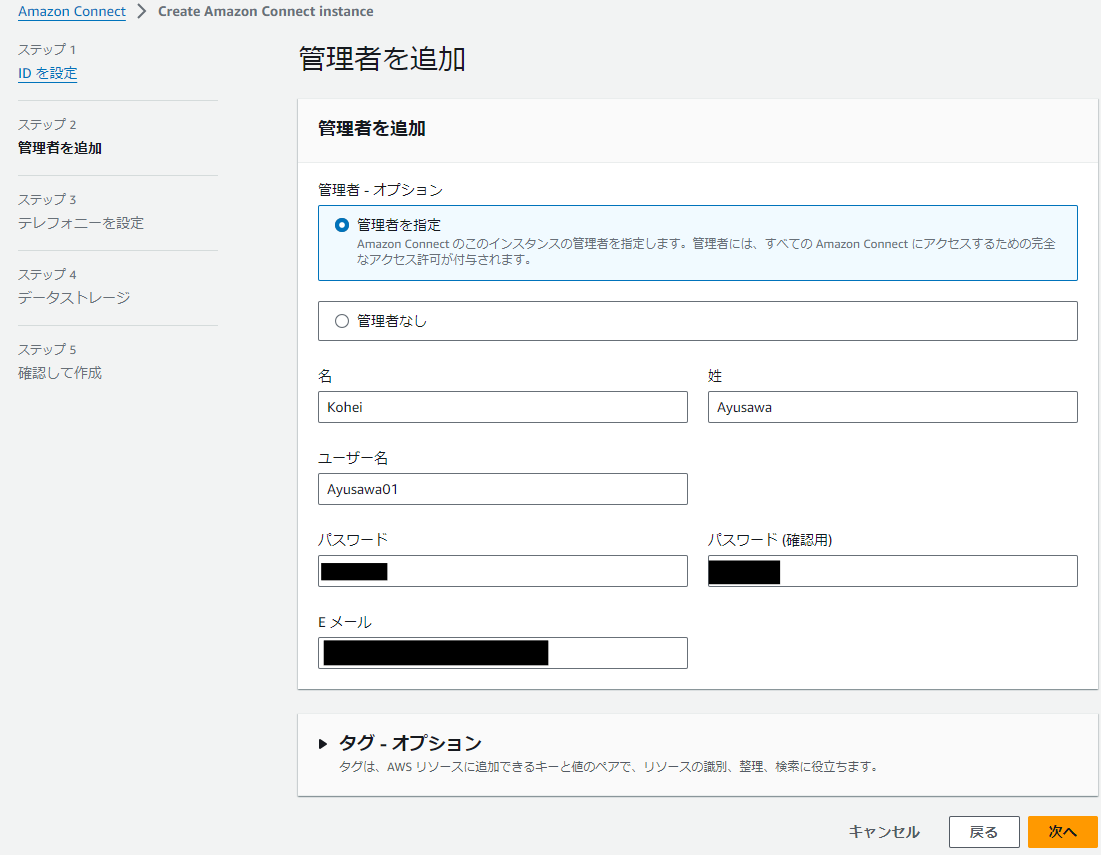
ステップ3
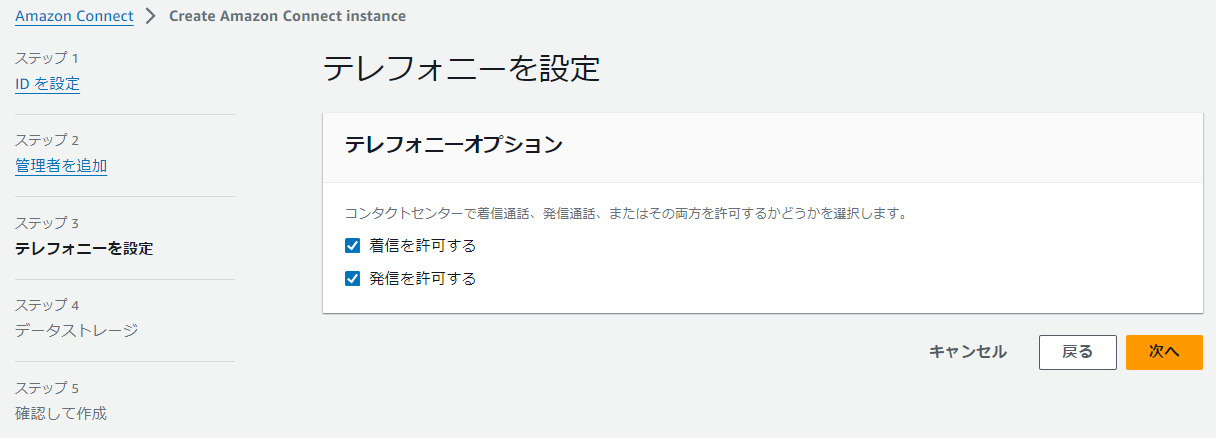
ステップ4
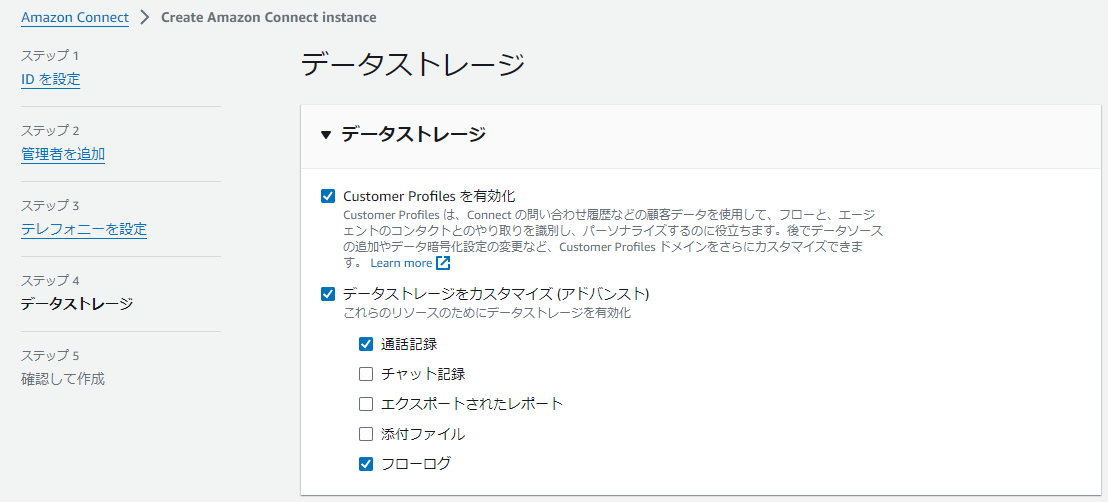
ステップ5は確認画面なので省略しますが、必要なパラメーターが入力されていれば「インスタンスの作成」をクリックしてください。
Amazon Connectインスタンスを作成したら、先ほど作成したLambdaを紐づけます。
Amazon Connectのインスタンスエイリアス名をクリックし、サイドバーから問い合わせメニューをクリックします。AWS Lambdaという項目があるので、作成したLambdaを選択し、「Add Lambda Function」をクリックして追加します。
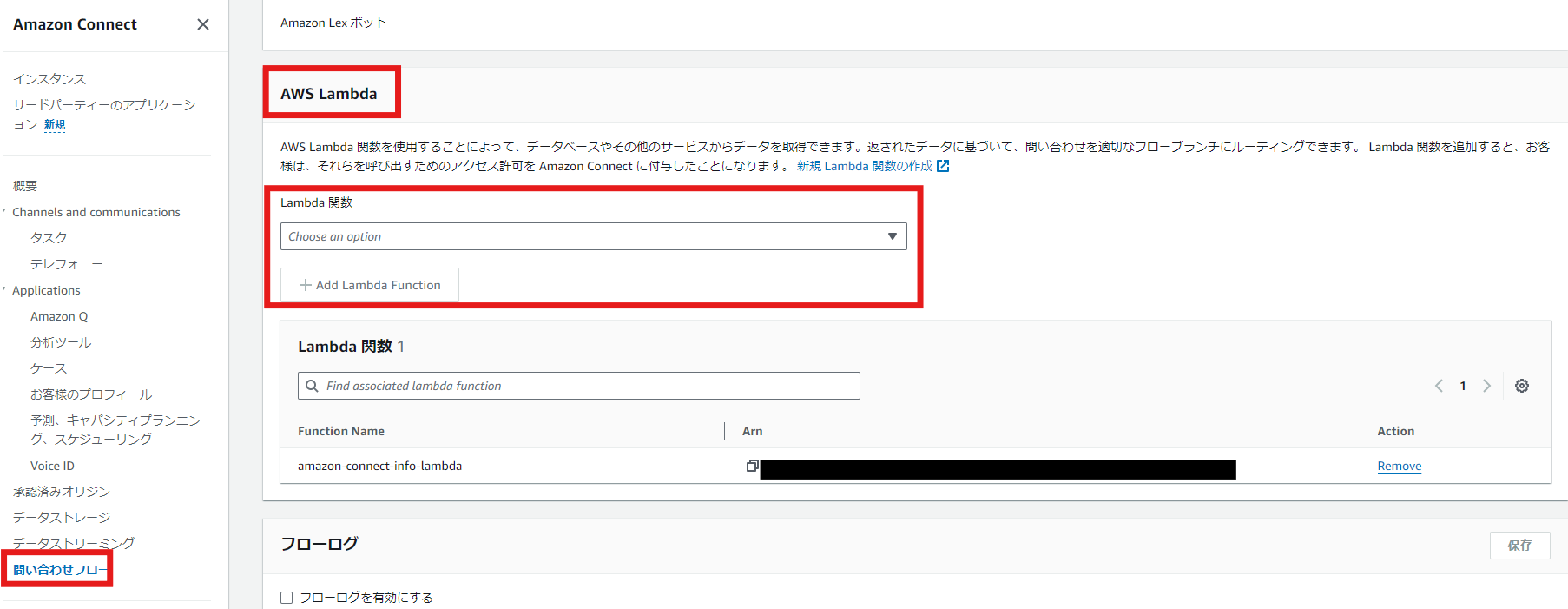
それではAmazon Connectの設定をやっていきましょう。
設定する内容は以下の通りです。
電話番号の取得、発信用の設定については省略させていただき、受信用のフローをご紹介します。
構築したフローは下図の通りです。
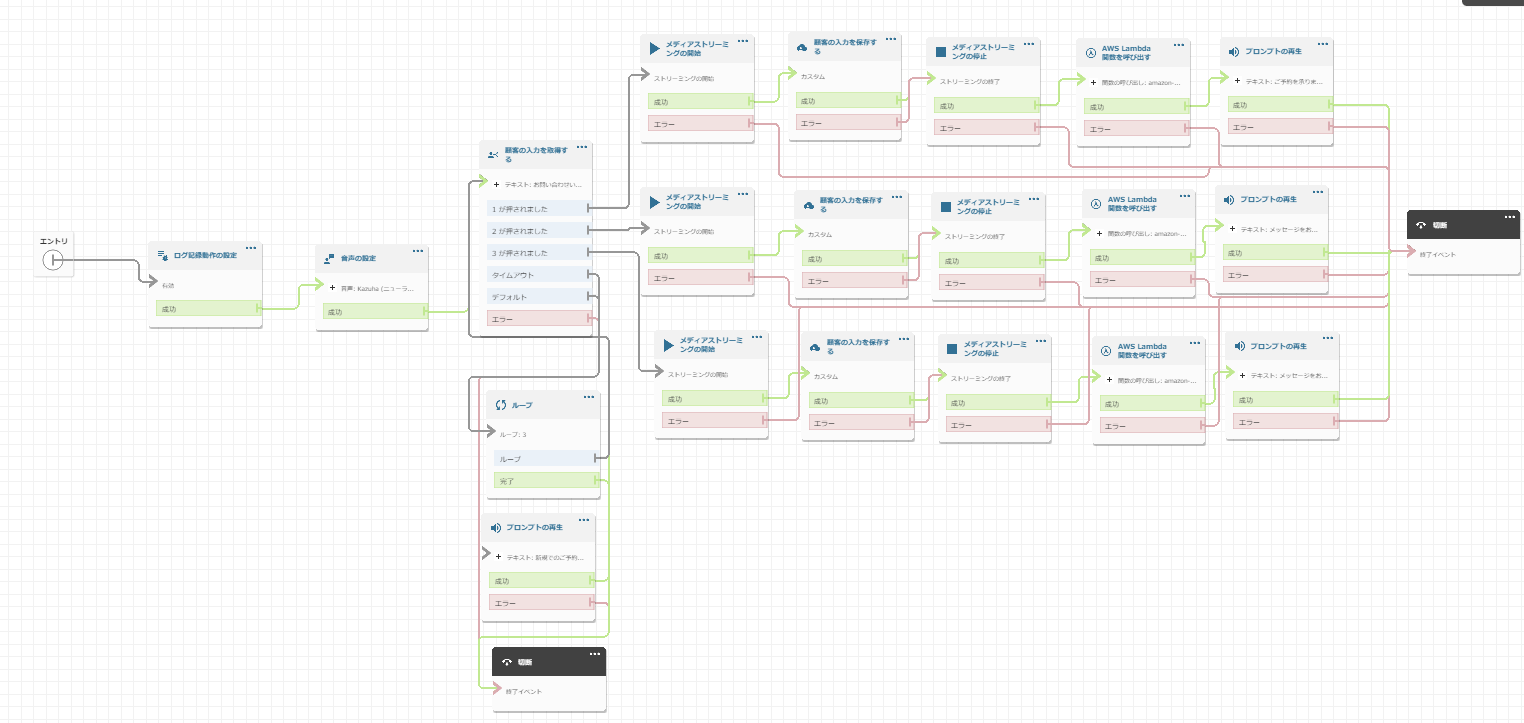
「AWS Lambda 関数を呼び出す」のブロックで、Amazon Connectに追加したLambdaを選びます。
KVSに録音データが送信されるように「メディアストリーミングの開始」ブロックと「メディアストリーミングの終了」ブロックを配置しました。
フローを設定したら忘れずに「公開」をクリックしましょう。
下図の赤枠で囲ったサービスを構築して、録音データを格納するところまでご紹介します。
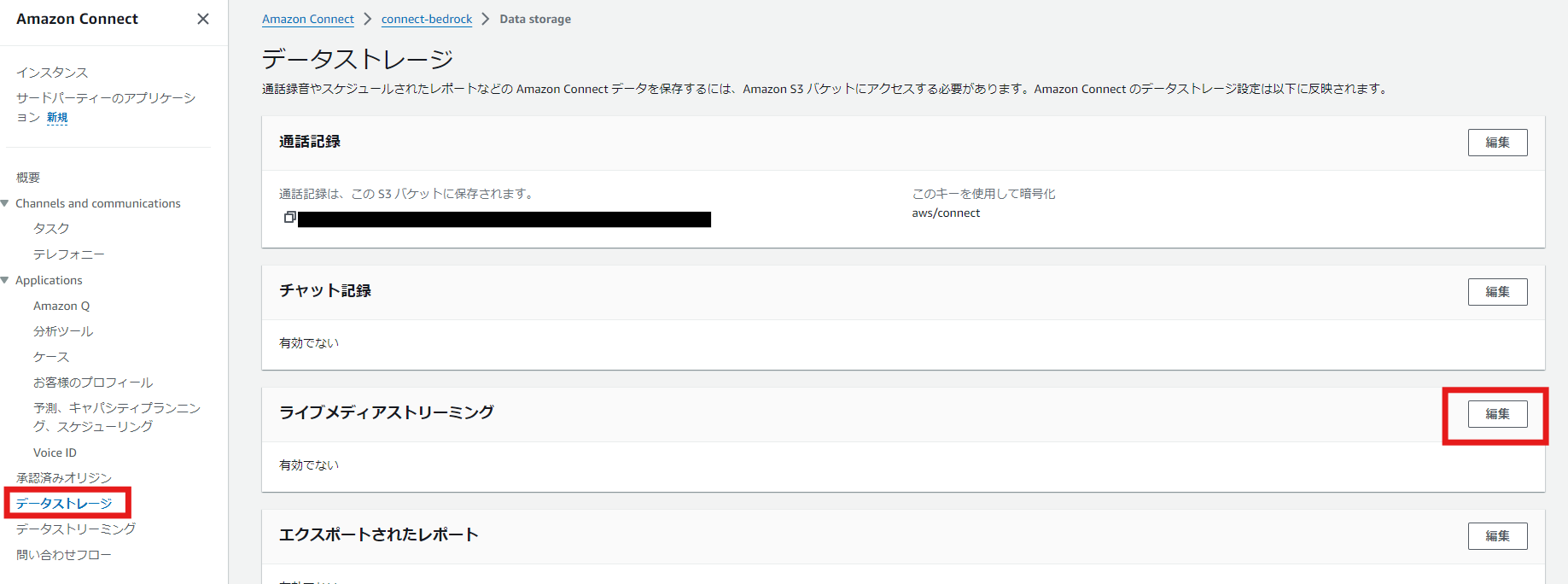
まずはAmazon Connect側の設定でKVSと連携します。
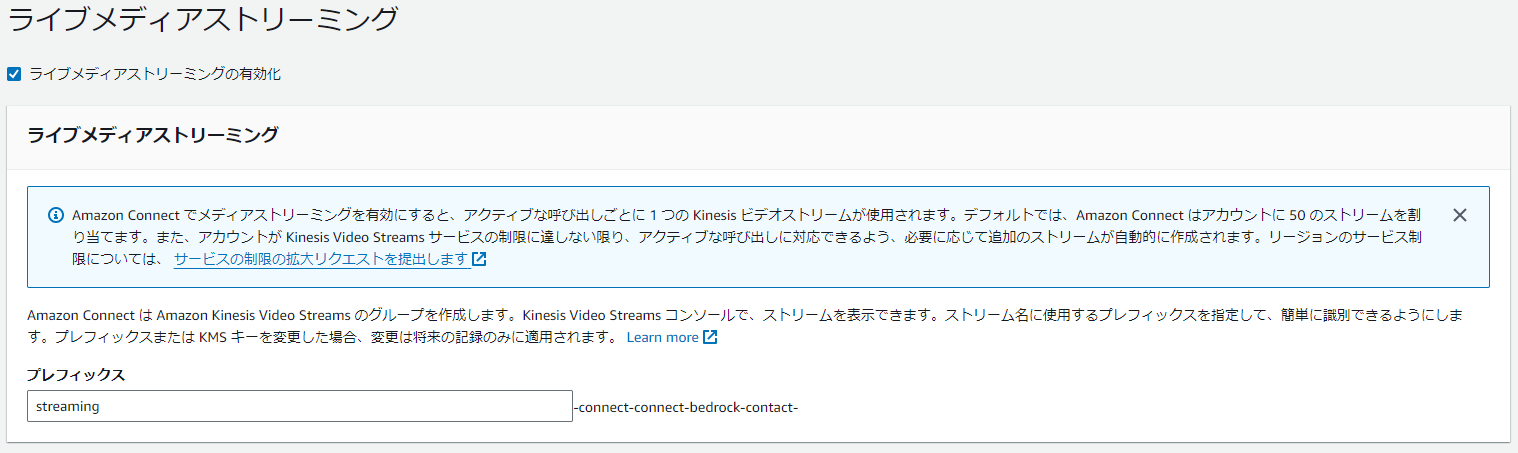
Amazon Connectのインスタンスエイリアス名をクリックし、「データストレージ」を選択します。「ライブメディアストリーミング」の項目で、「編集」ボタンをクリックします。次に、「ライブメディアストリーミングの有効化」にチェックを入れます。プレフィックスには任意の文字列を入力し、「保存」をクリックします。これでKVSとの連携が完了します。
次に録音データを格納するためのS3バケットを作成します。S3バケットは以下のように構築しました。
S3バケットを作成したら、KVSの録音データをWAV形式に変換しS3バケットに格納するためのLambdaをバージニア北部リージョンで作成します。
作成するLambdaのパラメーターは以下の通りです。
自動で作成されたIAMロールには下記のポリシーを追加しました。
Lambdaの実行時間がタイムアウトにならないように、タイムアウトは10分しています。また、KVSデータ取得用情報がS3バケットに格納されたことをトリガーにLambdaを実行したいので、「トリガーを追加」で5-3-1.で作成したS3バケットを追加します。
今回使用するコードには、パッケージ(@aws-sdk/client-s3, @aws-sdk/client-kinesis-video, @aws-sdk/client-kinesis-video-media, ebml)をインストールする必要があります。特にebmlはこのLambdaでKVSからのデータを処理するために必須なので、必ずインストールしてください。下記のコマンドでインストールできます。
インストールにはAWS CloudShellが便利です。
npm install @aws-sdk/client-s3 @aws-sdk/client-kinesis-video @aws-sdk/client-kinesis-video-media ebml
インストールが完了したら下記コードを作成します。
拡張子はmjsとし、リージョン名やバケット名は適切な値に変更してください。
import { S3Client, GetObjectCommand, PutObjectCommand } from "@aws-sdk/client-s3";
import { KinesisVideoClient, GetDataEndpointCommand } from "@aws-sdk/client-kinesis-video";
import { KinesisVideoMediaClient, GetMediaCommand } from "@aws-sdk/client-kinesis-video-media";
import { Decoder } from 'ebml';
import { Readable } from 'stream';
const region = 'リージョン名';
const bucketName = 'バケット名';
export const handler = async (event) => {
console.log(JSON.stringify(event));
const s3 = new S3Client({ region });
for (let record of event.Records) {
const getKey = record.s3.object.key;
const fileName = getKey;
// S3から録音データに関する情報を取得
const data = await getS3Object(s3, record.s3.bucket.name, getKey);
const info = JSON.parse(data);
const streamName = info.streamARN.split('stream/')[1].split('/')[0];
const fragmentNumber = info.startFragmentNumber;
// Kinesis Video Streamsから当該RAWデータの取得
const raw = await getMedia(streamName, fragmentNumber);
// RAWデータからWAVファイルを作成
const wav = Converter.createWav(raw, 8000);
// WAVファイルをS3に保存する
// WAVファイルをS3に保存する
let tagging = `customerEndpoint=${encodeURIComponent(info.customerEndpoint)}&systemEndpoint=${encodeURIComponent(info.systemEndpoint)}&startTimestamp=${encodeURIComponent(info.startTimestamp)}`;
await putS3Object(s3, bucketName, `${fileName}.wav`, Buffer.from(wav.buffer), tagging);
}
return {};
};
async function getS3Object(s3Client, bucketName, key) {
const command = new GetObjectCommand({ Bucket: bucketName, Key: key });
const response = await s3Client.send(command);
return streamToString(response.Body);
}
async function putS3Object(s3Client, bucketName, key, body, tagging) {
const command = new PutObjectCommand({
Bucket: bucketName,
Key: key,
Body: body,
Tagging: tagging
});
return s3Client.send(command);
}
async function streamToString(stream) {
const chunks = [];
for await (const chunk of stream) {
chunks.push(Buffer.from(chunk));
}
return Buffer.concat(chunks).toString('utf8');
}
async function getMedia(streamName, fragmentNumber) {
// Endpointの取得
const kinesisvideo = new KinesisVideoClient({ region });
const params = {
APIName: "GET_MEDIA",
StreamName: streamName
};
const command = new GetDataEndpointCommand(params);
const { DataEndpoint } = await kinesisvideo.send(command);
// RAWデータの取得
const kinesisvideomedia = new KinesisVideoMediaClient({ endpoint: DataEndpoint, region });
const mediaParams = {
StartSelector: {
StartSelectorType: "FRAGMENT_NUMBER",
AfterFragmentNumber: fragmentNumber,
},
StreamName: streamName
};
const mediaCommand = new GetMediaCommand(mediaParams);
const { Payload } = await kinesisvideomedia.send(mediaCommand);
// Payloadがストリームでない場合、ストリームに変換
const stream = Payload instanceof Readable ? Payload : Readable.from(Payload);
const decoder = new Decoder();
let chunks = [];
decoder.on('data', chunk => {
if (chunk[1].name === 'SimpleBlock') {
chunks.push(chunk[1].data);
}
});
// ストリームをデコーダーにパイプ
stream.pipe(decoder);
// ストリームの終了を待つ
await new Promise((resolve, reject) => {
stream.on('end', resolve);
stream.on('error', reject);
});
// chunksの結合
const margin = 4; // 各chunkの先頭4バイトを破棄する
const sumLength = chunks.reduce((sum, chunk) => sum + chunk.byteLength - margin, 0);
const sample = new Uint8Array(sumLength);
let pos = 0;
for (const chunk of chunks) {
const tmp = new Uint8Array(chunk.buffer, margin);
sample.set(tmp, pos);
pos += chunk.byteLength - margin;
}
return sample.buffer;
}
class Converter {
// WAVファイルの生成
static createWav(samples, sampleRate) {
const len = samples.byteLength;
const view = new DataView(new ArrayBuffer(44 + len));
this._writeString(view, 0, 'RIFF');
view.setUint32(4, 32 + len, true);
this._writeString(view, 8, 'WAVE');
this._writeString(view, 12, 'fmt ');
view.setUint32(16, 16, true);
view.setUint16(20, 1, true); // リニアPCM
view.setUint16(22, 1, true); // モノラル
view.setUint32(24, sampleRate, true);
view.setUint32(28, sampleRate * 2, true);
view.setUint16(32, 2, true);
view.setUint16(34, 16, true);
this._writeString(view, 36, 'data');
view.setUint32(40, len, true);
const srcView = new DataView(samples);
for (let i = 0; i < len; i += 2) {
view.setInt16(44 + i, srcView.getInt16(i, true), true);
}
return view;
}
static _writeString(view, offset, string) {
for (let i = 0; i < string.length; i++) {
view.setUint8(offset + i, string.charCodeAt(i));
}
}
}
最後にpackage.jsonとnode_modulesディレクトリを含むプロジェクト全体をZIPファイルにして、Lambdaにアップロードしてください。サイズが10 MB より大きい場合は、S3バケットにアップロードして、LambdaでアップロードしたZIPファイルを指定しましょう。
下図の赤枠で囲ったサービスを構築して、WAV形式で格納されたデータから文字起こしするところまで紹介していきます。
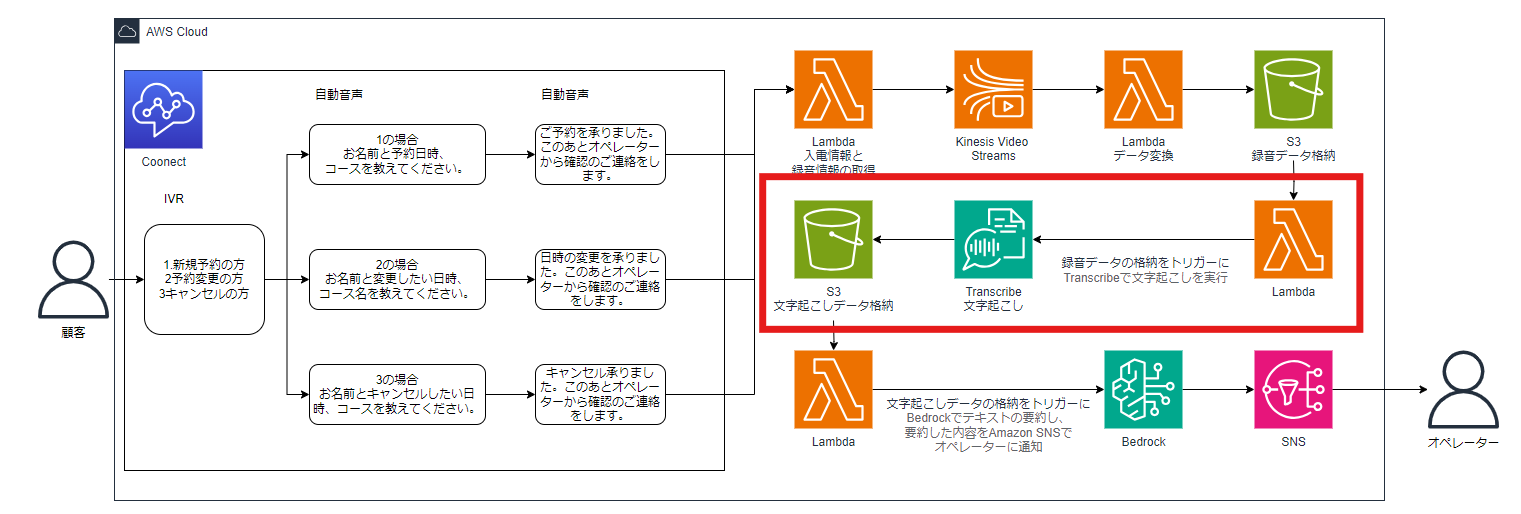
文字起こしデータを格納するS3バケットを作成します。S3バケットは以下のように構築しました。
次に録音データから文字を起こし、テキストデータとしてS3バケットに格納するためのLambdaをバージニア北部リージョンで作成します。
作成するLambdaのパラメーターは以下の通りです。
自動で作成されたIAMロールには下記のポリシーを追加しました。
録音データが格納されたことをトリガーにLambdaを実行したいので、「トリガーを追加」で5-3-2で作成したS3バケットを追加します。
コードは下記のとおりです。リージョン名やバケット名は適切な値に変更してください。
import { S3Client, GetObjectCommand, PutObjectCommand } from "@aws-sdk/client-s3";
import { TranscribeClient, StartTranscriptionJobCommand, GetTranscriptionJobCommand } from "@aws-sdk/client-transcribe";
const s3Client = new S3Client({ region: "リージョン名" });
const transcribeClient = new TranscribeClient({ region: "リージョン名" });
export const handler = async (event) => {
const srcBucket = event.Records[0].s3.bucket.name;
const srcKey = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " "));
const dstBucket = "バケット名";
try {
// トランスクリプションジョブの開始
const jobName = `transcribe-job-${Date.now()}`;
const startJobCommand = new StartTranscriptionJobCommand({
TranscriptionJobName: jobName,
LanguageCode: "ja-JP", // 日本語の場合
Media: { MediaFileUri: `s3://${srcBucket}/${srcKey}` },
OutputBucketName: dstBucket,
OutputKey: `${srcKey.split('.')[0]}.json`
});
await transcribeClient.send(startJobCommand);
// ジョブの完了を待つ
let jobStatus;
do {
const getJobCommand = new GetTranscriptionJobCommand({ TranscriptionJobName: jobName });
const { TranscriptionJob } = await transcribeClient.send(getJobCommand);
jobStatus = TranscriptionJob.TranscriptionJobStatus;
if (jobStatus === "COMPLETED") break;
await new Promise(resolve => setTimeout(resolve, 5000)); // 5秒待機
} while (jobStatus !== "FAILED");
if (jobStatus === "FAILED") {
throw new Error("Transcription job failed");
}
// 文字起こし結果を取得
const getObjectCommand = new GetObjectCommand({
Bucket: dstBucket,
Key: `${srcKey.split('.')[0]}.json`
});
const { Body } = await s3Client.send(getObjectCommand);
const jsonContent = await Body.transformToString();
const transcription = JSON.parse(jsonContent);
// テキストデータを抽出
const textContent = transcription.results.transcripts[0].transcript;
// テキストデータをS3に保存
const textKey = `${srcKey.split('.')[0]}.txt`;
const putObjectCommand = new PutObjectCommand({
Bucket: dstBucket,
Key: textKey,
Body: textContent,
ContentType: "text/plain"
});
await s3Client.send(putObjectCommand);
console.log("Transcription completed and text file saved successfully");
return { statusCode: 200, body: "Transcription completed and text file saved" };
} catch (error) {
console.error("Error:", error);
return { statusCode: 500, body: "Error processing the file" };
}
};
下図の赤枠で囲ったサービスを構築して、テキストデータの内容をBedrockで要約しオペレーターに通知するところまで紹介していきます。
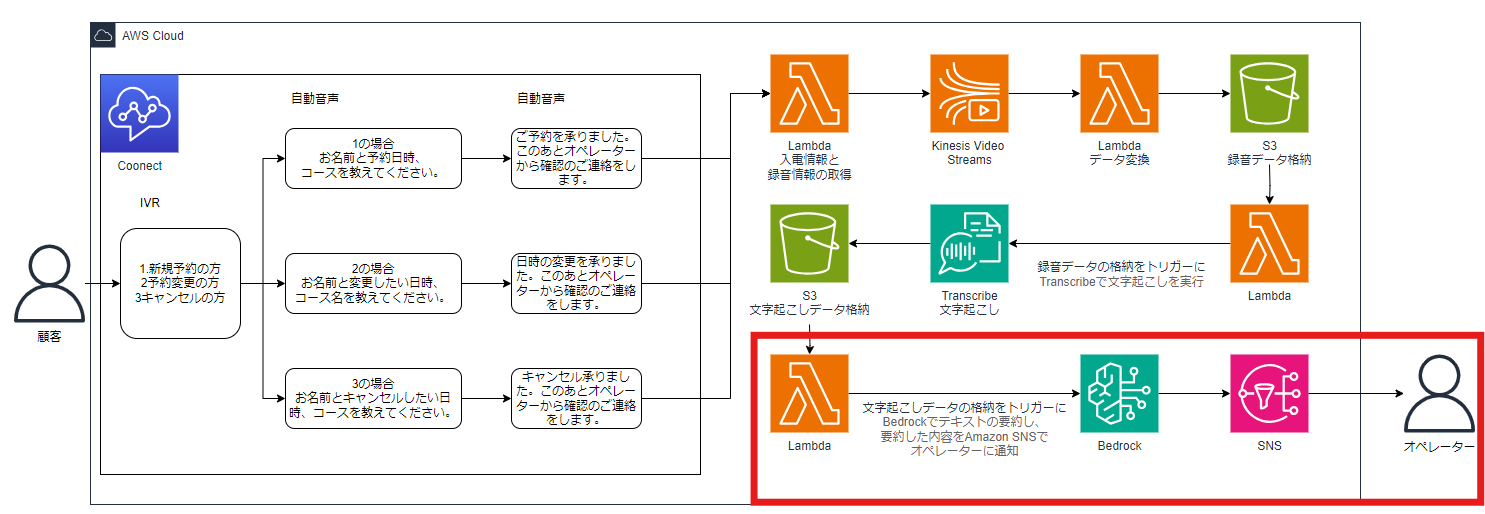
後述するLambdaのコードでSNSトピックのARNが必要になるので、先にSNSを設定していきます。
SNSトピックでは以下のように構築しました。
続いてオペレーターのメールアドレス宛に通知するために、SNSでサブスクリプションを作成します。パラメーターは下記のとおりです。
これでSNSの設定は完了です。
Bedrockの開始方法については、5-2前提のところで触れていますのでここでは省かせていただき、Lambdaについて紹介していきます。
作成するLambdaのパラメーターは以下の通りです。
自動で作成されたIAMロールには下記のポリシーを追加しました。
Lambdaの実行時間がタイムアウトにならないように、タイムアウトは1分としています。また、テキストデータがS3バケットに格納されたことをトリガーにLambdaを実行したいので、「トリガーを追加」で5-3-3で作成したS3バケットを追加します。
今回使用するLambdaのコードには、最新のboto3ライブラリをインストールする必要があります。理由は最新のAWS SDKを使用できるようにし、Bedrockなどの新しいサービスを利用できるようにするためです。5-3-2と同様にAWS CloudShellで、下記コマンドを実行しインストールします。
pip install boto3 -t . --upgrade
インストールが完了したら下記コードを作成します。
拡張子はpyとし、リージョン名やSNSトピックARNは適切な値に変更してください。
また下記のコードでは検証のため、アップロードされたすべてのデータを要約する記述となっています。テキストデータのみ要約したい場合は、適宜コードを修正してください。
import boto3
import json
def lambda_handler(event, context):
# S3クライアントの初期化
s3 = boto3.client('s3')
# Bedrockクライアントの初期化
bedrock = boto3.client('bedrock-runtime', region_name='リージョン名')
# SNSクライアントの初期化
sns = boto3.client('sns')
# S3バケットからデータを読み取る
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
print(f"Bucket: {bucket}, Key: {key}") # デバッグ用
try:
response = s3.get_object(Bucket=bucket, Key=key)
text = response['Body'].read().decode('utf-8')
except Exception as e:
print(f"Error reading S3 object: {str(e)}")
raise
# Bedrock Claude 3 Haikuモデルを使用して要約(Messages API使用)
messages = [
{"role": "user", "content": f"以下のテキストを要約してください:\n\n{text}"}
]
response = bedrock.invoke_model(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 300,
"messages": messages
}),
contentType='application/json'
)
summary = json.loads(response['body'].read())['content'][0]['text']
# SNSトピックにメッセージを発行
sns.publish(
TopicArn='SNSトピックARN',
Subject='文字起こしデータの要約',
Message=f'ファイル名: {key}\n\n要約:\n{summary}'
)
return {
'statusCode': 200,
'body': json.dumps('要約と通知が完了しました')
}
最後にコードと一緒に、インストールされたライブラリをZIPファイルに圧縮し、Lambdaにアップロードしてください。サイズが10 MB より大きい場合は、S3バケットにアップロードして、LambdaでアップロードしたZIPファイルを指定しましょう。
これで構築は完了です。
それでは検証していきます。
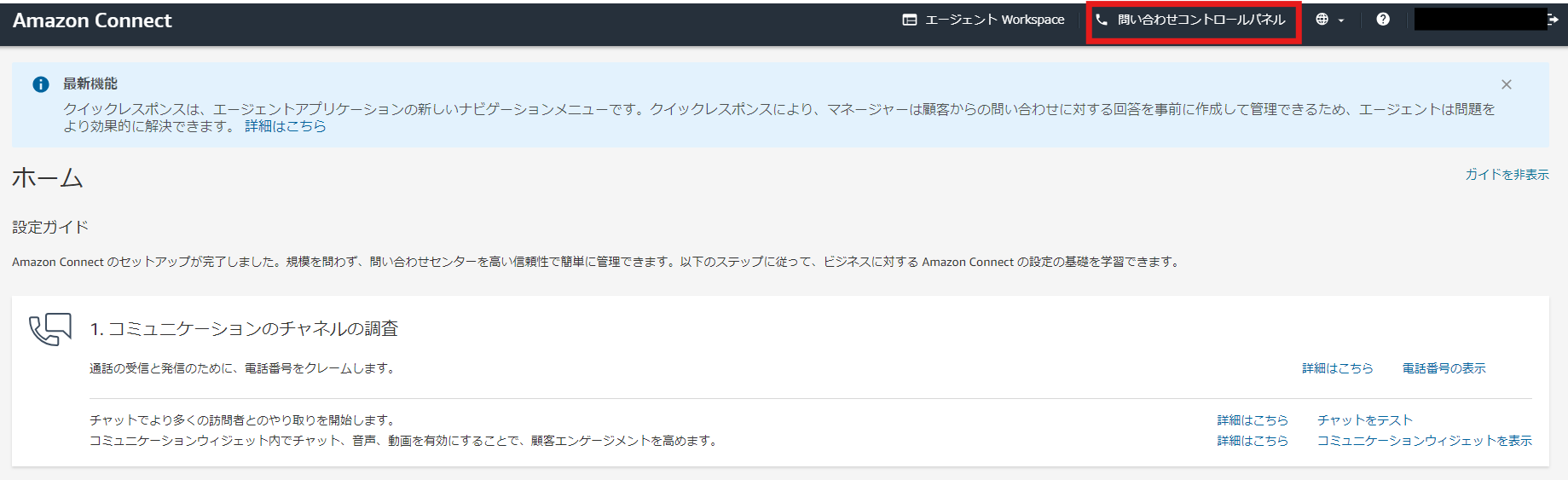
検証方法は簡単で、Amazon Connectにログインし「問い合わせコントロールパネル」をクリックしてコントロールパネルを開きます。
コントロールパネルの数値パネルで受信用の電話番号に電話をかけて、下記の文章を伝えます。
「アユサワコウヘイと申します。Aセット焼肉コースでお願いいたします。8月9日で予約をさせてください。人数は5名でお願いいたします。以上です。」
すると文字起こし格納用バケットにtemp、json、txtの3つのファイルが作成されました。
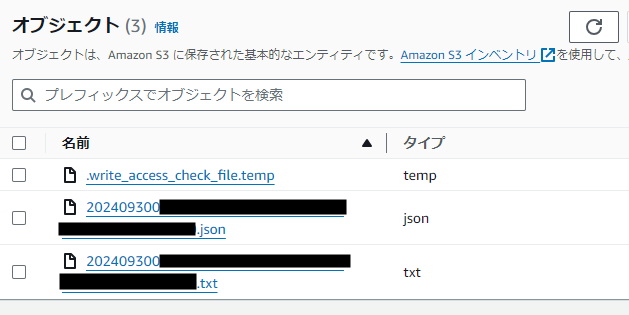
それでは文字を起こした内容がBedrockで要約され、メールアドレス宛に届いているので確認してみましょう。
まずはtempファイルから見ていきます。

.write_access_check_file.tempという名称のファイルは、Transcribeのジョブが実行される際に、アウトプット先のS3バケットに作成されます。このファイルには文字を起こしたデータは含まれていないので、この要約は正しい結果です。
次にjsonファイルです。

jsonファイルの文字を要約してくれていますね。このままでも予約内容を理解できますが、誰が、いつ、どのコースで、何名予約したのか瞬時に分からない内容となっています。
最後にtxtファイルを見ていきましょう。

jsonファイルの文字を要約した時よりも分かりやすいですね。また、精度も想像以上に良いと感じました。
ボリュームのある内容でしたが、サービス間の連携をLambdaで繋いでいくことで、簡易的な予約システムを構築することができました。
今回の検証のように要点を絞って顧客に予約内容を伝えてもらえれば、文字起こしのデータからBedrockで上手いこと要約してくれることが分かりました。また想像以上に文字起こしや要約の精度がいいことも好印象です。
本コラムの内容に加えて、予約情報を管理するためのデータベースや、オペレーターが予約一覧を確認するためのインターフェイスを構築することができれば、実際の案件でも十分に活用できそうです。
NTT東日本では、お客さまの電話業務の効率化に向け、Amazon Connect と生成AIを組み合わせた自動応答サービスも提供しています。
生成AIを活用してサービス品質の向上や業務効率化を図りたいなどあればぜひご相談ください。






自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


