
AWSにおけるシステム運用設計の必要性とポイントを解説
本コラムでは、AWSにおけるシステム運用設計の必要性やポイント、運用実現のためのサービスを紹介します。
![]()


昨今、さまざまな領域においてデジタル化が加速するなか、24時間365日ひと時も停止することなくWebサイト/サービスが稼働することが求められています。ユーザーがサービスを利用したいときに利用できることは「可用性」(availability)と呼ばれ、可用性が高いことは「高可用性」(high availability: HA)と呼ばれます。高可用性はサービスが完成してから後付けできるものではなく、計画段階から単一障害点の排除や冗長化、負荷分散といった設計の工夫が必要となります。
この記事ではWebサイト/サービスの停止を回避するために押さえておくべきポイントや、高可用性を実現するために活用できるAWSのサービスを紹介します。

Amazon.comの副社長兼最高技術責任者、Werner Vogels氏は"Everything fails, all the time"「全てのものはいずれ壊れる」という言葉を残しました。壊れないことを期待するのではなく、壊れても良いような仕組みを整えておくことが高可用性を実現するための第一歩となります。
次に、壊れても良いような仕組みを整える上でポイントとなる「単一障害点」という用語について解説します。
一般的にシステムは複数のハードウェアから構成されます。システムを構成するハードウェアの中で、それが故障してしまうとシステム全体が停止してしまうようなものを「単一障害点」(single point of failure : SPoF)と呼びます。
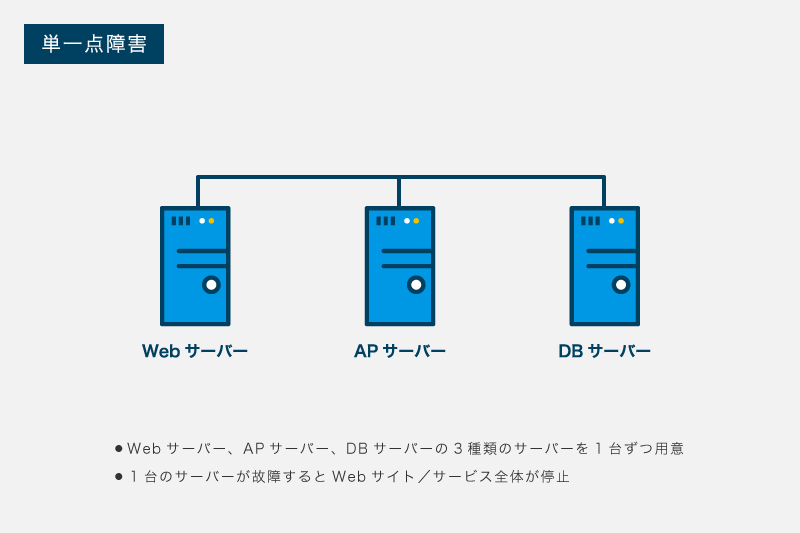
例えば、Webサイト/サービスであれば(a)ApacheやNginxなどのWebサーバー、(b)PHPやRubyなどで作成したAPサーバー、(c)MySQLやPostgreSQLなどのDBサーバーの3種類のサーバーから構成されます。仮に3種類のサーバーを1台ずつ用意する場合、1台のサーバーが故障するとWebサイト/サービス全体が停止します。この構成では、3台のサーバー全てが単一障害点となります。
単一障害点を排除することによって、システムを構成するハードウェアの一つが故障してもシステム全体は稼働し続けることができます。
次に、単一障害点を排除するためによく使用される方法である「冗長化」について解説します。
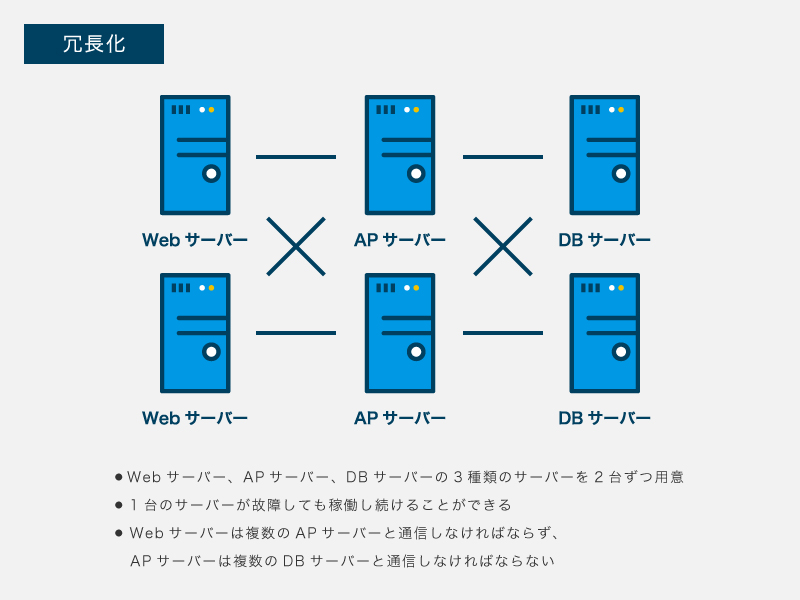
システムを構成するハードウェアの中で、あるハードウェアの予備を用意しておくことを「冗長化」(redundancy)と呼びます。冗長化によって、あるハードウェアが故障したときに予備のハードウェアと交換することによってシステムを復旧させることが可能となり、可用性が向上します。Webサイト/サービスを例にすると、Webサーバー、APサーバー、DBサーバーをそれぞれ2台用意することによって、いずれかのサーバー1台が故障しても稼働し続けることができます。
冗長化では予備の数を増やすほど可用性が向上しますが、必要以上に予備を用意しておくことは経済的ではありません。目標とするシステムの可用性や想定されるハードウェアの故障率などを考慮し、適切な数の予備を用意しておくことが重要です。
しかしながら、ハードウェアの冗長化によって、サーバーの設定やプログラムの仕様も影響を受けます。
冗長化する前は、Webサーバーは1台のAPサーバーと通信し、APサーバーは1台のDBサーバーと通信すれば十分でした。しかしながら冗長化した後は、Webサーバーは複数台のAPサーバーと通信し、APサーバーは複数台のDBサーバーと通信する必要があります。
そのためには、接続するサーバーを決定する手続きや接続したサーバーが故障している場合に別のサーバーへ接続する手続きなどが追加され、処理が複雑になります。個々のサーバーやプログラムでハードウェアの冗長化に対応することは不可能ではありませんが、プログラム開発や開発バージョンの管理などの運用負担を考えるとできるだけ避けたい業務プロセスです。
この問題を解決するために「負荷分散」という方法を使用することができます。
負荷分散とは、複数のサーバーへ処理を振り分けることで文字通り負荷を分散し、性能を向上させるための方法です。処理を振り分ける際に故障したサーバーを除外したり、サーバーの高負荷による停止を防止したりすることで可用性を高めることができます。
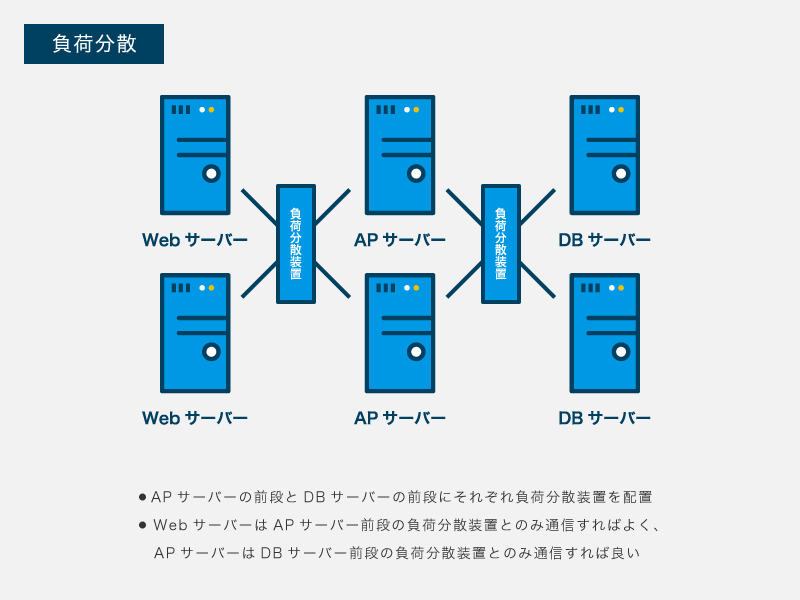
負荷分散を目的とした専用のサーバーは「負荷分散装置」(load balancer:LB)と呼ばれます。負荷分散装置には転送先のサーバーの故障を検出する「ヘルスチェック」などの可用性を高める機能を備える製品もあります。冗長化したサーバーの前段に負荷分散装置を設けることによって、個々のサーバーやプログラムで冗長化に対応することが不要となります。
例えば、Webサイト/サービスの場合、WebサーバーはAPサーバーの負荷分散装置と通信し、APサーバーはDBサーバーの負荷分散装置と通信すれば良くなります。しかし、負荷分散装置が故障した場合、配下のサーバーへ処理を振り分けられずサービスが停止します。
負荷分散装置を単一障害点にしないためには、故障時に特定のサーバーに処理を転送するフェイルスルー(fail through)や予備の負荷分散装置に役割を引き継ぐフェイルオーバー(fail over)などの工夫が必要となります。
ネットワークからクラウドの導入・運用までトータルでサポート!
AWSには可用性を高めるためのサービスがあります。その一部をご紹介いたします。
Elastic Load Balancing(ELB)はAWSの負荷分散サービスであり、自社で仕組みを整えることなく簡単に負荷分散を実現することができます。ELBには、HTTP/HTTPSリクエストを振り分ける"Application Load Balancer"とTCPリクエストを振り分ける"Network Load Balancer"に加え、過去のバージョンである"Classic Load Balancer"の3種類があります。
Webサイト/サービスの場合はApplication Load Balancerを利用するケースが多いです。
ELBの料金体系は時間当たりの課金であり、(a)Application Load Balancerの利用時間と(b)使用量に応じて増減するロードバランサーキャパシティーユニット(load Balancer capacity unit : LCU)の2つによって決定します。
仮にApplication Load Balancerの1時間当り利用時間単価が0.0243USD、1LCUの1時間当りの利用時間単価が0.008USDとして、1ヵ月常時1LCUを使用し続けた場合、24時間 × 30日 × (0.0243USD + 0.008USD) = 23.256USDの利用料金が発生します。
2019年10月現在のAWSホームページの情報を参照しております。具体的な料金については個別にご確認ください。
https://aws.amazon.com/jp/elasticloadbalancing/pricing/![]()
ELBはAWS Auto Scalingと組み合わせ、サーバーが停止したり負荷が高くなったりした場合に、自動的に追加のサーバーを起動するように設定することが可能です。
負荷分散を実現するにあたりELBやAWS Auto Scalingを手作業で設定することもできますが、AWS Elastic Beanstalkというサービスを利用することで簡単に素早く行うことができます。AWS Elastic Beanstalkは、ELBやAWS Auto Scalingを活用した高可用性なWebサイト/サービスを自動で構築してくれるサービスです。ユーザーはプログラムをアップロードするだけで良く、設定に要する時間を短縮すると共に手作業によるヒューマンエラーの発生を軽減することができます。
AWS Elastic Beanstalk自体の利用では費用は発生しませんが、AWS Elastic Beanstalkを利用して起動したサーバーなどについてはEC2などの料金が発生します。
2019年のAWS東京リージョンで発生した障害など、クラウドの障害が発生するときに、「クラウドはもろいのか?」といった議論がなされます。
しかしながら「クラウドはもろいのか?」という議論に答えはなく、目標とする稼働率を実現できるシステムをクラウド上で構築できるかという観点が重要になります。たとえクラウドを利用したとしても、障害発生時に可用性を維持できるような設計になっていなければサービスは停止してしまいます。
したがって、高い可用性が求められるサービスであれば、複数のリージョンに同じシステムを構築し、障害発生時に正常に稼働しているシステムに切り替えるような仕組みにするなどの対策が求められます。
オンプレミスシステムでの設計と同様に、可用性が高く、かつ、運用負担ができるだけ軽い、クラウドを活用したシステム設計が重要です。AWSのサービスを活用することによって可用性の高いWebサイト/サービスを簡単迅速に構築することができます。高可用性に対するユーザーの期待は今後ますます高くなっていくと予想され、期待に応えるために知っておくべきポイントや実現方法を確認しておくことが大切です。
クラウド運用に興味がある人に読んで欲しいコラム:





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


