


サーバー管理とは?わかりやすく解説|業務内容から手間を省くポイントまで
本コラムでは、そもそもサーバーとは何かという基本的なところから、業務内容・サーバー管理者に求められるものまで、幅広く解説します。
![]()


サーバー障害とは、サーバーにトラブルが発生し、機能が停止してしまうことです。サーバーを構成する機器に障害が起こる場合もあれば、ソフトウェアに問題が発生するケースもあります。サーバーに障害が起こると、サービスやシステムが利用できなくなるなど、その影響は甚大です。

サーバー障害の原因は、アクセス集中による負荷やサイバー攻撃など、多岐にわたります。それだけに、サーバー障害は誰にでも起こりうるトラブルと言えるでしょう。

ただし、サーバー障害はあらかじめ対策を行っておくことで、その発生リスクを抑えたり、被害を最小限に食い止めたりすることができます。また、万一サーバー障害が発生してしまった場合の対処法を知っておくことで、スムーズに復旧作業に移行することができるようになるでしょう。
なお、すでにサーバー障害が起こっている場合は、こちらからご確認ください。
サーバー障害は影響が大きいトラブルだからこそ、このような適切な対応を把握しておくことが欠かせないのです。
そこで、この記事では、サーバー障害の意味や影響・原因といった基礎知識から日常的に行える対策まで、幅広く解説します。
サーバー障害かどうか見分ける方法や、起こってしまったときの対処の流れもご紹介していますので、確認しておけば、いざというときにも落ち着いて行動することができるようになるでしょう。
| 【この記事の内容】 |
|---|
|
以上のような内容を把握しておくことで、サーバー障害の基本を理解し、トラブルのリスクや発生時の損失を最小限に抑え、安定したシステムやサービスの運用をすることができるようになります。

目次:

サーバー障害とは、サーバーの機器やソフトウェアに異常が発生し、機能が停止してしまうトラブルのことです。サーバーへのアクセスの集中による過負荷・機器の老朽化などさまざまなことが原因で、サーバー障害が起こります。
サーバーは、サービスや情報・機能などを提供する役割を持ったコンピューターやソフトウェアのことです。Webサイトの閲覧やメールの送受信、データベースや業務用のシステムなど、さまざまな場面でサーバーが稼働しています。
ひとたびサーバー障害が起これば、そのサーバーが関係するサービスやシステムが利用できなくなってしまいます。企業であれば、影響は大きく多大な損失につながりかねません。
◆サーバー障害が起こると発生する影響の例
サーバー障害が発生すると、復旧するまで、関係するサービスやシステムは止まったままです。復旧までに要する時間の目安はサーバー障害の原因によって異なり、概ね数時間から数週間程度かかります。
◆サーバー障害から復旧するまでの目安時間
※復旧時間参考サイト:
サーバーダウン時の復旧にはどのくらい時間が掛かりますか? - よくあるご質問と回答
サーバーダウンとは?発生原因や損失、対策方法を解説 (sint.co.jp)
【原因別】サーバーダウンの対処法と復旧までの時間を解説 | WordPressの引越し代行なら『サイト引越し屋さん』 (site-hikkoshi.com)

サーバー障害が起こる原因は、さまざまです。ここでは、代表的な原因を5つ確認してみましょう。
| サーバー障害の主な原因 |
|---|
|
1. アクセス集中による過剰な負荷 2. サイバー攻撃 3. 機器の障害 4. OSなどソフトウェアの不具合 5. 人為的なミス |
各原因の詳しい内容は、以下をご確認ください。
アクセスが集中しサーバーに過剰な負荷がかかると、サーバー障害が発生します。
サーバーの処理能力を超えるアクセスが集中すると、リクエストを処理できなくなり、機能が一時的に停止してしまうからです。
例えば、Webサイトがネットニュースで紹介されたり、ECサイトでキャンペーンを実施したりしたときに、予想を超えるアクセスが集中しやすくなります。
アクセス集中が予想される場合や、アクセス集中によるサーバー障害がよく発生しているなら、サーバーの強化や負荷分散などの対策を行いましょう。
サイバー攻撃を受けた場合にも、サーバー障害が起こる可能性があります。
サーバー障害が引き起こされるリスクのある攻撃には、DDoS攻撃・ウイルス感染・不正アクセスなどがありますが、中でも特にDDoS攻撃に注意が必要です。
DDoS攻撃とは、サーバー障害を起こさせることを目的としたサイバー攻撃で、複数の端末から大量のリクエストを送り付け、人為的にアクセス集中によるサーバーに対する過剰な負荷を作り出します。
サーバーを構成する機器に老朽化や故障による障害が発生し、サーバー障害が引き起こされることがあります。
物理サーバーを利用している場合は、部品やハードディスクが老朽化しやすいので注意が必要です。特に以下のようなケースでは、機器の障害が起こりやすくなります。
◆物理サーバーが故障しやすいケース
特に、高温多湿状態は機器の寿命を早めるので、対策をしっかりと行うことが大切です。
ソフトウェアのプログラムに存在するバグも、サーバー障害の原因の一つです。
OSをインストールした直後や設定を変更したりメンテナンスを行ったりした場合などに、不具合が起こりやすくなります。
使い始めやこれまでと環境を変えたときは、サーバー障害のリスクが高まることを念頭に置いて、テストをしっかり行い様子を見ながら本格稼働させていくと、影響を小さく抑えられるでしょう。
サーバー障害は、人為的なミスによっても発生します。
ちょっとした設定ミスやデータの破損で、サーバーは稼働しなくなることがあるからです。
よくある人為的ミスの例を見てみましょう。
◆サーバー障害に発展しやすいよくある人為的ミス

サーバー障害に備えて日頃から対策を行っておくことで、発生リスクや発生時の被害を抑えることができます。
| サーバー障害に備えて日頃からできる対策 |
|---|
|
1. サーバーを冗長化する 2. バックアップを行う 3. 負荷を分散する 4. 監視システムを導入する 5. 障害対応の体制やマニュアルを整備する |
誰もが直面するリスクのあるトラブルだからこそ、できるだけ対策を取っておきましょう。
サーバーの冗長化をしておくことで、もしサーバー障害が発生しても、業務などを停止することなく復旧にあたることができるようになります。
冗長化とは、メインのサーバーが故障してもすぐに予備と入れ替えられる状態にしておくことです。具体的には、メインのサーバーと機能や保存データなどがまったく同じのサーバーをもう1台準備します。冗長化するには、予備のサーバー内のデータを常にメインのサーバーと同期させておく必要があります。
特に、予備の電源を常時入れておくホットスタンバイにしておけば、サーバー障害時も、ほとんどタイムラグなく予備サーバーへ移行することができるでしょう。
サーバー障害時にスムーズに復旧を進められるようにするために、サーバーの運用に関するデータのバックアップを取っておきましょう。
サーバー障害が発生した際に、データも損傷してしまう危険性があるからです。特に機器の故障が原因のサーバー障害では、データが消えるリスクが高くなります。
急にアクセスが集中したときでも、複数のサーバーに負荷を分散する仕組み(ロードバランサー)を導入しておけば、サーバー障害の発生リスクを減らすことができます。
負荷分散できるようにしておけば、想定外にアクセス数が増加したときや、DDoS攻撃を受けた場合でも、サーバー障害に陥らずに済む確率が上がるからです。
さらに、
といった、サーバー障害を予防する以外の効果も見込めます。
サーバー監視システムとは、ソフトウェアをインストールすることで使えるようになる、サーバーの状態を常に監視し異常があれば通知するサーバー監視システムのことです。サーバー監視システムを導入しておけば、サーバー障害のリスクを抑え、万一サーバー障害が発生した時も、早期復旧させやすくなります。
24時間体制でサーバーの状態をチェックできるサーバー監視システムを導入すれば、サーバーの異常を早期発見し、早期対応することができるからです。
監視システムの種類によっては、
などの機能があり、トータルでサポートを受けることもできます。
サーバー障害が発生したらどのような対応を取るのか、障害対応の体制やマニュアルを整備しておくことで、もしもの時もスムーズに復旧させることができます。
障害は、いつ発生するかわかりません。サーバーに詳しい担当者がたまたま居ないときや深夜などに、発生することもあるでしょう。
そのような場合でも、そのとき対応できる人が何をどのようにすればよいのかわかるようにしておくことで、サーバー障害の被害を最小限に抑えることができます。
◆マニュアル作りのポイント

「システムやサービスに不具合があるみたいだけれど、サーバー障害なの?」
そのようなときは、以下の点を確認することで、サーバー障害なのかどうかが判断しやすくなります。
| サーバー障害かどうか確認する方法 |
|---|
|
1. 社内の全員が機能を使えないかどうかを確認する 2. お知らせやSNS・ニュースを確認する |
速やかにサーバー障害の可能性が高いのかどうかを判断して、スムーズに次の対応に移れるように、確認方法を押さえておきましょう。
社内でサービスやシステムが使えないときに、サーバー障害かどうか判断に迷ったら、他の従業員も皆使えないのかなど、全体的な利用不能状態かどうかを確認してみましょう。全体的に使えないならサーバー障害の可能性が高く、一部にとどまるなら他の要因である可能性が高くなります。
◆サーバー障害の可能性が高い具体例
社内など自分で管理しているサーバーではなく、外部のサーバーを利用しているなら、お知らせやSNS・ニュースを確認するのがおすすめです。
情報の正確性では、公式ホームページのお知らせが最も確実ですが、第一報が出るまでにタイムラグがある場合もあります。そこで、SNSやネットニュースの情報をあわせて参考にすることで、同じ状況の利用者が他にもいるのか確認することができて、原因を特定しやすくなるでしょう。

サーバー障害が発生してしまったら、基本的には次のような流れで対処をすると、混乱を最小限に抑えて復旧にあたることができます。
「サーバー障害時の対応の流れをまだ整理していない」という場合は、この流れを参考にしてください。
サーバー障害が起きたことがわかったら、最初にすべきことは、障害によって、どの範囲にどの程度の影響が出るのかを特定することです。
|
①どの範囲? |
|
|---|---|
|
②どの程度? |
|
影響範囲を具体的に特定できればできるほど、以降のステップをスムーズに進められ、混乱も少なくて済みます。いざというときに、すぐに影響範囲を特定できるように、平時からシステム同士のつながりや利用形態などを整理しておくとよいでしょう。
サーバー障害の影響範囲を確認できたら、関係する部署に速やかに連絡し情報共有をしましょう。
情報共有するときのポイントは、次のとおりです。
◆サーバー障害の情報共有をするときのポイント
特に顧客や取引先など対外的に影響が出そうなケースでは、正確な最新情報を共有しておかないと、責任問題などに発展しかねず信頼を失うことにもなりかねないので、注意が必要です。
なお、サービスやシステムの利用にまったく影響を出さずに復旧できるなら、上記のような情報共有は行わず、事後的な報告でも差し支えないでしょう。
関係する部署への情報共有が終わったら、サーバー障害の切り分けを行い、原因を特定しましょう。
切り分けとは、サーバーの各レイヤーのどの部分に問題があるのかを確認していく作業のことです。
| サーバーのレイヤー | |
|---|---|
| ①ハードウェア | 機器類(CPUやハードディスクなど) |
| ②OS | Windowsなど基本となるソフトウェア |
| ③ネットワーク | 社内LANやキャリア提供のネットワークなど |
| ④アプリケーション | OSの上で機能する個別のソフトウェア |
| ⑤サービス | Webサイトや実際に利用するシステムなど |
切り分けは、上記の①から番号順に行っていくのが基本的な進め方です。
サーバー障害の原因がどのレイヤーにあるのか特定できたら、復旧作業を行います。
復旧完了までの時間が短く済むほど、サーバー障害による損失を最小限に抑えることが可能です。
この段階までくれば概ねの復旧時期の目途もついてくるので、関係する部署に、復旧見込みや作業の進捗を情報共有しておきましょう。
サーバー障害の復旧が完了したら、最後に、再発防止策を検討することが重要になります。サーバー障害の原因によっては、何も対策を打たないとサーバーダウンを繰り返す可能性があるからです。
特に、アクセスが集中したことによる過剰な負荷が原因のサーバー障害は、またアクセス集中が起こればサーバーは止まります。
例えば、
などの対策を検討してみましょう。
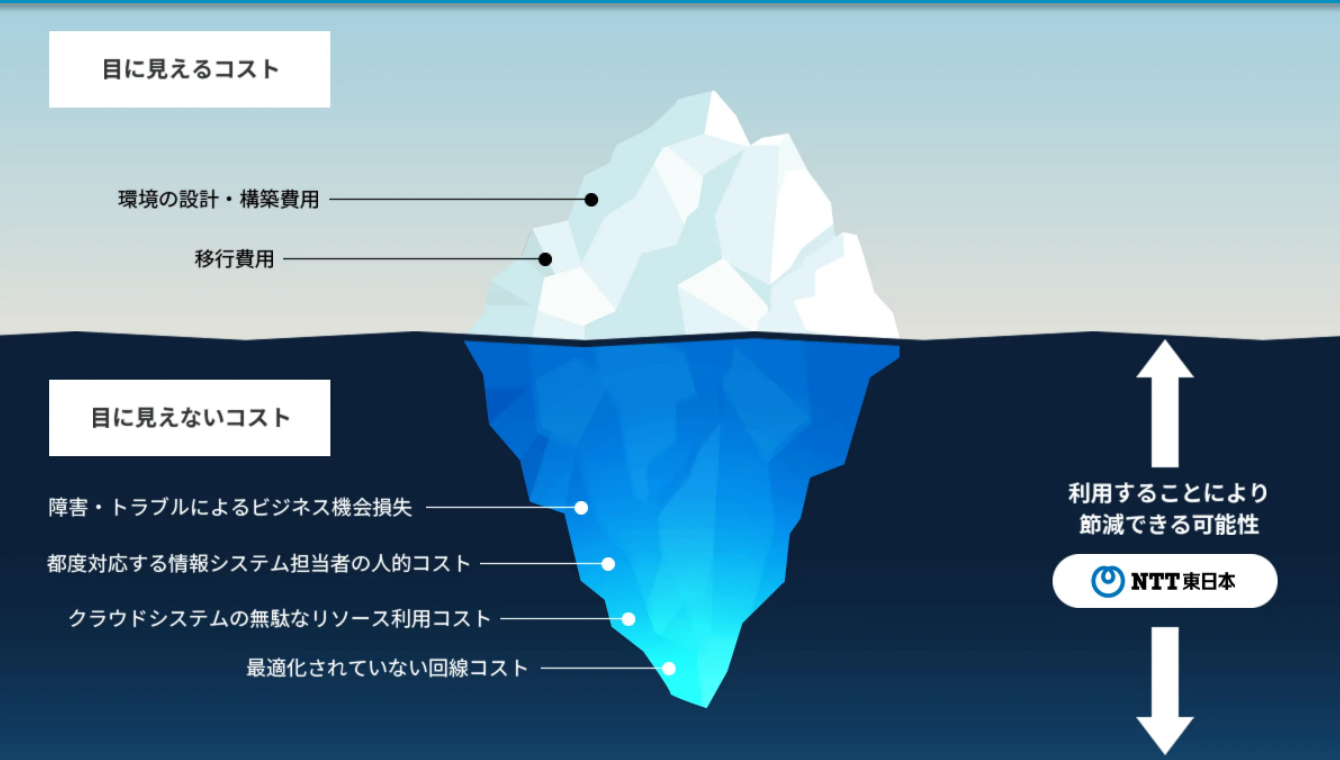
| サーバー障害のリスクを抑えてIT環境を構築するならNTT東日本のクラウド! |
|---|
|
「サーバー管理の手間を最小限にしたい」 「最適な環境を整えたいが、コストは抑えたい」 そのようにお考えでしたら、NTT東日本のクラウド導入・運用サービスの利用をおすすめします。 クラウドを活用すれば、初期コストやサーバー管理の手間を抑えて、万一サーバーにトラブルが発生しても、対応に労力を割かなくて済む環境を簡単に構築できるからです。 NTT東日本には、AWS認定有資格者をはじめとするクラウドのプロフェッショナルが多数在籍し、150を超えるクラウド導入実績に基づく豊富なノウハウがあります。 だから、
など幅広く専門的な対応が可能です。クラウドサービスはAWS(Amazon Web Services)、Microsoft Azureなど複数取り扱っておりますので、お気軽にお尋ねください。 また、NTT東日本では、初期コストはもちろんのこと、導入開始後の保守管理や周辺環境のコストまで含めて、最適なプランをご提案しています。だから、「導入費用は安かったけれど、労力がかかった」「関係するシステムやソフトウェアの調整で、かえって高くついた」などの失敗がありません。
端末・ネットワーク・クラウドのすべての領域において、現在の悩みやご要望をお聞かせください。安心して業務に専念できる環境の構築を実現いたします。 まずは、お気軽にお問い合わせください。
※Amazon Web Services(AWS)は、米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。 ※Microsoft Azureは、Microsoft Corporationの米国及びその他の国における登録商標または商標です。 |
サーバー障害とは、サーバーの機器やソフトウェアに異常が発生し、機能が停止してしまうトラブルのことです。サーバー障害が起これば、そのサーバーが関係するサービスやシステムが利用できなくなってしまいます。
サーバー障害の代表的な原因は、次のとおりです。
| サーバー障害の主な原因 |
|---|
|
1. アクセス集中による過剰な負荷 2. サイバー攻撃 3. 機器の障害 4. OSなどソフトウェアの不具合 5. 人為的なミス |
サーバー障害の発生リスクを抑えるために、また、発生時の被害を最小限に抑えるために、日頃からできる対策があります。
| サーバー障害に備えて日頃からできる対策 |
|---|
|
1. サーバーを冗長化する 2. バックアップを行う 3. 負荷を分散する 4. 監視システムを導入する 5. 障害対応の体制やマニュアルを整備する |
現在の不具合がサーバー障害かどうか確認する方法は、次のとおりです。
1. 社内の全員が機能を使えないかどうかを把握
2. お知らせやSNS・ニュースを確認
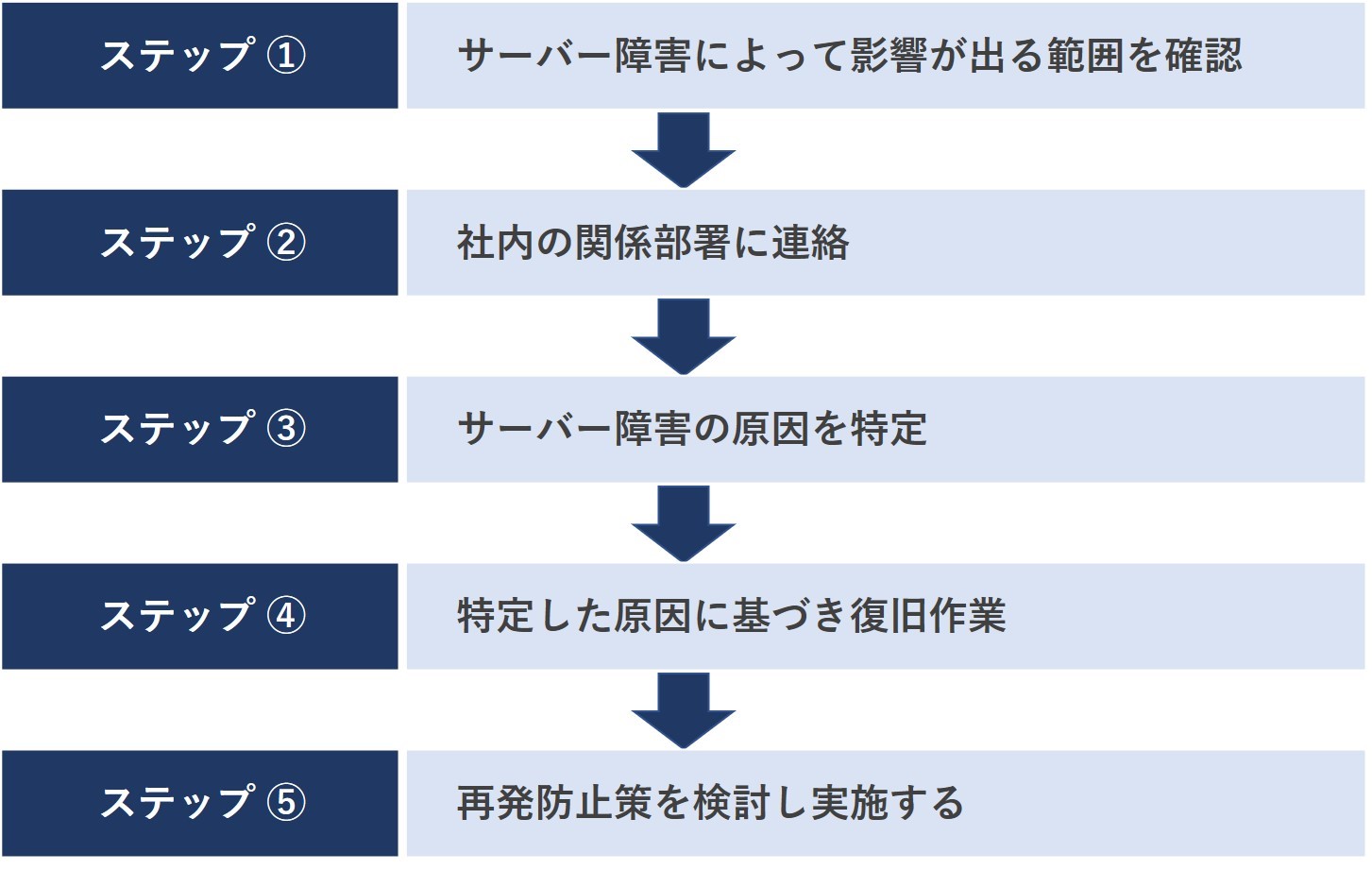
サーバー障害が起こった場合の基本的な対処方法は、次の5ステップになります。
| サーバー障害が起こった場合の対処方法5ステップ | |
|---|---|
| ステップ① | サーバー障害によって影響が出る範囲を確認 |
| ステップ② | 社内の関係部署に連絡 |
| ステップ③ | サーバー障害の原因を特定 |
| ステップ④ | 特定した原因に基づき復旧作業 |
| ステップ⑤ | 再発防止策を検討し実施する |
サーバーによって提供されるシステムやサービスを多く活用する現代において、サーバー障害とは無縁ではいられません。原因や対処法を正しく理解し、できるだけ発生リスクを抑えるとともに、サーバー障害発生時の損失を最小限にとどめるよう、日頃から対策していきましょう。
ネットワークからクラウドまでトータルサポート!!
NTT東日本のクラウド導入・運用サービスを確認してください!!





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


