
クラウドとオープンソース活用によるSFA/CRM環境のコスト削減の実現
SFA/CRMが利用されている理由や利用でのお悩みを解説します。
![]()


AWS Lambdaの一般的な利用方法の中から1つを取り上げ、環境構築からLambda関数の作成および動作確認までの一連の作業手順を詳細に解説しています。
今回はAmazon Kinesis Data Streamsのストリーミングデータを処理するLambdaの作成手順をAmazon Kinesis Data Streamsの構築手順と併せて解説します。
Amazon Kinesis Data StreamsはAmazon Kinesisの機能の一つで、センサーやコンピュータ等から次々に送られてくる大量のデータを独自アプリケーションやS3、DynamoDBなどAWSの他のサービスへ高速に転送するためのサービスです。シャードと呼ばれる単位で並列処理することで大量のストリーミングデータを高速に転送することができます。主に大量のストリーミングデータをリアルタイムに処理、分析する用途に利用されます。ユースケースとして以下のようなものがあります。
Amazon Kinesis Data Streamsにはストリーミングデータの入出力をサポートする専用のライブラリが提供されています。
Amazon Kinesisについて詳しくは「Amazon Kinesisの主な機能と使い方 − 強力なストリーミングデータ処理![]() 」を参照してください。
」を参照してください。

動作の全体像を以下に示します。
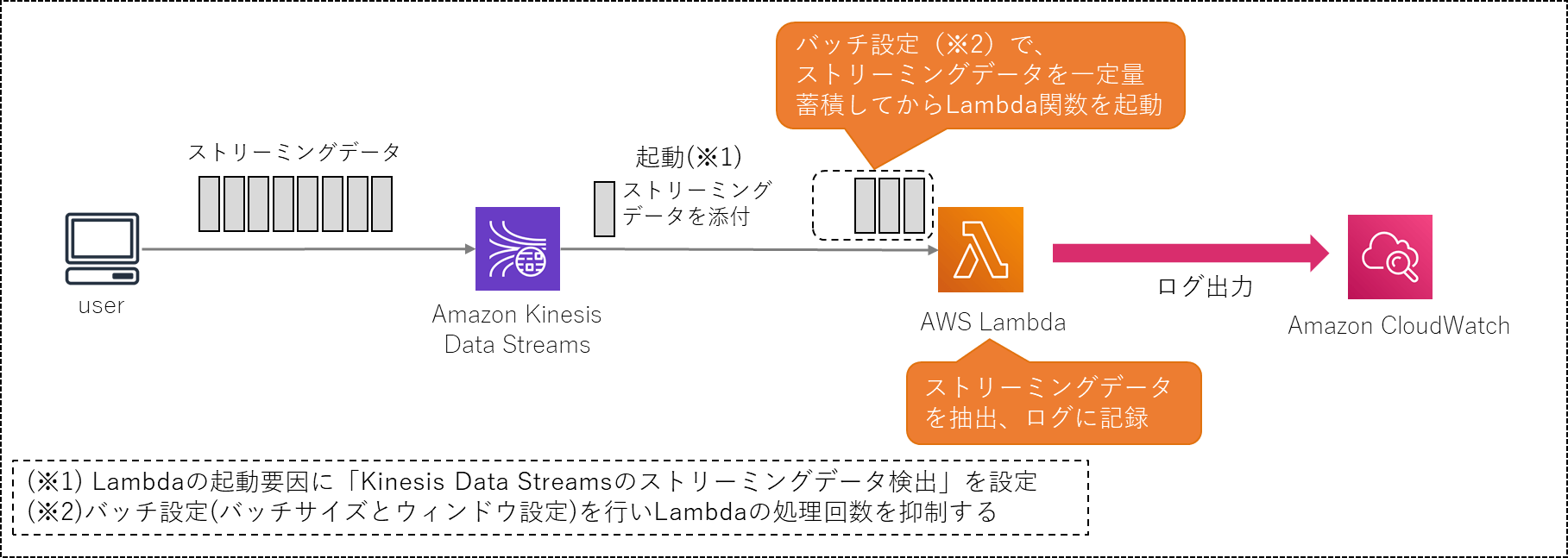
動作概要
Amazon Kinesis Data Streamsの所定のストリームにストリーミングデータを受信するとAWS Lambdaが起動されます。
大量のストリーミングデータを一つ一つLambdaで処理すると、Lambdaの実行回数が膨大になり、コスト面と処理能力の面から見て非効率的です。そこで一定量のストリーミングデータをまとめてからLambda関数で処理するようバッチ設定を行います。
Lambda関数では引数からストリーミングデータを取り出し、ログに記録します。
Amazon Kinesisサービスのコンソール画面を開きます。
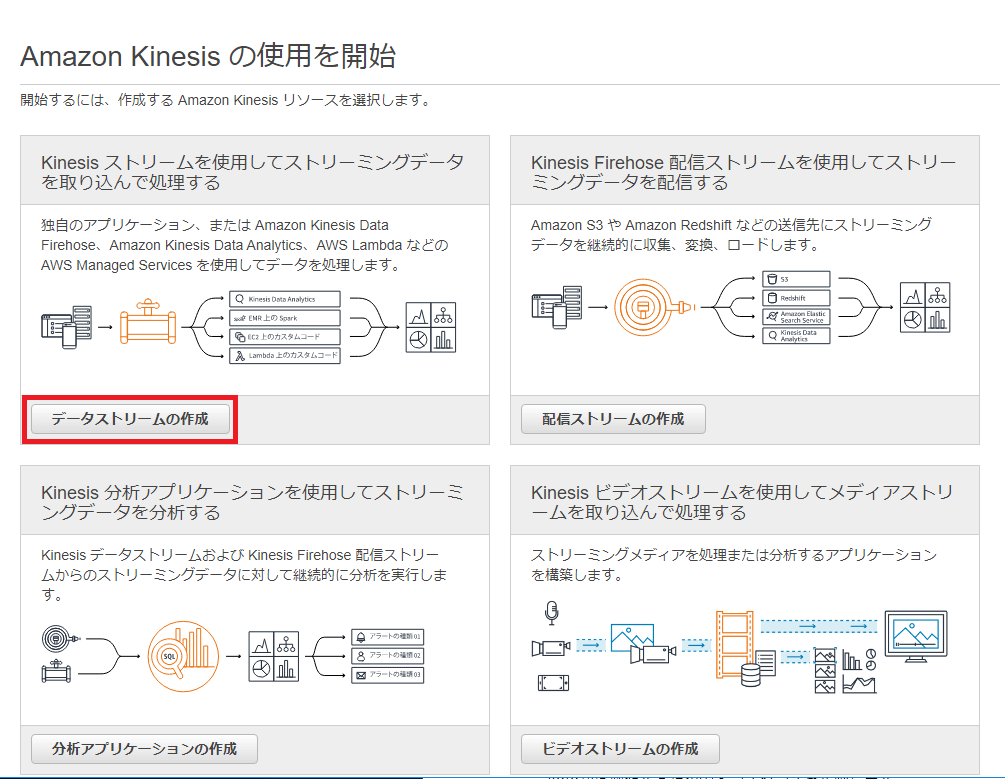
以下の画面が表示されるので「今すぐ始める」ボタンを押下してKinesisストリームを作成します。

4つの選択肢から「データストリームの作成」を選択し、ボタンを押下します。
Kinesisストリームの作成画面で以下を設定し画面右下の「Kinesisストリームの作成」ボタンを押下します。
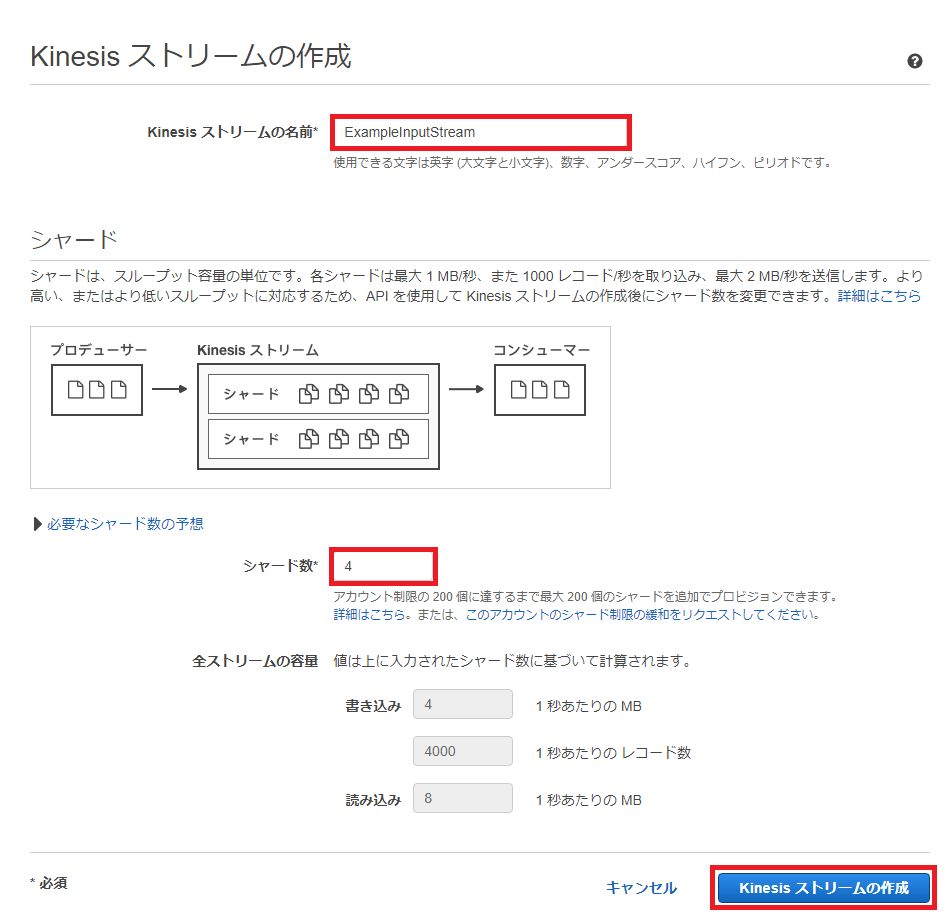
(※) シャードはAmazon Kinesisストリームにおけるスループットの基本単位です。
1シャードの処理能力は以下になります。
シャード数は通信量と要求されるスループットによって決定します。今回の例では通信量を考慮せず、ひとまず「必要なシャード数の予想」より多目の数を設定しています。
実際の運用では、上図の「必要なシャード数の予想」を参考にシャード数を決定してください。
尚、実際の通信量に対し、作成したシャード数が多い場合は必要なシャード数だけ実行されます。
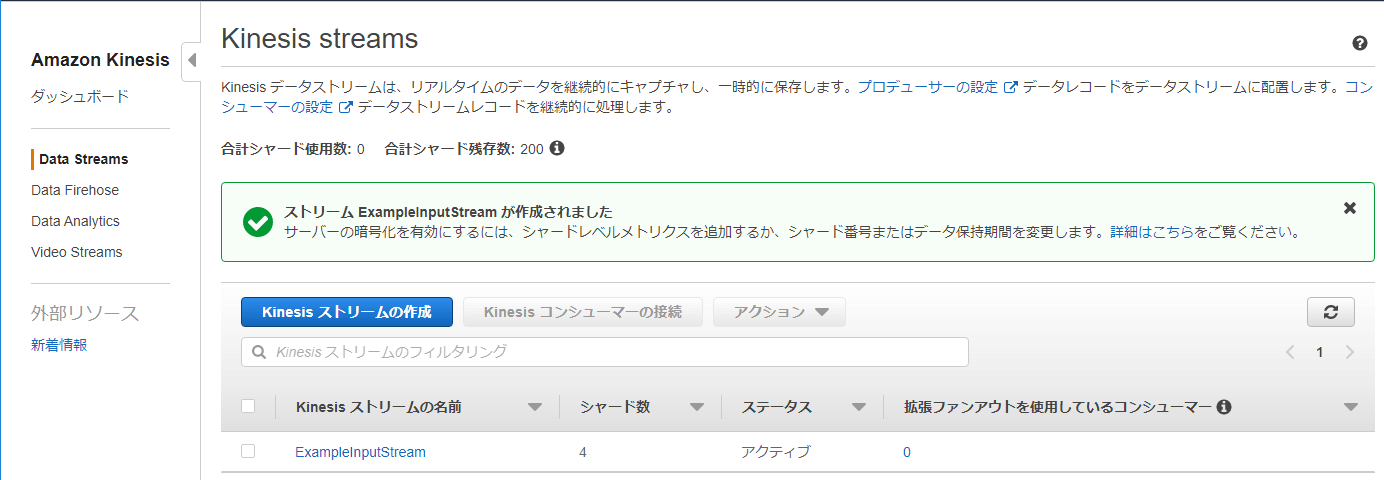
Data Streamsの一覧に作成した「ExampleInputStream」が表示されます。
IAMコンソール画面から左サイドメニューの「ロール」を選択します。
ロール画面で「ロールの作成」ボタンを押下します。
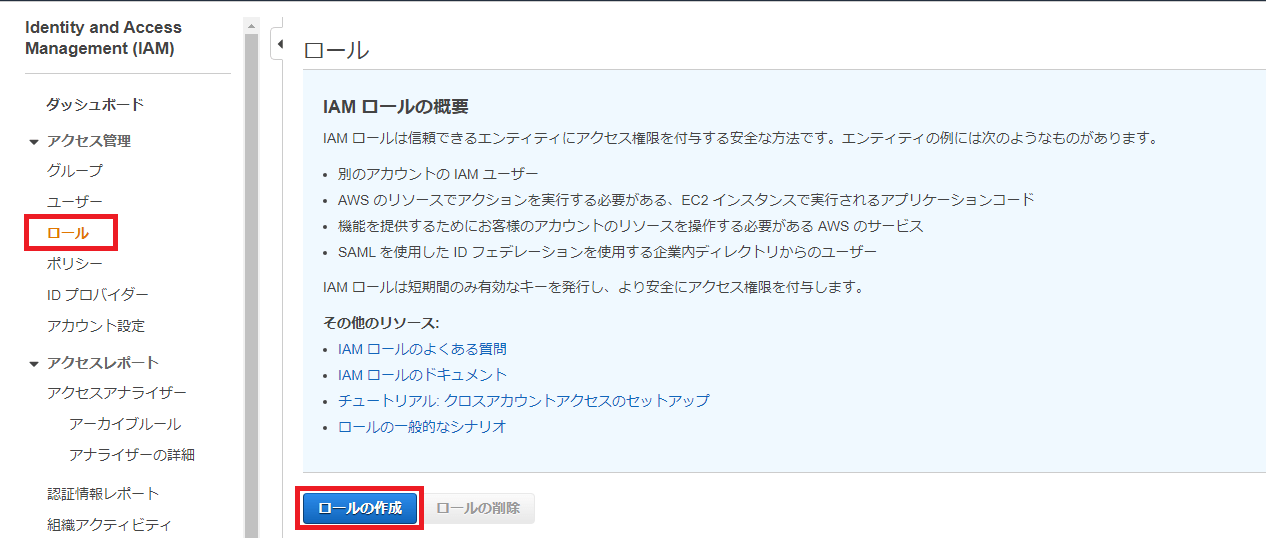
「ロールの作成」画面が開くので、デフォルトで選択されているエンティティの種類「AWSサービス」で表示されているユースケースから「Lambda」を選択します。
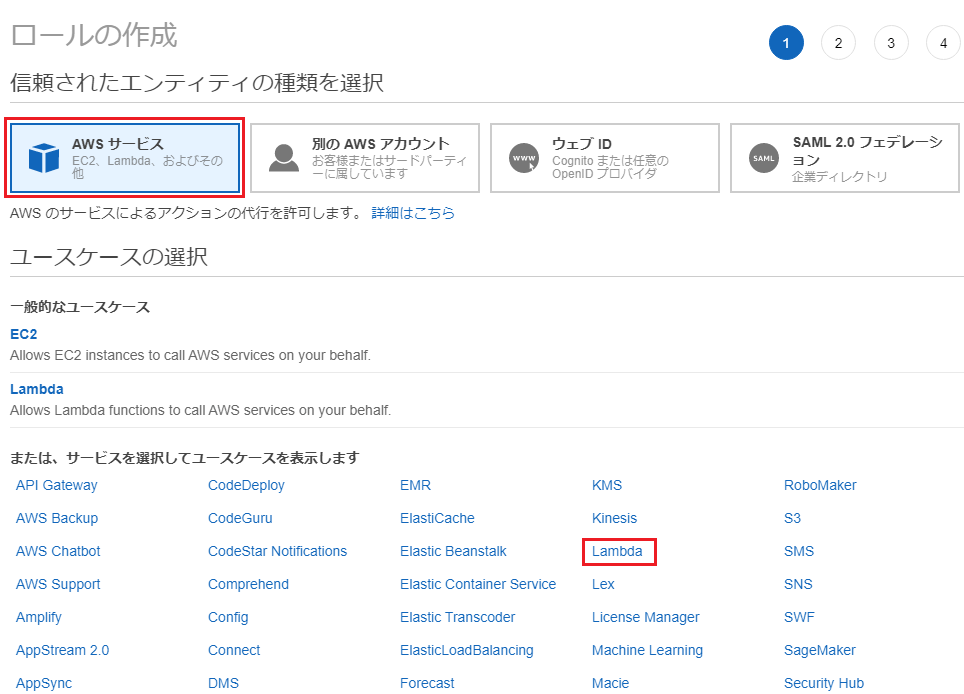
「ユースケースの選択」画面が表示されるので「次のステップ:アクセス権限」ボタンを押下します。

「Attachアクセス権限ポリシー」画面が開くので、ポリシー一覧から「AWSLambdaKinesisExecutionRole」を選択し、「次のステップ:タグ」ボタンを押下します。
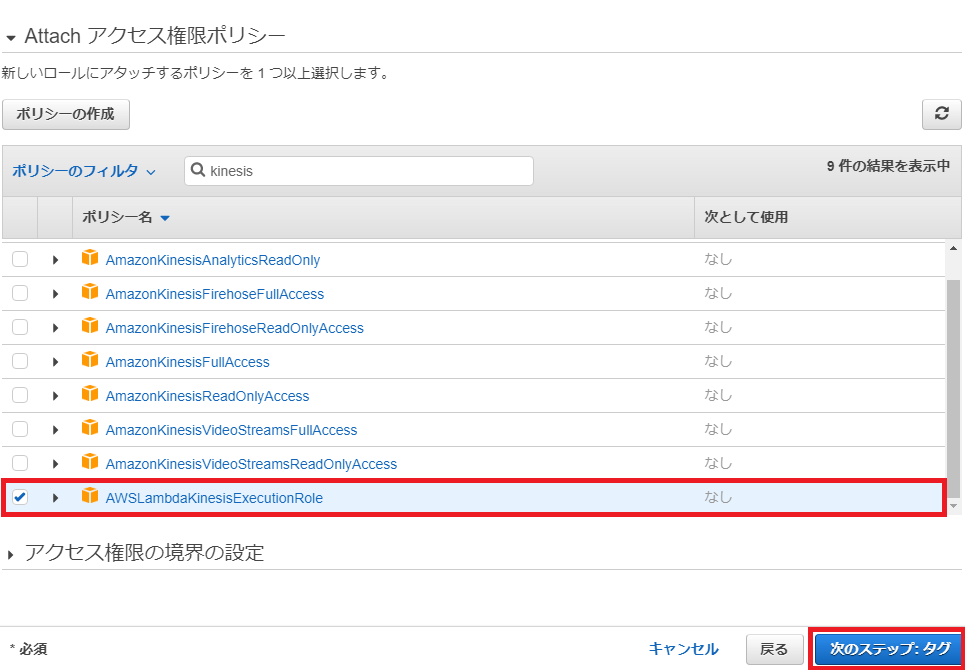
「タグの追加(オプション)」画面が開くので何もせず「次のステップ:確認」ボタンを押下します。
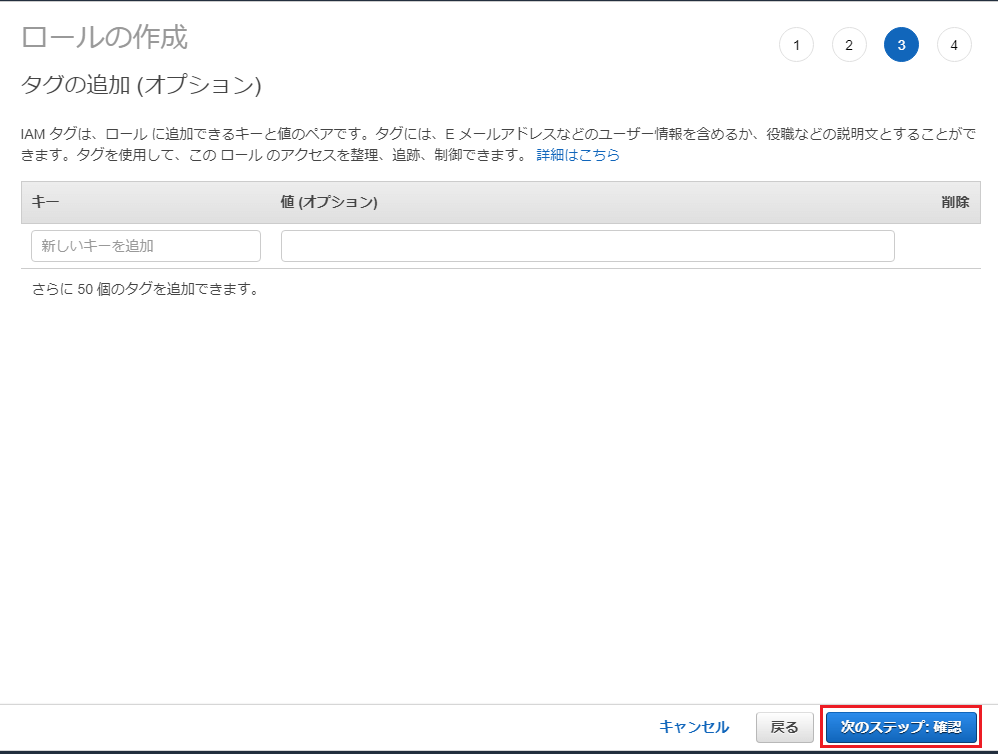
「確認」画面が開くので「ロール名」に「lambda-Kinesis」と設定し「ロールの作成」ボタンを押下します。
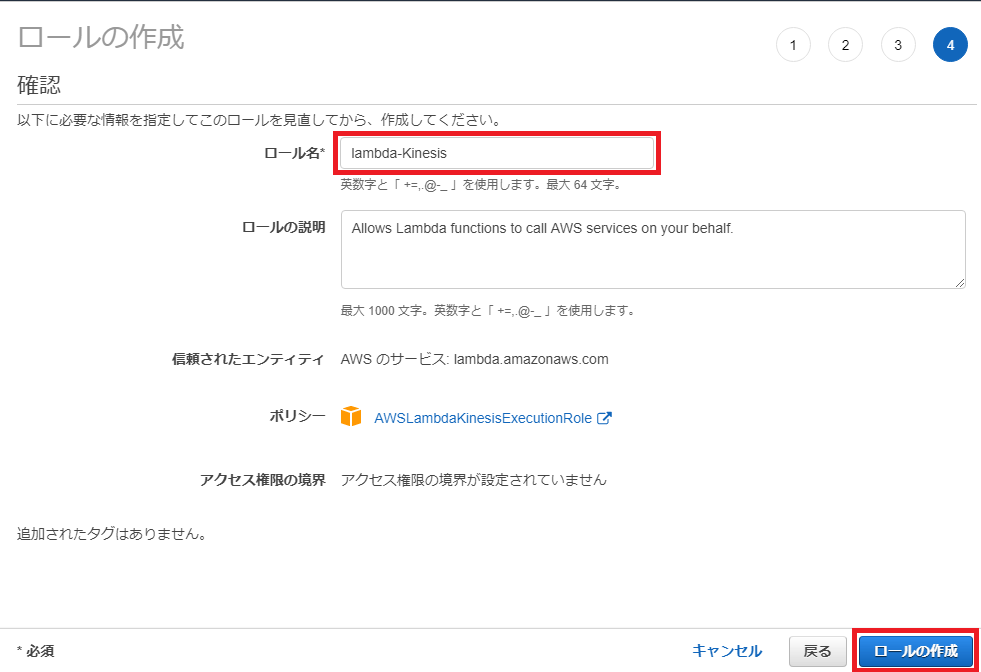
Kinesis Data Streamsのストリーミングデータを処理するLambdaを作成します。
今回はAWS Lambdaが提供しているテンプレートをそのまま使用します。
Lambdaのコンソール画面から「関数の作成」ボタンを押下します。
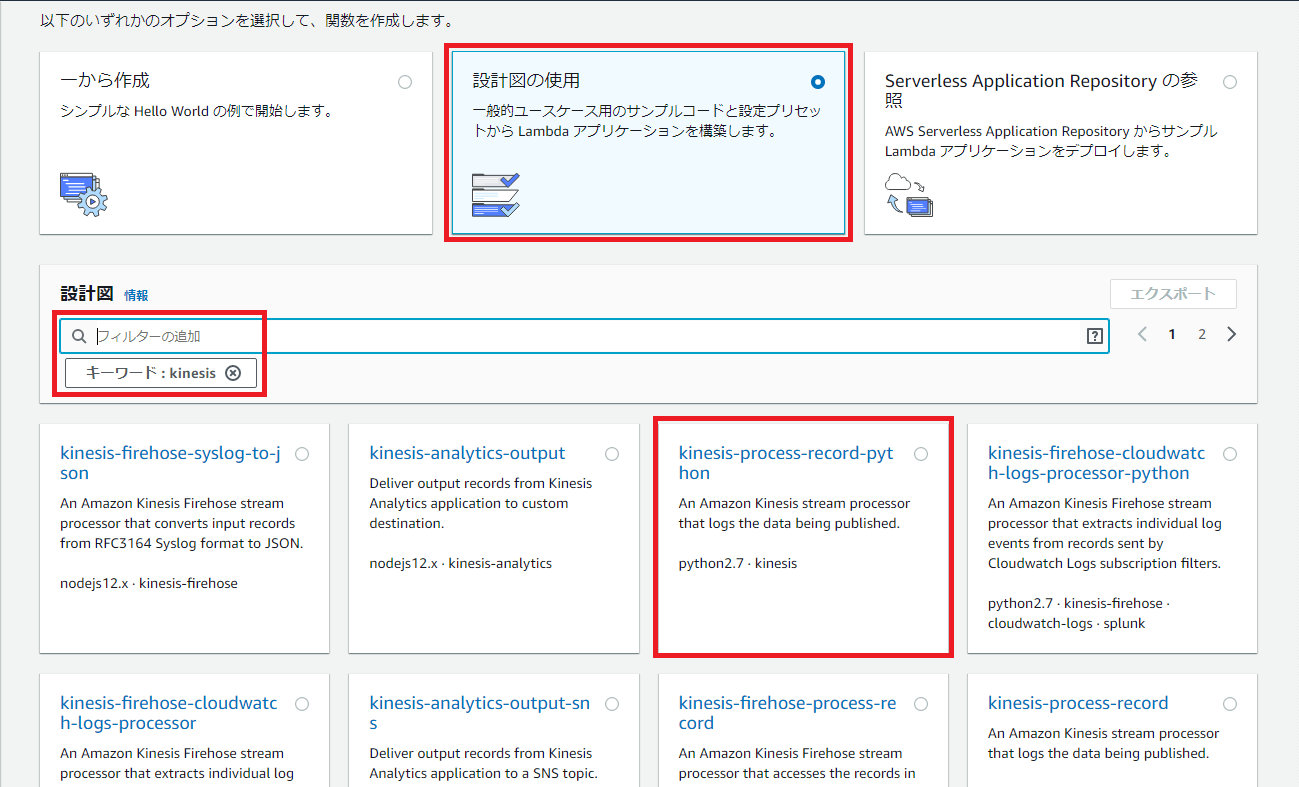
「関数の作成」画面のオプションの中から「設計図の使用」を選択します。
「設計図」の検索キーワード入力欄に「kinesis」と入力します。
表示された候補から「kinesis-process-record-python」を選択します。
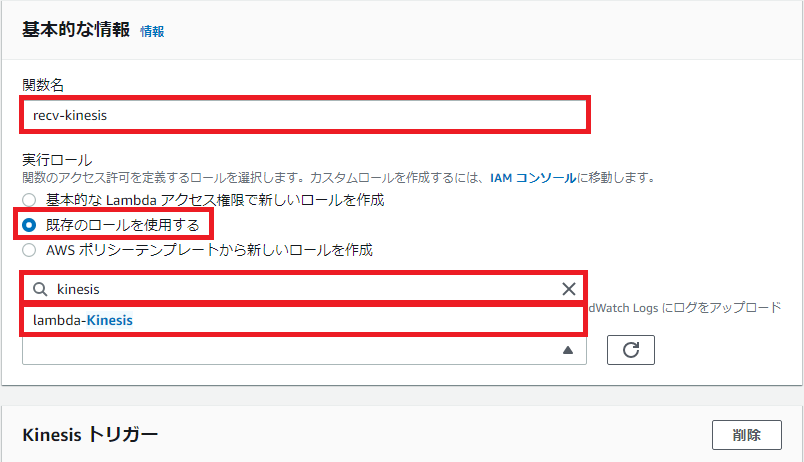
「基本的な情報」の設定項目に以下を設定します
「Kinesisトリガー」の設定項目で以下を設定します。
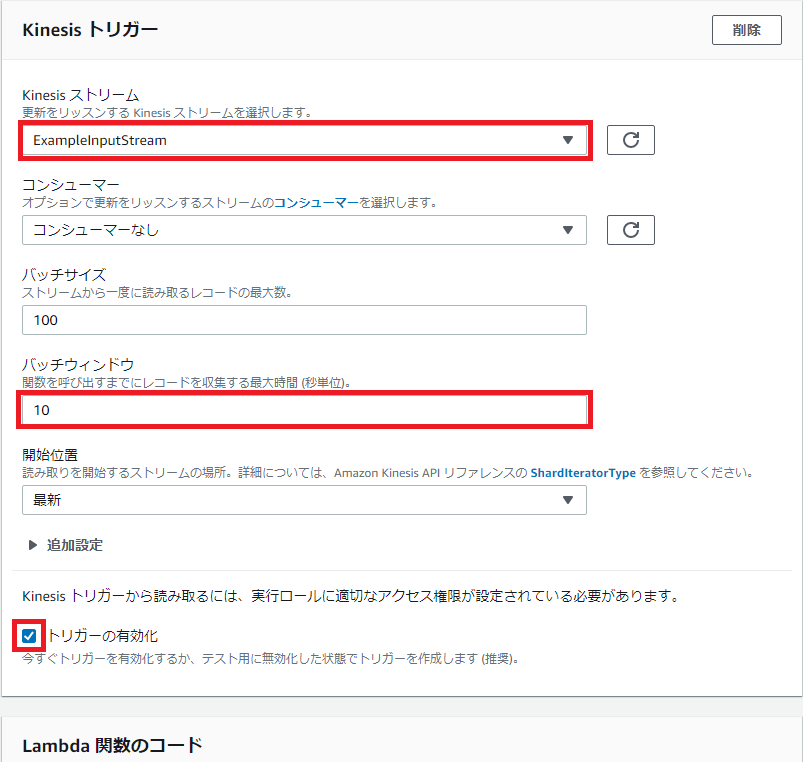
(※) 関数呼び出しまで10秒間待機し、その間受信したストリーミングデータを蓄積します。今回はサンプル値として10秒を設定しましたが、実際の運用では単位時間あたりのデータ量を基に、バッチサイズと併せて待機時間を調整してください。
Lambda関数はそのまま使用するので何もせず「関数の作成」ボタンを押下します。
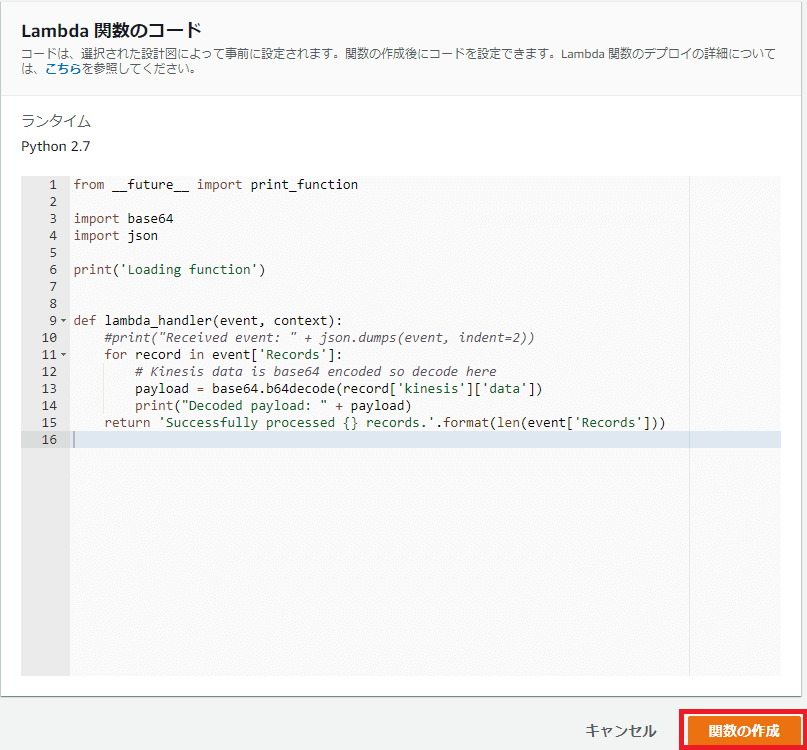
コード解説
(※)Kinesisから受信した際のイベントの形式は「AWS Lambda開発者ガイド」の「AWS Lambda を Amazon Kinesis に使用する![]() 」を参照してください。
」を参照してください。
Kinesis Data Streamsの「ExampleInputStream」にストリームデータを送信し、Lamndaで受信されているかCloudWatchのログから確認します。
ストリームデータを生成し、Kinesis Data Streamsの「ExampleInputStream」に送信するスクリプトを作成します。
今回は、「Amazon Kinesis Data Streams開発者ガイド」の「チュートリアル:Kinesis Data Analytics for Java Applicationsを使用した株式データのリアルタイム分析![]() 」 で紹介されている「株式取引のストリームをシミュレートするスクリプト」を流用改造します。
」 で紹介されている「株式取引のストリームをシミュレートするスクリプト」を流用改造します。
スクリプトの作成と実行環境としてAmazon EC2を使用します。
Amazon EC2のデフォルト環境ではpipがインストールされていないので、インストールを実施します。
$ sudo apt-get install python-pip
全体環境に影響を及ぼさないようにするため、Pythonの仮想環境機能:virtualenvを使ってストリーミングデータ送信スクリプトの作成環境を構築します。
virtualenv / virtualenvwrapperをインストールします。
$ sudo apt install virtualenv virtualenvwrapper
仮想環境v-envを作成します。
$ virtualenv v-env
作成した仮想環境を起動します。
$. v-env/bin/activate
仮想環境に外部ライブラリboto3(python用AWS SDK)をインストールします。
(v-env) ubuntu:$ pip install boto3
viエディタでinputStream.pyを作成します。
(v-env) ubuntu:$ vi inputStream.py
「Amazon Kinesis Data Streams開発者ガイド」の「ステップ3:アプリケーションの作成![]() 」> 「入力ストリームへのサンプルコードの書き込み」のstock.pyのコードをコピー&ペーストします。
」> 「入力ストリームへのサンプルコードの書き込み」のstock.pyのコードをコピー&ペーストします。
このスクリプトは無限ループで動作しているため、スクリプトを強制停止するまでストリーミングデータの送信を繰り返します。停止するまでに大量のデータが送られてしまうので、コマンドライン引数でループ回数を指定するように改造します。
改造後のスクリプトコードを以下に示します。
import json
import boto3
import sys
import random
import datetime
from time import sleep
kinesis = boto3.client('kinesis') //Kinesisのclientオブジェクトを取得(※1)
def getReferrer(): //ストリーミングデータ生成関数
data = {}
now = datetime.datetime.now() //タイムスタンプを生成
str_now = now.isoformat()
data['EVENT_TIME'] = str_now //タイムスタンプをdata['EVENT_TIME']に設定
data['TICKER'] = random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']) //株式銘柄リスト[Apple, Amazon, Microsoft, Intel,TBV]からランダムに選択しdata['TICKER']に設定
price = random.random() * 100 //株価をランダムに算出
data['PRICE'] = round(price, 2) //株価をdata['PRICE']に設定
return data
args = sys.argv
lcount = int(args[1]) //第一引数を抽出しLoopカウンタに設定
i = 0
while i < lcount: //Loopカウンタの値だけLoop
data = json.dumps(getReferrer()) //ストリーミングデータ生成関数Call
print(data)
curkey = str(random.randint(1,4)) //キー値に1~4(※2)の数値をランダムに生成した値を設定
print("curkey : " + str(curkey))
response = kinesis.put_record( //Kinesisへレコードを書き込む(※1)
StreamName="ExampleInputStream", //Kinesisストリーム名にExampleInputStreamを設定
Data=data, //ストリーミングデータ部分に生成したdataを設定
PartitionKey=curkey) //パーティションキーに生成したキー値を設定
print(response)
i += 1
sleep(0.1) //100ms sleep
(※1)Kinesisの操作にAWS SDK for Python(boto3)を使用します。
ストリームへの送信にはkinesis.Clientクラスのput_record()メソッドを使用します。
kinesis.Clientクラスの仕様はboto3ドキュメントのKinesis![]() を参照してください。
を参照してください。
put_record()メソッドの詳細はboto3ドキュメントのput_record(**kwargs)![]() を参照してください。
を参照してください。
(※2) パーティションキーは、どのシャードに割り当てるかを決める際に利用されます。データが均等にシャードに分散されるようパーティションキーはシャード数より十分に大きな値を用意する必要があります。
今回はLambdaの動作確認に焦点を合わせているため、シャードへのデータの均等分散を考慮せずシャード数と同じ1~4の範囲で作成しています
スクリプトを実行します。
下の実行例では50個分のストリーミングデータを生成&送信します。
(v-env) ubuntu:$ python inputStream.py 50
実行すると、コンソール上に以下のような実行ログが50個分表示されます。
{"EVENT_TIME": "2020-03-11T06:27:36.443754", "TICKER": "AAPL", "PRICE": 54.96}
curkey : 1
{'ShardId': 'shardId-000000000003', 'SequenceNumber': '49605012620624120727955236536457485721211877177572720690', 'ResponseMetadata': {'RequestId': 'f09ca895-170a-ac42-a67e-2f8da4a6a09b', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'f09ca895-170a-ac42-a67e-2f8da4a6a09b', 'x-amz-id-2': '134vUL1EbOw93L0CFT+l/n2umHnbMGtxeSP9Ih9kz43KXj5DqHtI8YWHnjF2NbMcvyV+qZC5iklgZOgkszoocR3qXq0zE+wBd4cEA9lm3qI=', 'date': 'Wed, 11 Mar 2020 06:27:36 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '110'}, 'RetryAttempts': 0}}
1行目:生成したストリーミングデータ(イベント発生日時, 銘柄, 株価)
2行目:生成したパーティションキー値
3行目:kinesis.put_recordの応答。以下のような書式で返信されます。
{
'ShardId': 'string', //利用したシャードのID
'SequenceNumber': 'string', //ストリームのシーケンス番号
'ResponseMetadata':{ } //レスポンスのメタデータHTTPStatusCodeが200であることを確認する
'RetryAttempts': int //失敗時の再試行回数
}
※50個分全てのログの紹介は省略しますが、'ShardId'の値をチェックするとshardId-000000000002とshardId-000000000003の2種類だけが記録されていました。このことから今回の場合シャード数は、「2」が適切な値となります。
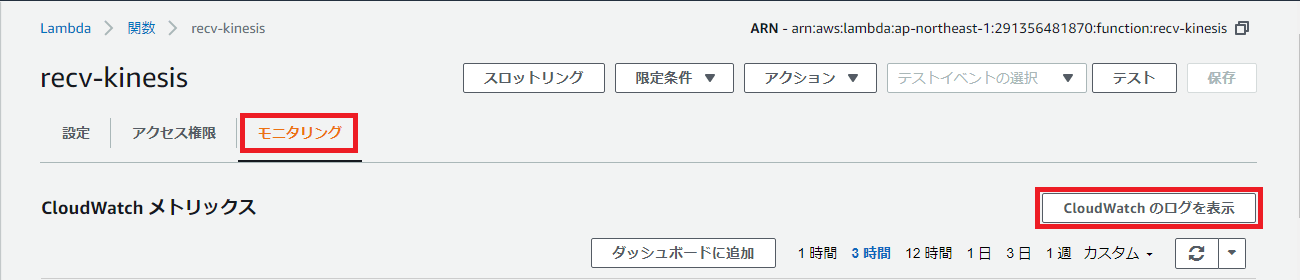
CloudWatchでLambdaの実行ログを確認します。
Lambda関数「recv-kinesis」のコンソール画面から「モニタリング」タブを開き、「CloudWatchのログを表示」ボタンを押下してください。
CloudWatch のLambda関数「recv-kinesis」のロググループにジャンプします。
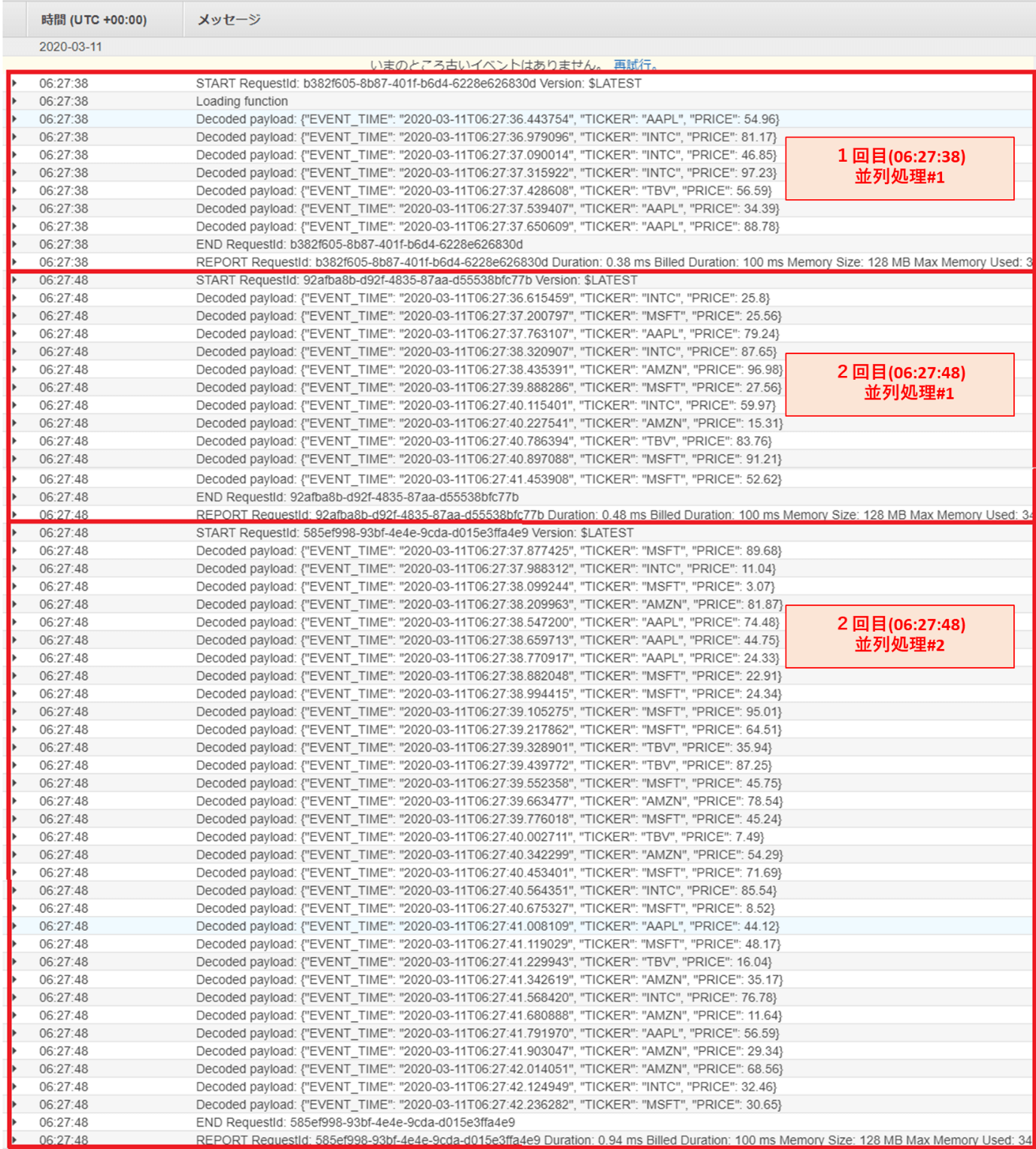
ログストリームのリストに表示されているファイルをクリックすると、Lambda関数のログ詳細を見ることが出来ます。

ログのタイムスタンプより、10秒毎にまとめてストリーミングデータが処理されていることが分かります(START~ENDの範囲がLambdaの1回分の処理内容になります)
(※)LambdaはKinesis Data Streamsで実行されたシャード数だけ同時実行します。
4.2.1.「スクリプト実行」の実行ログ実行ログより、実行されたシャード数は2でしたので、Lambdaの同時実行数は2になります。
(※)1回目の処理で同時実行数が1となっていますが、これはLambdaの初回起動が遅く、1回目の処理で片方のLambdaの起動が完了しなかったことに因るためです
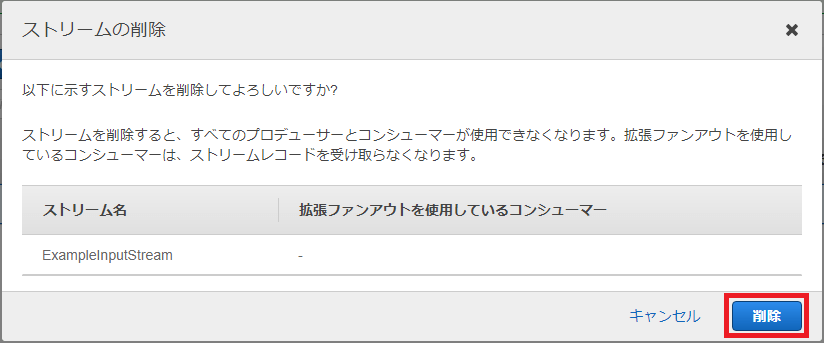
Kinesisストリームはそのまま放置しておくと課金されてしまうので、使用後は速やかに削除します。
Amazon Kinesisサービスのコンソール画面からData Streamsの一覧を表示し、「ExampleInputStream」のチェックボックスにチェックを入れます。
メニューバーの「アクション」ボタンを押下し、ドロップダウンリストから「削除」を選択します。

ストリーム削除の最終確認画面が表示されるので「削除」ボタンを押下します。
ストリームの削除が実行され、リストから「ExampleInputStream」が除外されます。
今回はAmazon kinesis Data Streamsのストリーミングデータを処理するLambdaについて解説しました。Amazon kinesis Data StreamsとLambda間のデータのやりとりを中心に解説したため、今回のLambdaのサンプルコードは受信した株式取引のストリーミングデータをログに記録するだけの簡単な処理でしたが、実際のユースケースでは分析アプリなどへ転送して、過去5分間に購入した最も人気の銘柄を抽出したり、大量の売り注文を検出するなどの処理を実施します。
また、本文の冒頭で紹介した、入出力ライブラリを使用してAmazon kinesis Data Streamsのリアルタイム分析を実施する方法がありますが、本コラムのLambdaの解説という主旨から外れるため割愛しました。これらの詳細については「チュートリアル: Kinesis Data Analytics for Java Applications を使用した株式データのリアルタイム分析![]() 」を参照してください。
」を参照してください。
ネットワークからクラウドの導入・運用までトータルでサポート!





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


