
Amazon Connectで構築してみた (第1回:電話転送)
最近、導入費用、初期構築や設定変更のお手軽さ、ハードウェア保守期限が無いなどの観点から、クラウド型コンタクトセンターサービスとなります、Amazon Connectに興味を持たれているお客さまが増えてきています。数ヶ月前まで、Amazon Connectを触ったことがなかった私が電話転送機能をご紹介できればと思います。
![]()


AWS Lambdaの一般的な利用方法の中から1つを取り上げ、環境構築からLambda関数の作成および動作確認までの一連の作業手順を詳細に解説しています。
今回はAmazon Simple Queue Service (以下Amazon SQS)を使用した非同期処理を実施する Lambdaの作成手順をAmazon SQSによる非同期処理の構築手順と併せて解説します。

Amazon SQS(Simple Queue Service)はAWSが提供するメッセージキューシステムです。主に送信側と受信側で非同期に処理したいケースで利用されます。
ユースケースを以下に示します。
SQSには「標準キュー」と「FIFOキュー」の2種類があります
高スループットですが、送信時の順番が保証されない、稀にメッセージが重複して配信されるなどの特徴があります。これは、メッセージを複数のキューに分散して配信し、更に各メッセージの複製を複数のキューに冗長的に保存しているために発生します。
スループットは標準キューに劣りますが、引き換えに受信したメッセージの順番を厳密に保持します。メッセージの重複配信も発生しません。
標準キューでのポーリング方法で、対象のキューが空の際の対処方法が異なります。
ロングポーリング:一定時間メッセージが届くまで待機
ショートポーリング:待機せず終了。
高スループットを必要とする場合はショートポーリングを、そうでない場合はロングポーリングの利用が推奨されています。具体的な特徴を以下に示します。
複数のキューの中から特定のキューをランダムに選択し、そのキューのメッセージを取得します。空のキューを選択した場合、そのキューからのメッセージ取得数は0になります。
複数のキューから一部をランダムに選択するため、全てのメッセージを取得することができず、またメッセージを重複して取得する場合があります。
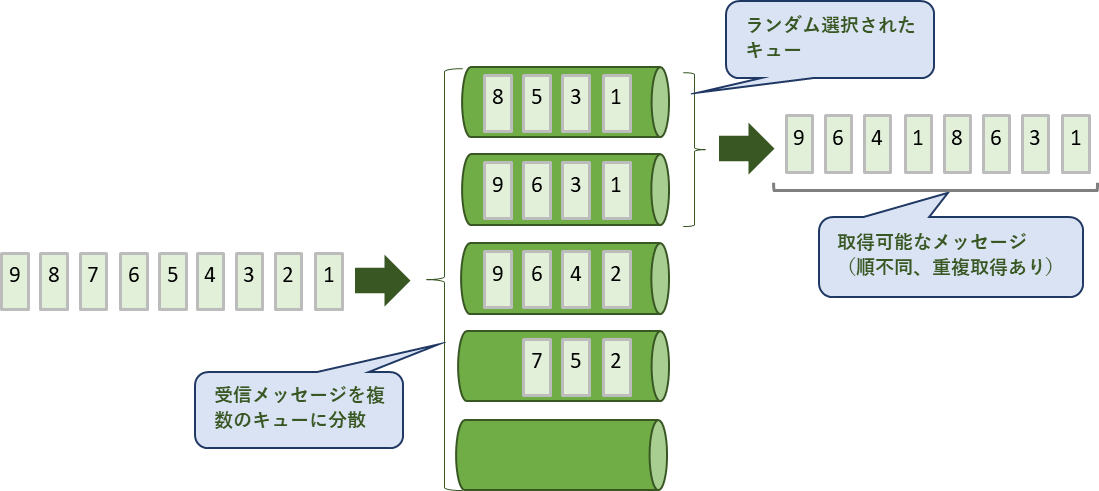
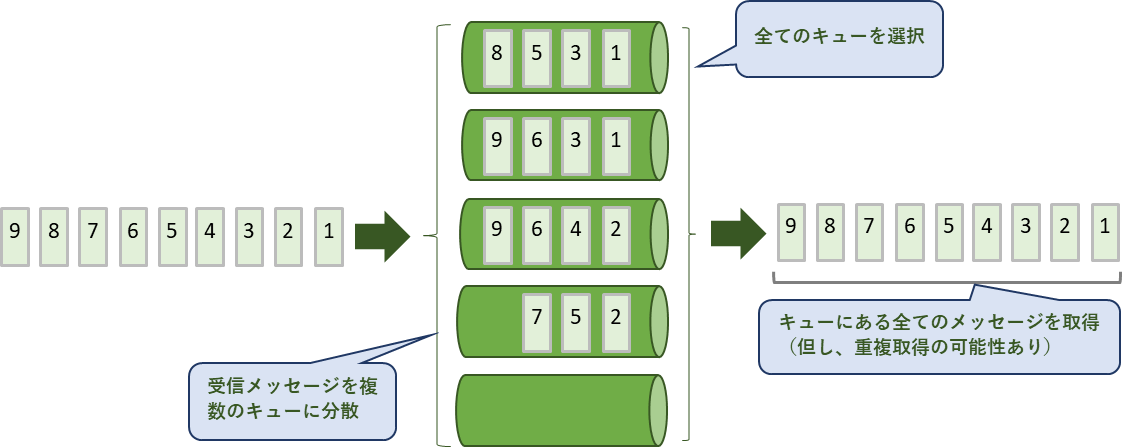
キューの接続がタイムアウトしない限り全てのキューを選択するため、キューにある全てのメッセージを取得することができます。但し、取得したメッセージが重複している場合があります。
AWS Lambdaではロングポーリングを実施しています。
動作の全体像を以下に示します。
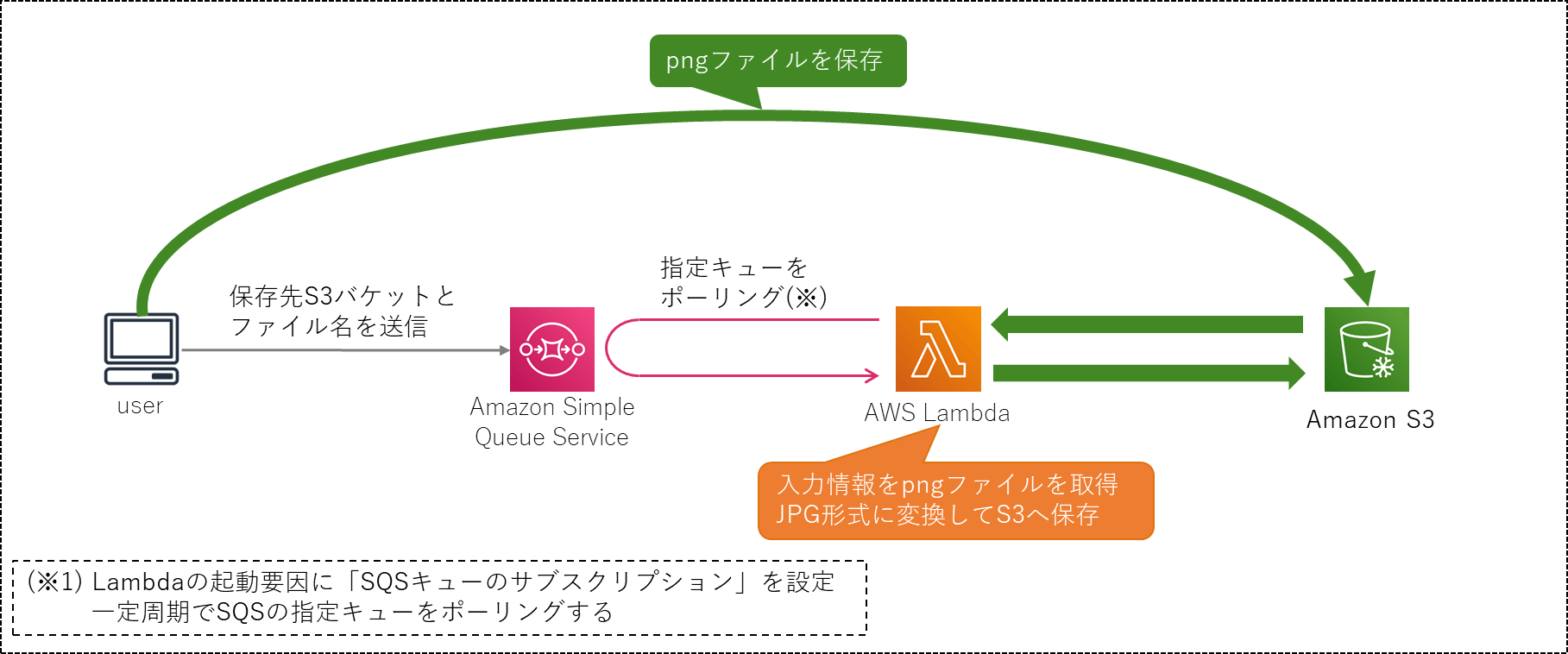
動作概要
画像をS3にアップロードする処理と、画像ファイルをPNG形式からJPG形式に変換する処理をAmazon SQSを使用して非同期に実行します。
以下に処理手順を示します。
SQSにキューを新規作成します。
Amazon SQS マネージメントコンソールを開きます。既存のキューが無い状態では、以下の画面が表示されます。
「今すぐ始める」ボタンを押下してください。

以下を設定し、画面右下の「キューのクイック作成」ボタンを押下します。
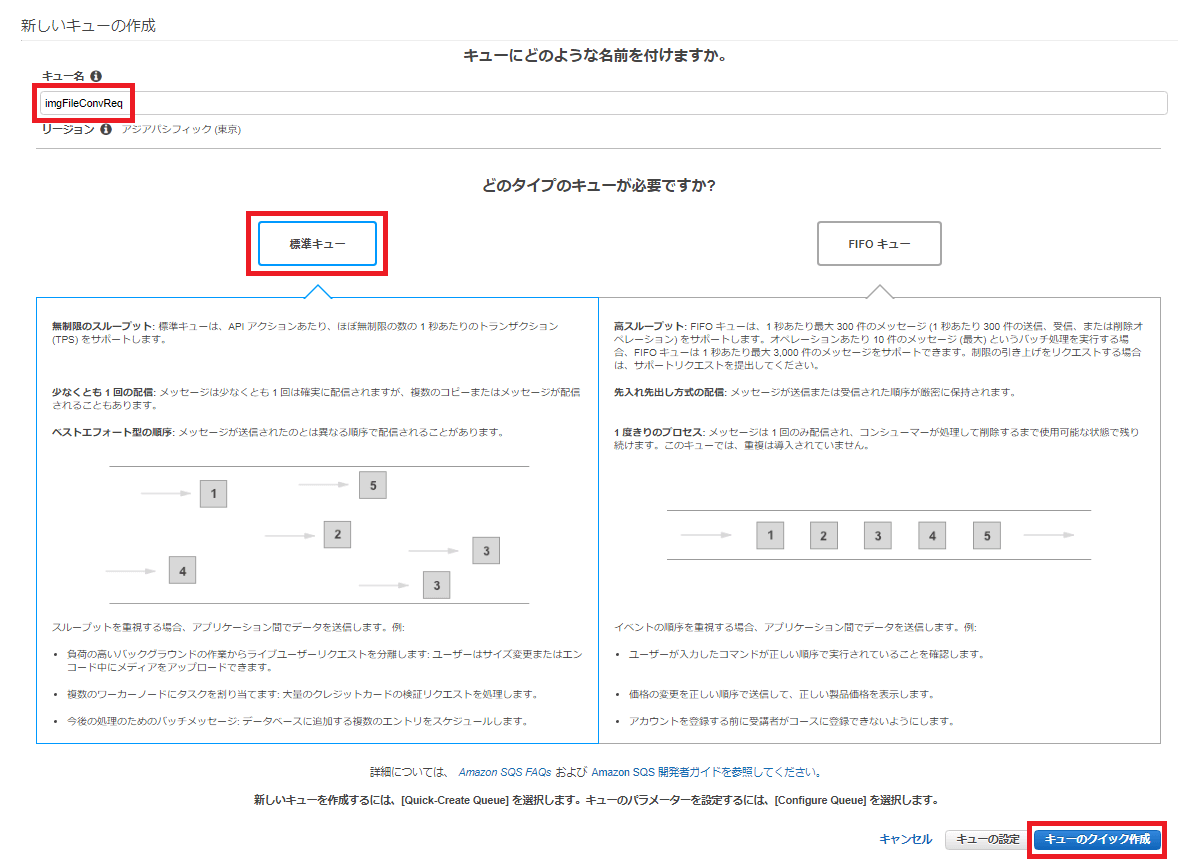
FIFOキューを選択する場合は、キュー名には拡張子「.fifo」を付与してください。
Amazon SQS マネージメントコンソールにキューの一覧が表示され、作成したキューが表示されます。
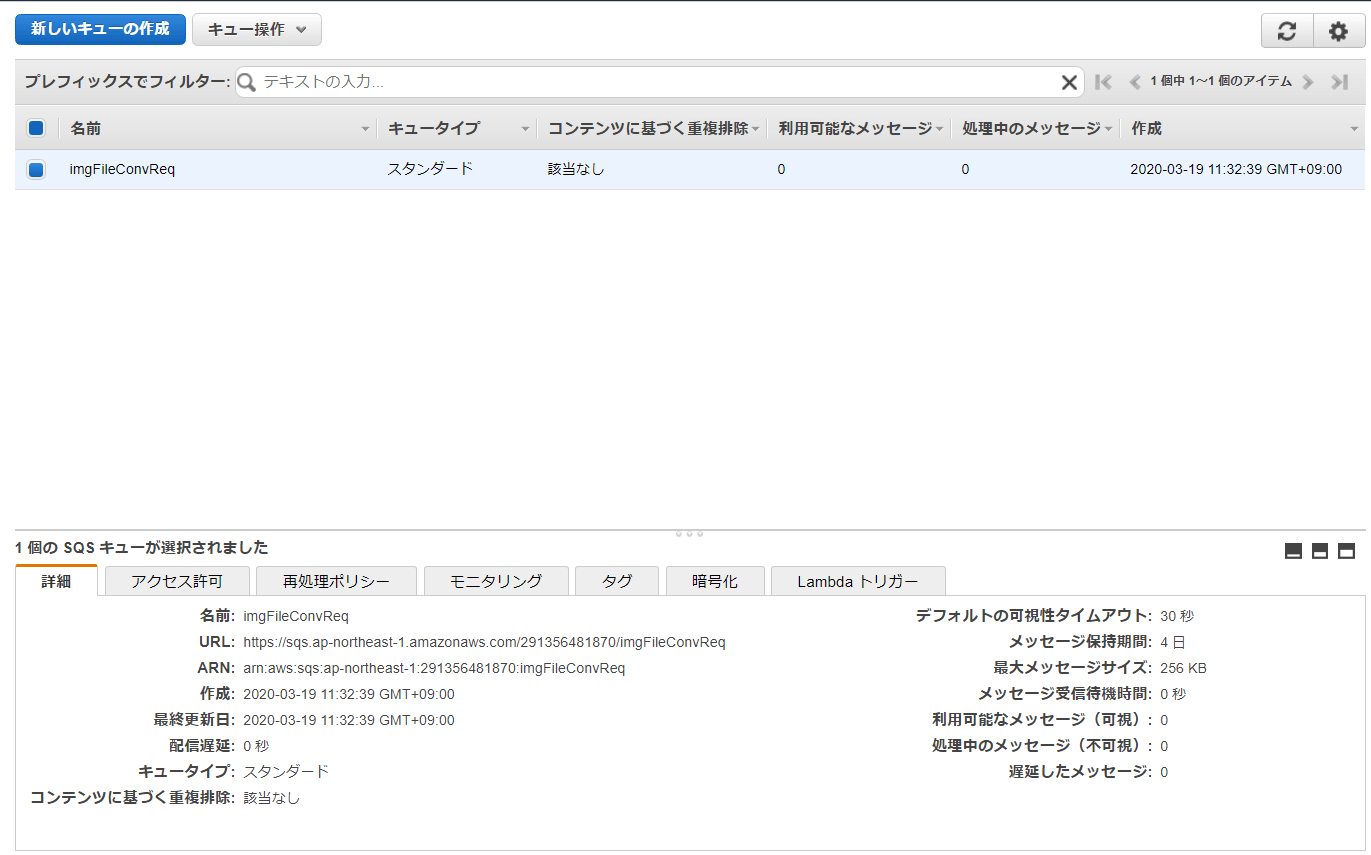
Amazon S3に画像ファイル保存用バケットを作成します。
Amazon S3のコンソールを開きます。
「+バケットを作成する」ボタンを押下します。
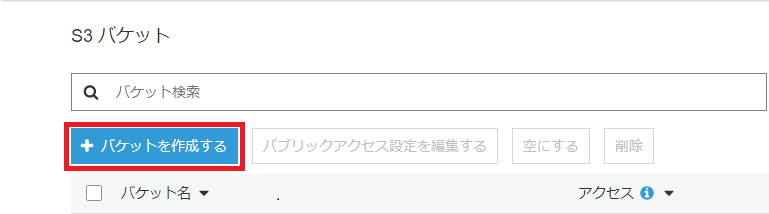
「バケットを作成」の入力画面でバケット名を入力します。今回は「lambda-test-2020」と入力しました。
他はデフォルトのままとし、画面右下の「バケットを作成」ボタンを押下します。
SQSキューをポーリングするLambdaをPython3.8で作成します。
Lambdaの作成方法には以下の2通りがあります。
①AWS Lambdaコンソールで直接コードを作成
②外部ライブラリとLambda関数をパッケージ化してアップロード
今回は画像加工を行うので画像処理用の外部ライブラリを使用します。そのため②の方法による作成となります。
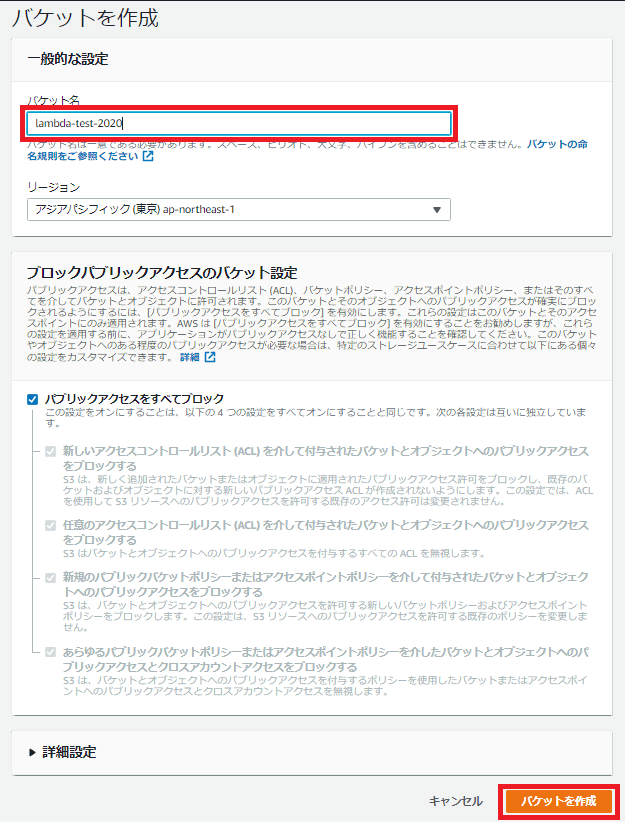
Lambdaコンソールを開き「関数の作成」ボタンを押下します。
「関数の作成」画面が開くので以下を設定します。
「実行ロールの選択または作成」の設定で以下を設定します。
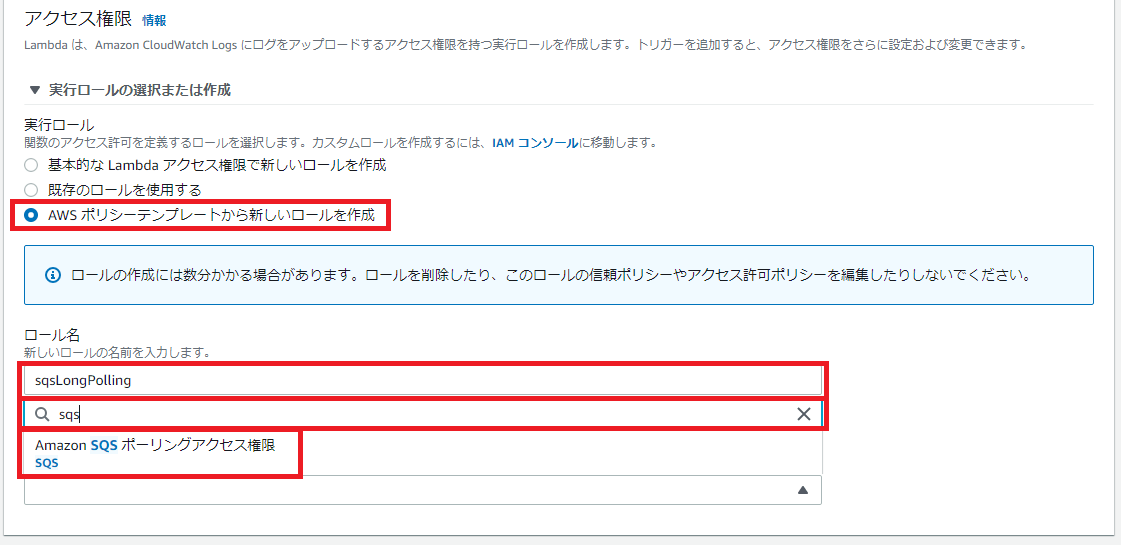
最後に画面右下の「関数の作成」ボタンを押下します。
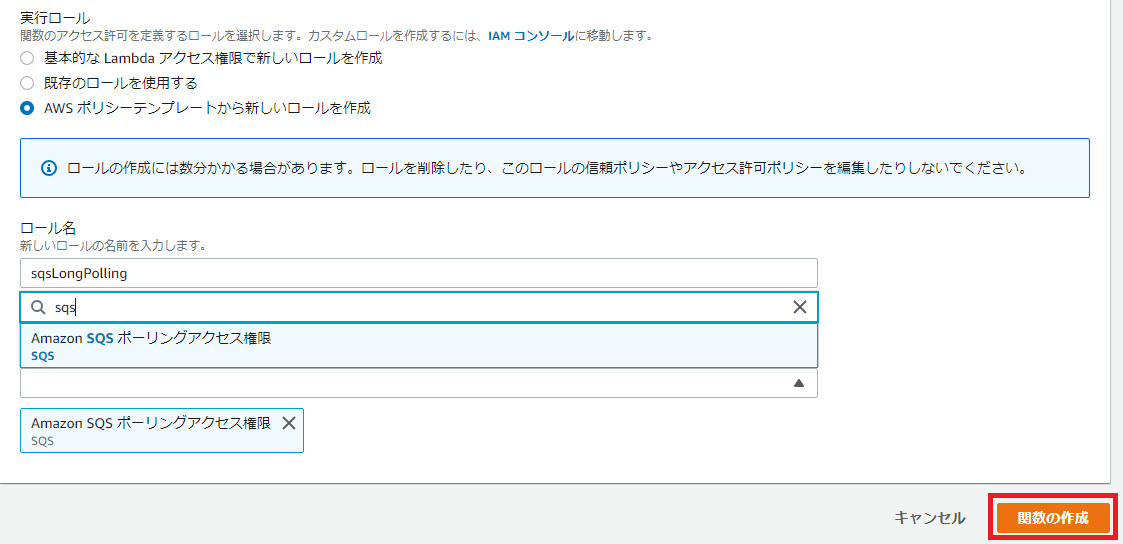
関数が作成されると「recvSQSMessage」の設定画面が開きます。
作成した実行ロールにS3のアクセス権を追加します。
「recvSQSMessage」の設定画面を「実行ロール」の設定項目までスクロールします。
「IAMコンソールでsqsLongPollingロールを表示します」をクリックします。
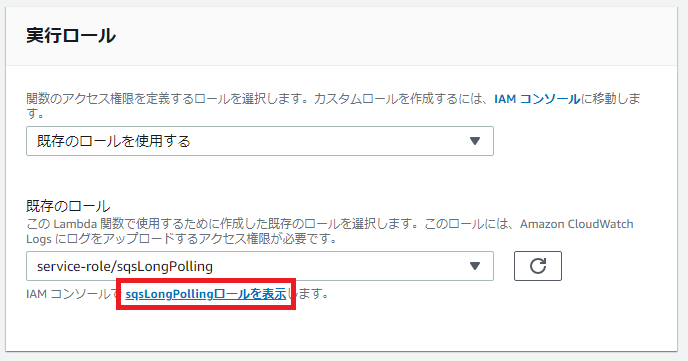
「sqsLongPolling」の概要画面が開きます。
「+インラインポリシーの追加」ボタンを押下します。
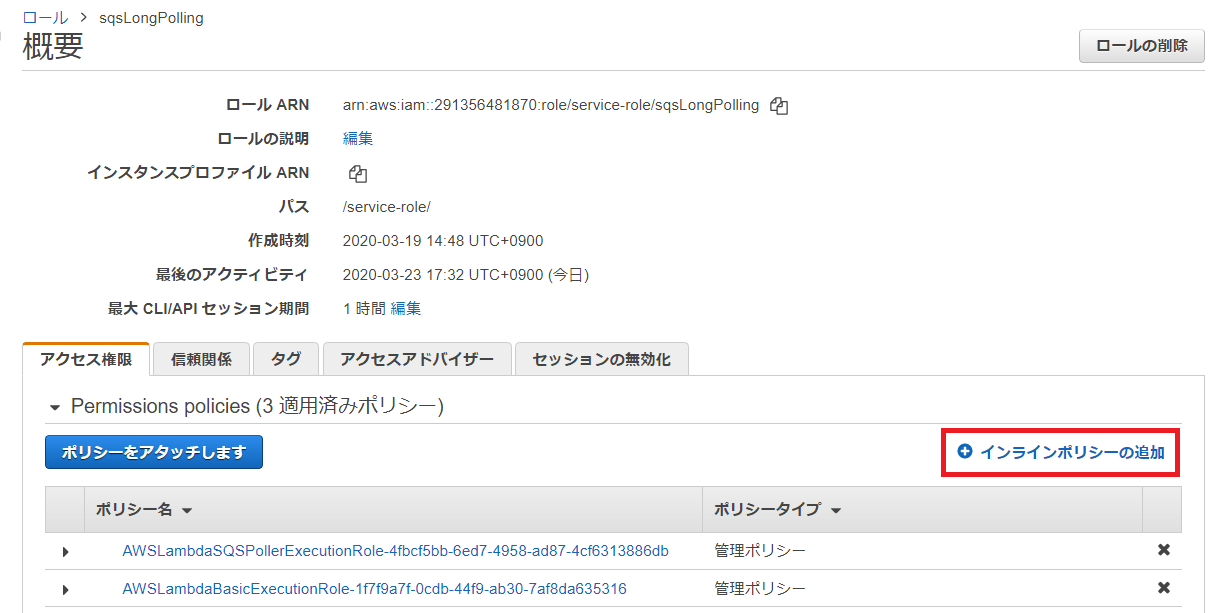
「ポリシーの作成」画面が開きます。
「サービスの選択」の設定項目で「サービス」の「▸」をクリックし、折り畳まれている画面を表示します。
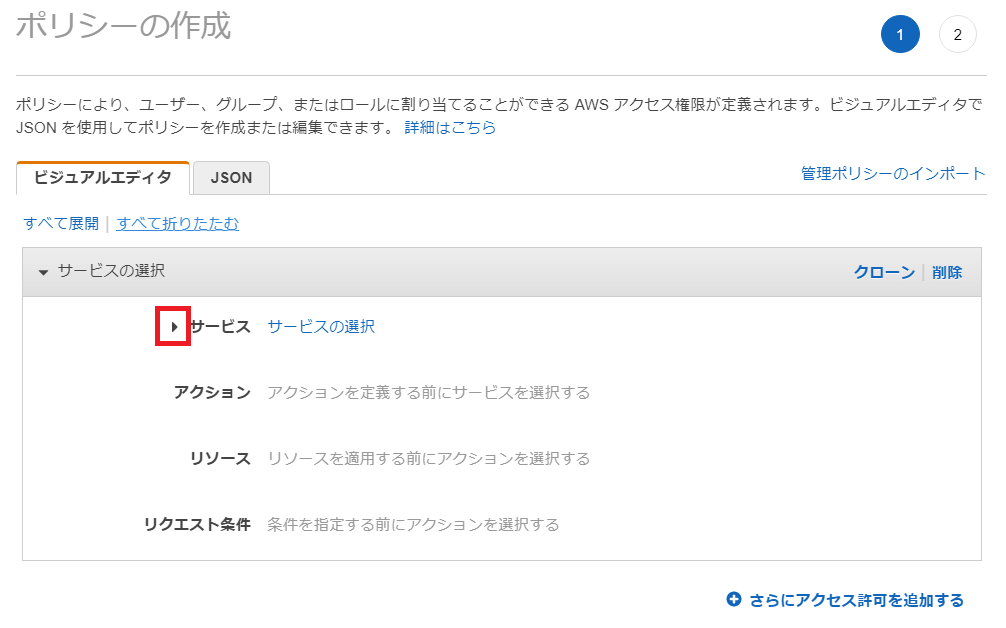
キーワード入力欄に「s3」と入力します。表示された選択候補「S3」を選択します。
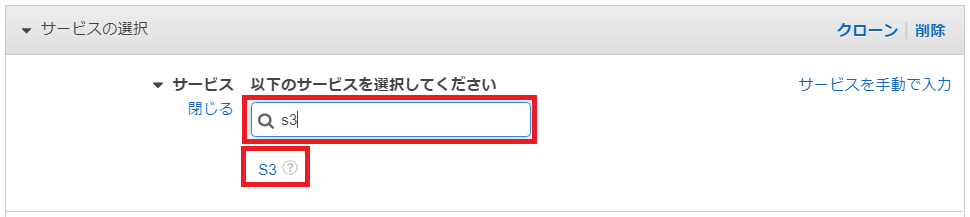
「アクション」の設定項目「アクセスレベル」が表示されます。
「リスト」、「読み込み」、「書き込み」の「▸」をクリックし、折り畳まれている画面を表示します。
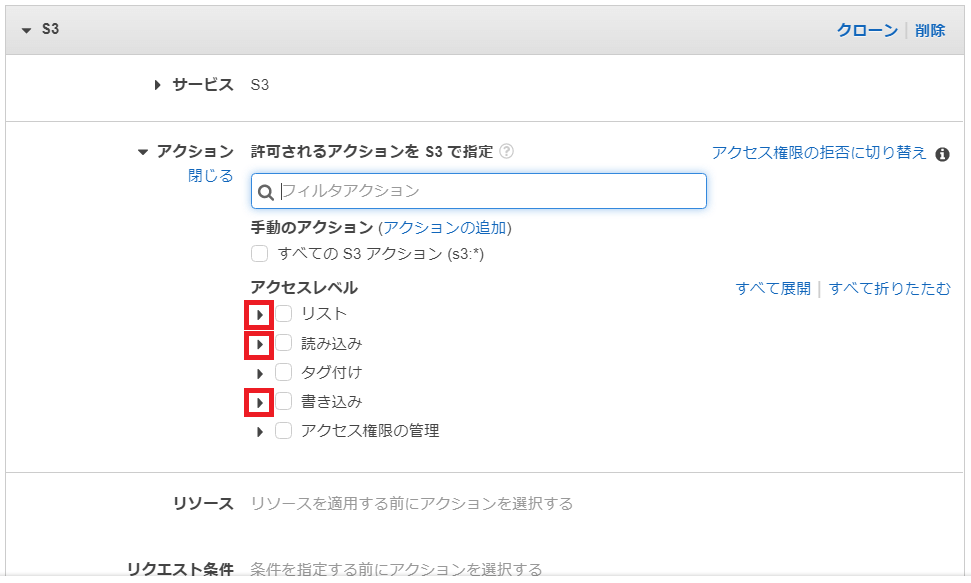
「リスト」の一覧から「ListBucket(バケットの操作権限)」を選択します。
「読み込み」の一覧から「GetObject (オブジェクト取得権限)」を選択します。
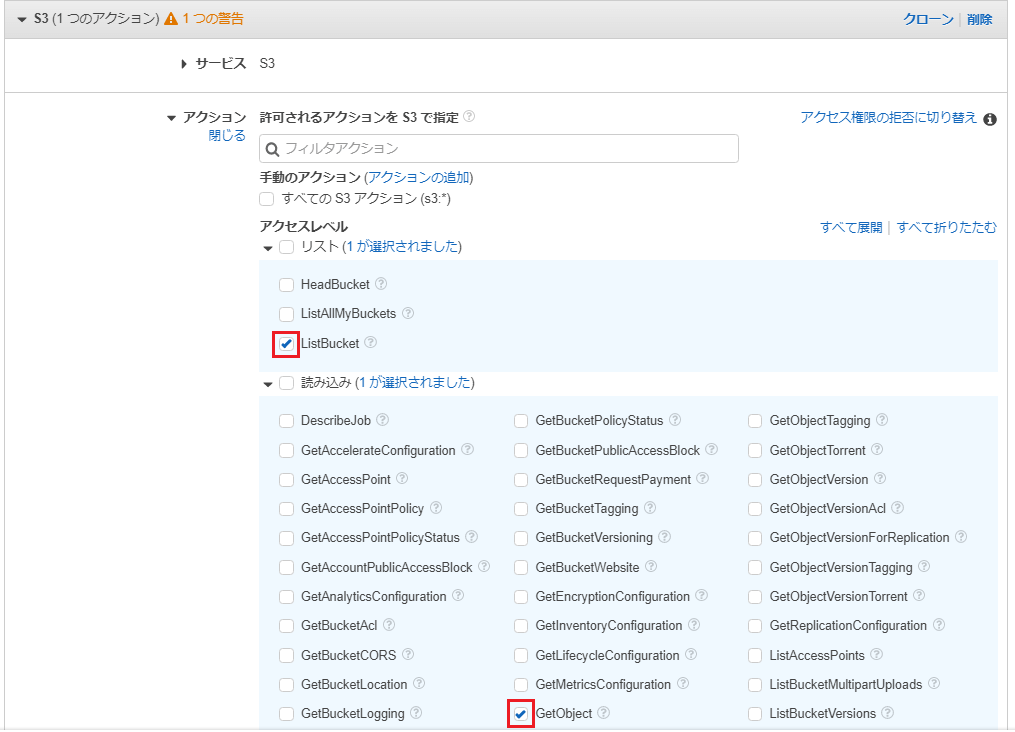
「書き込み」の一覧から「PutObject(オブジェクト追加権限)」を選択します。
「リソース」の「bucketリソースARNを選択します。ListBucketアクション objectリソースARNを選択します。PutObjectおよび、さらに1つのアクション」を選択します。
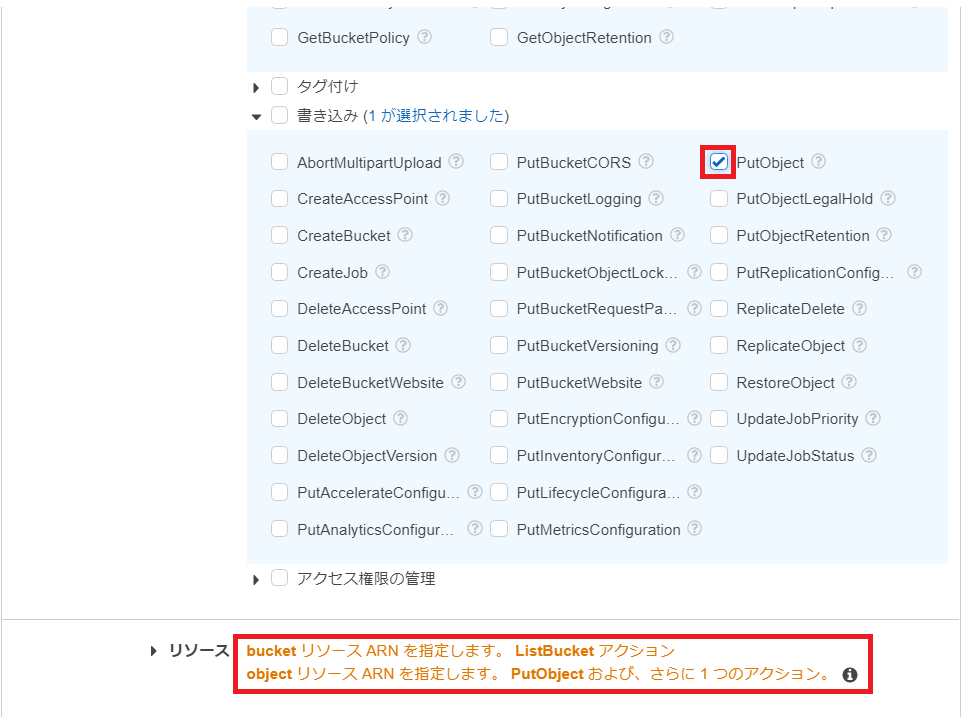
「リソース」の選択一覧が表示されるので「すべてのリソース」を選択します。
画面右下の「ポリシーの確認」ボタンを押下します。
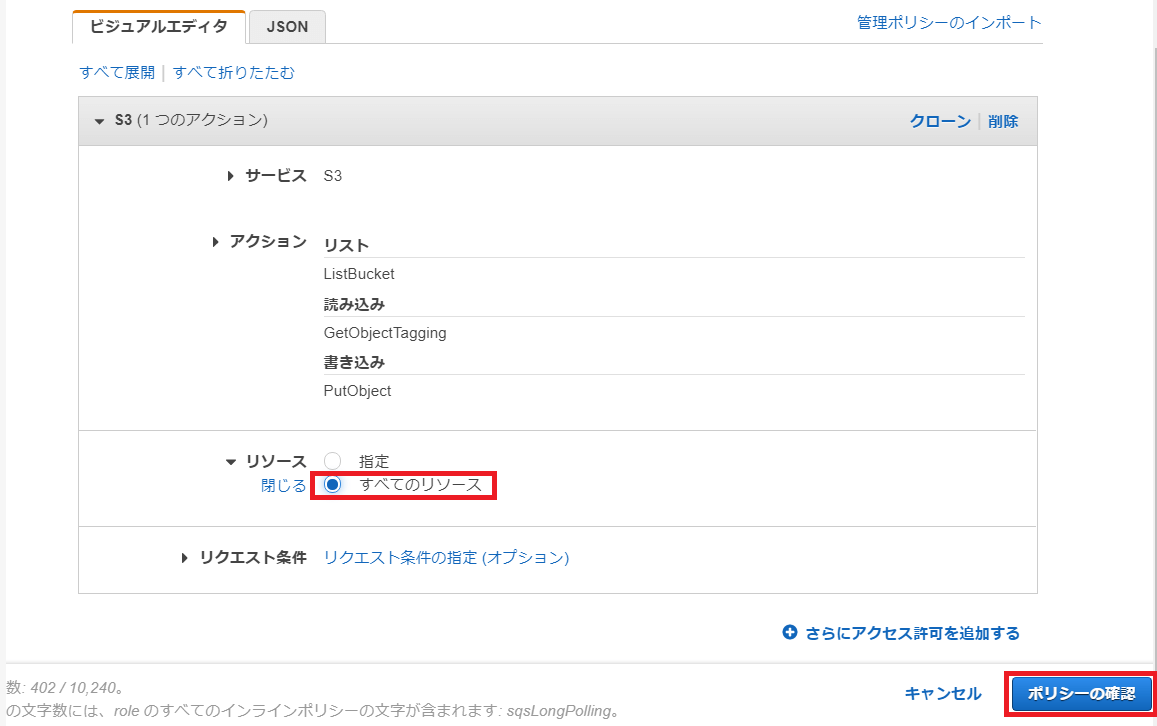
「ポリシーの確認」画面が開きます。
「名前」欄に「s3ReadWriteAccess」と入力します。
画面右下の「ポリシーの作成」ボタンを押下します。
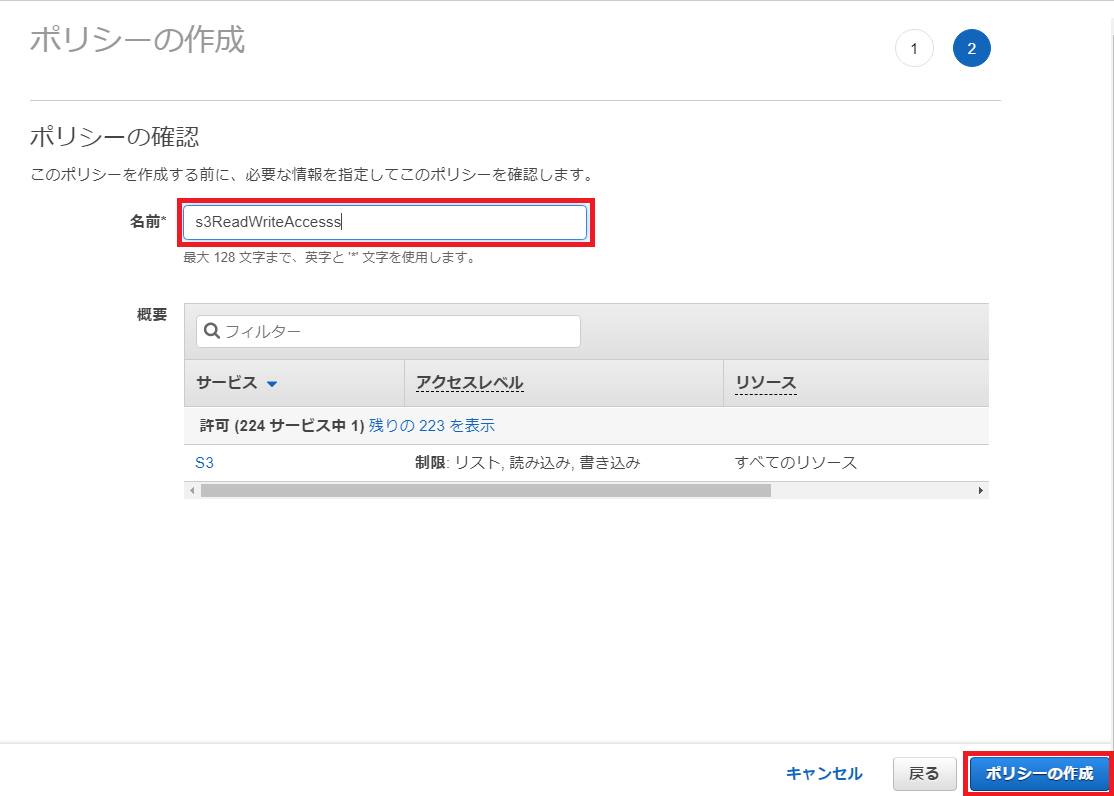
「Permission policies」に作成した「s3ReadWriteAccess」が表示されます。
AWS Lambdaはlinux環境で動作するため、linux環境でのLambdaパッケージ作成が推奨されています。今回はOSがubuntuの EC2環境で作成します。
Amazon EC2のデフォルト環境ではpip, zip, Python3.8がインストールされておらずこれらのインストールが必要になります。
pipのインストール
$ sudo apt-get install Python-pip
zipのインストール
$ sudo apt install zip
Python3.8のインストール
$ sudo apt install Python3.8
Pythonの仮想環境機能:virtualenvを使って画像ファイル加工用Lambdaパッケージ作成環境を構築します。
virtualenv / virtualenvwrapperをインストールします。
$ sudo apt install virtualenv virtualenvwrapper
Python3.8の仮想環境の作成
EC2環境ではデフォルトでPython2.7の仮想環境が作成されるため、Python3.8の仮想環境を作成する場合は、-pオプションを使ってPython3.8を指定します。
$ virtualenv -p /usr/bin/Python3.8 v-env
作成した仮想環境を起動します。
$. v-env/bin/activate
仮想環境に外部ライブラリPillow, boto3をインストールします。
(v-env) ubuntu: $ pip install Pillow boto3
Pillow:Pythonの画像処理ライブラリ
boto3:Python用AWS SDK(PythonでAWSを操作するためのライブラリ)
(Lambdaコンソールで直接コードを作成する場合は標準装備されていますが、パッケージアップロードの場合はそのリンクから外れるため、外部ライブラリとしてインストールする必要があります)
Pillowとboto3モジュールをパッケージ化したlambda_function.zipを作成します。
(v-env) ubuntu: $ cd $VIRTUAL_ENV/lib/Python3.8/site-packages
(v-env) ubuntu: $ zip -r9 ${OLDPWD}/lambda_function.zip .
元のフォルダに移動します。
(v-env) ubuntu: $ cd ${OLDPWD}
viエディタでlambda_function.pyを作成します。
(v-env) ubuntu: $ vi lambda_function.py
lambda_function.pyのコードを以下に示します。
import json
import boto3
import uuid
from PIL import Image
s3_client = boto3.client('s3')
def lambda_handler(event, context): //Lambdaから最初に呼びされるハンドラ関数
for record in event['Records']: //引数;event内の'Records'を配列要素分Loop
curBody = json.loads(record['body']) //'body'内のハッシュ要素をjson形式に変更(※)
bucket = curBody['bucket'] //'body'から'bucket'の値を取得
key = curBody['key'] //'body'から'key'の値を取得
tmpkey = key.replace('/', '') //'key'の文字列から'/'を削除
cnvkey = tmpkey.replace('.png', '.jpg') //一時保存key拡張子を'.png'から'.jpg'に変更
splitkey = key.split('/') //key'の文字列を'/'部分で分割。フォルダ、ファイルに分離
newkey = key.replace('.png', '.jpg') //保存用keyの拡張子を'.png'から'.jpg'に変更
newkey = newkey.replace(splitkey[0], 'jpgfiles') //保存用keyのフォルダ名を'jpgfiles'に変更
download_path = '/tmp/{}{}'.format(uuid.uuid4(), tmpkey) //Lambdaの一時保存パスを作成
upload_path = '/tmp/resized-{}'.format(cnvkey) //画像加工後の一時保存パスを作成
s3_client.download_file(bucket, key, download_path) //S3からPNG形式の画像ファイルをダウンロード
print("s3 bucket: " + bucket + ", source key: " + key + ", download_path : " + download_path)
Image.open(download_path).convert('RGB').save(upload_path) //画像ファイルをPNG形式からJPG形式に変換
s3_client.upload_file(upload_path, bucket, newkey) //JPGファイルをS3にアップロード
print("s3 bucket: " + bucket + ", upload key: " + newkey + ", upload_path : " + upload_path)
引数:eventよりs3に保存した画像ファイルのbucketとkeyを抽出
取得したbucketから画像ファイル:key(pngfiles/ファイル名.png)をダウンロード
ダウンロードした画像ファイルをPNGからJPGに変換
s3の指定bucket へ作成したJPGファイルをnewkey(jpegfiles/ファイル名.jpg)でアップロード
Amazon SQSからのメッセージは"Records"の各メンバーリスト内の"body"プロパティに設定されています。その際、"body"のオブジェクトは辞書型ではなく文字列として扱われています。Lambda関数で使用する際はjson.loads()で辞書型へ変換してください。
Amazon SQSからのメッセージイベントの詳細内容はAWS Lambda開発者ガイドの「AWS Lambda を Amazon SQS に使用する![]() 」を参照してください。
」を参照してください。
lambda_function.zipに作成したLambdaファイルを追加します。
(v-env) ubuntu $ zip -g lambda_function.zip lambda_function.py
adding: lambda_function.py (deflated 60%)
これでパッケージ作成作業は完了です。以下のコマンドで仮想環境から抜けてください。
(v-env) ubuntu: $ deactivate
仮想環境から抜けた後はデフォルトフォルダ上にlambda_function.zipファイルが作成されていることを確認してください。
最後に、作成したlambda_function.zipをSCPコマンドなどでLambdaコンソールを操作している作業用PCへ転送します。
作成したLambdaパッケージが10MBを超えているのでS3からのアップロードを実施します。
今回はlambda_function.zip の一時置き場所として、3.「S3バケットの作成」で作成した「lambda-test-2020」バケット利用します。
S3コンソールを開き、バケット一覧から「lambda-test-2020」を選択します。
「lambda-test-2020」の設定画面から「アップロード」ボタンを押下します。
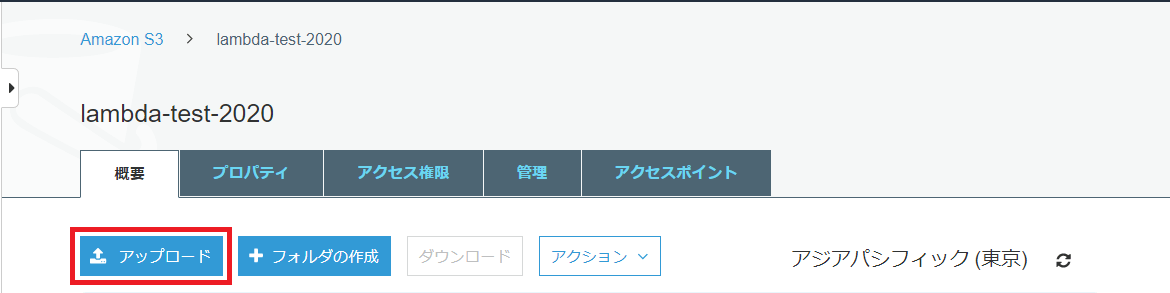
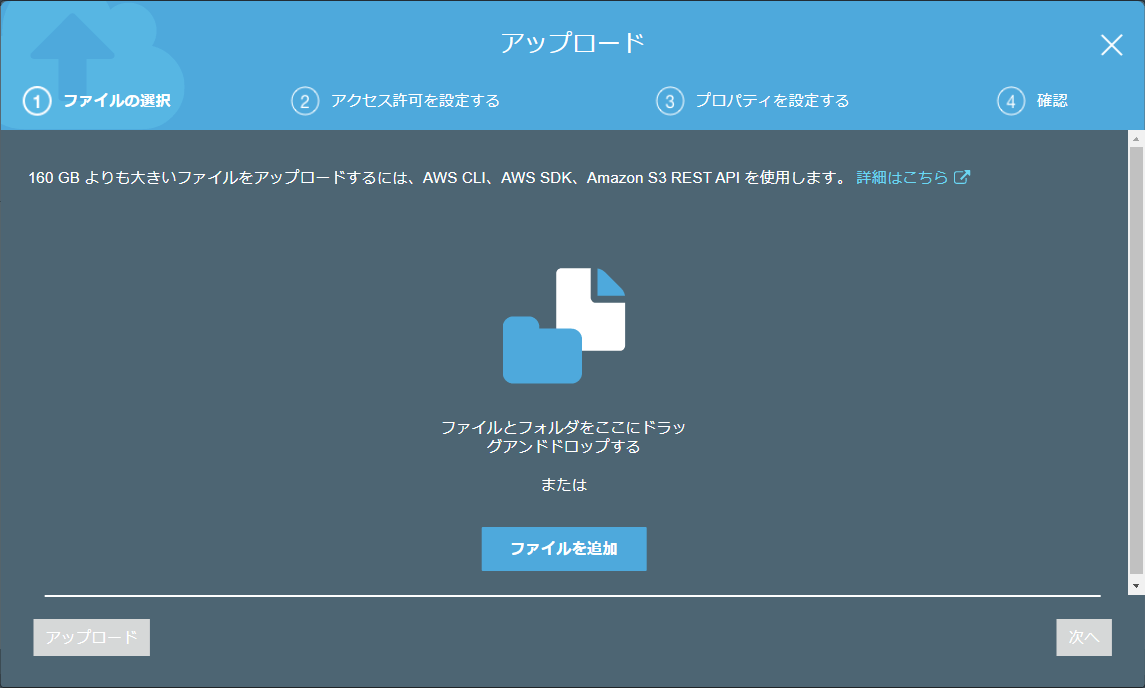
アップロード画面が開くのでlambda_function.zipをドラッグ&ドロップします。
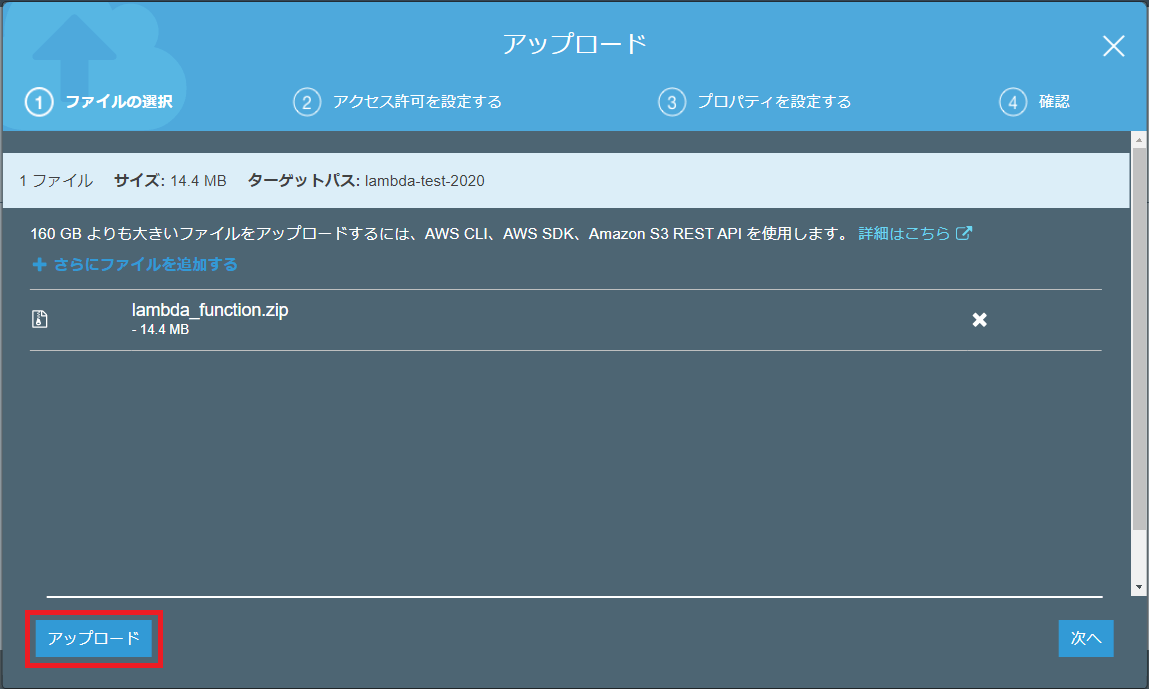
アップロード画面にlambda_function.zipが表示されたら画面左下の「アップロード」ボタンを押下します。
S3の「lambda-test-2020」バケットのファイル一覧にアップロードしたlambda_function.zipが表示されます。
lambda_function.zipを選択して「概要」情報を表示します。
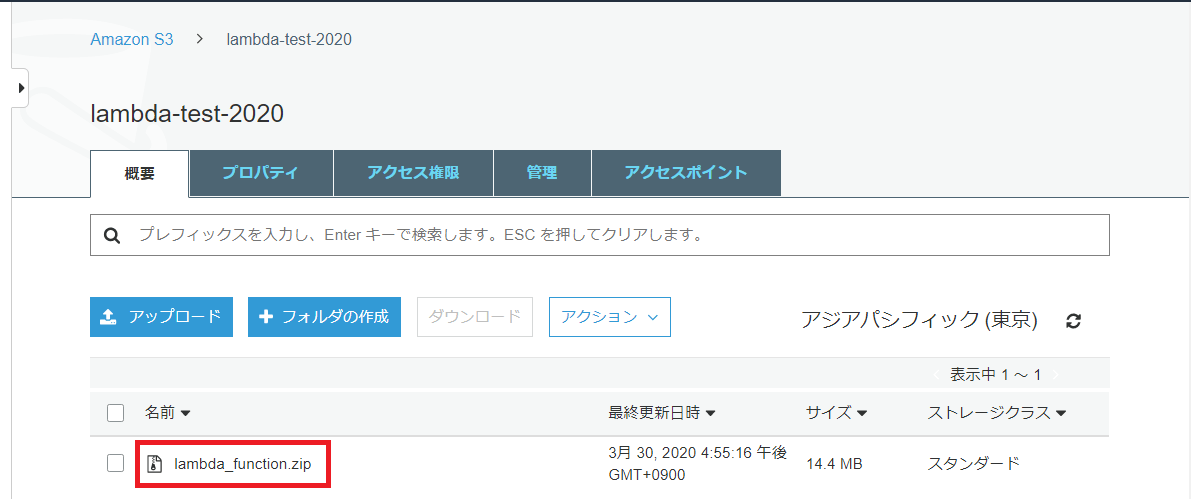
オブジェクトURLをコピーします。
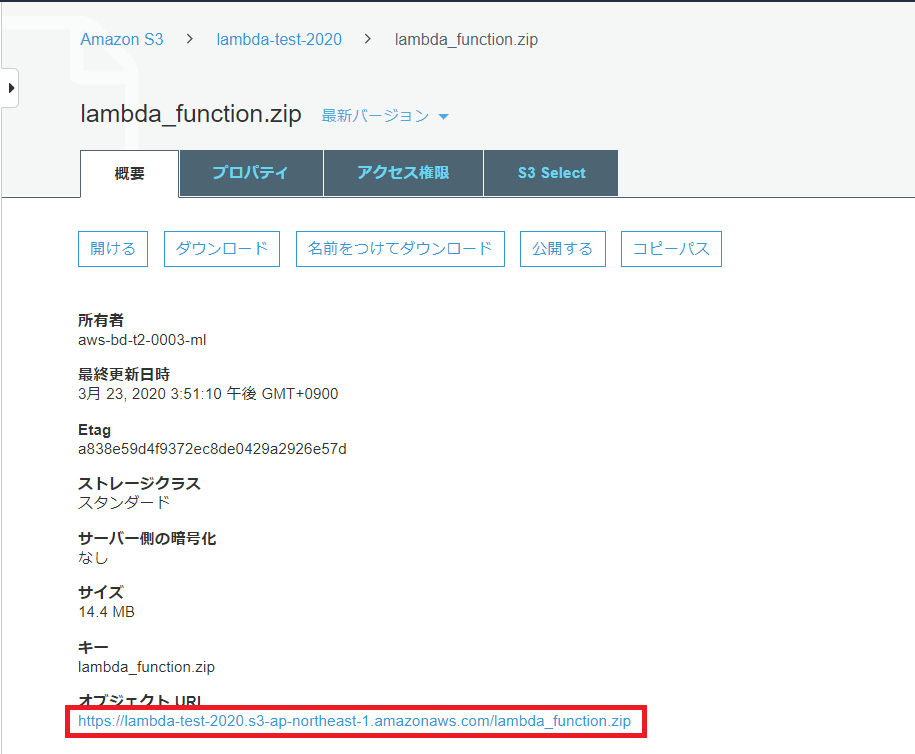
Lambda関数「recvSQSMessage」のメニュー画面を「関数コード」の設定欄まで画面をスクロールします。
以下を設定し画面右上の「保存」ボタンを押下します。
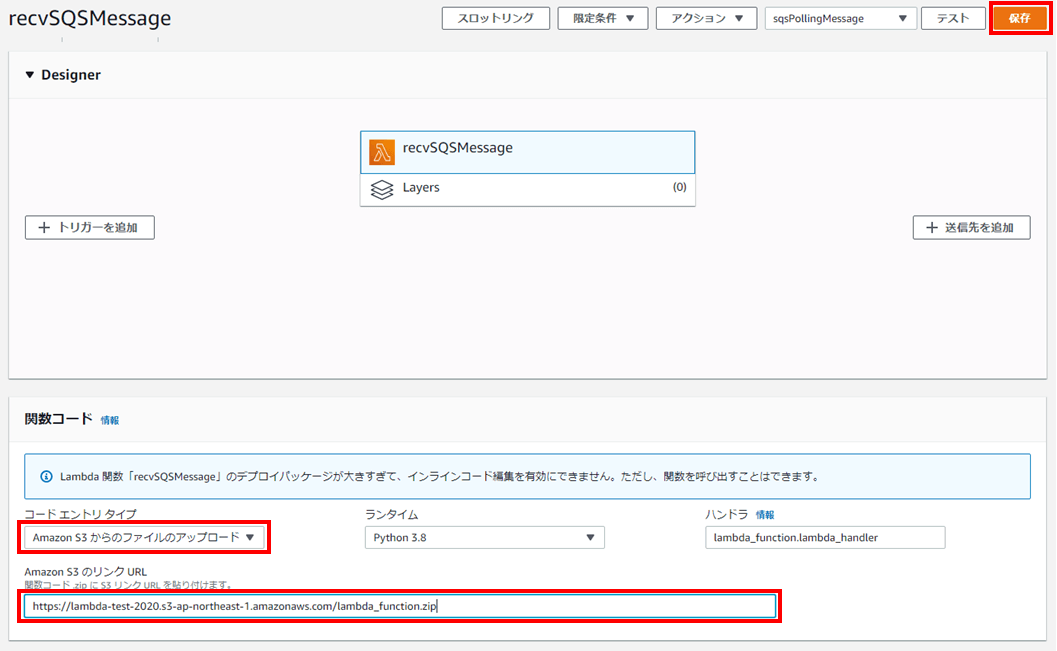
Amazon SQSのマネージメントコンソールよりキュー一覧から「imgFileConvReq」のチェックボックスにチェックを入れます。
「キュー操作」のドロップダウンリストから「Lambda関数のトリガーの設定」を選択します。
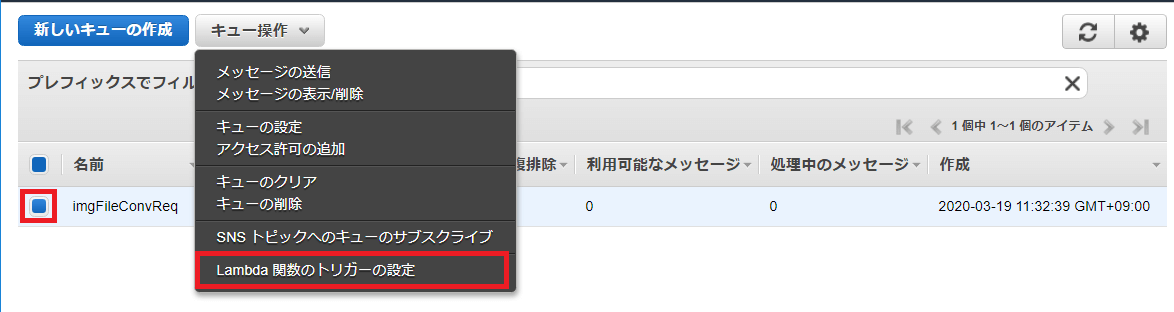
「Lambda関数の選択」のドロップダウンリストから「recvSQSMessage」を選択します。
「保存」ボタンを押下します。
以下のような確認メッセージが表示されるので「OK」を押下します。
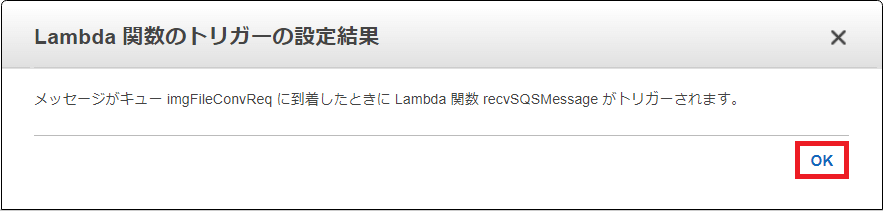
この設定によりLambda関数「recvSQSMessage」に自動的にSQSのトリガーが設定されます。
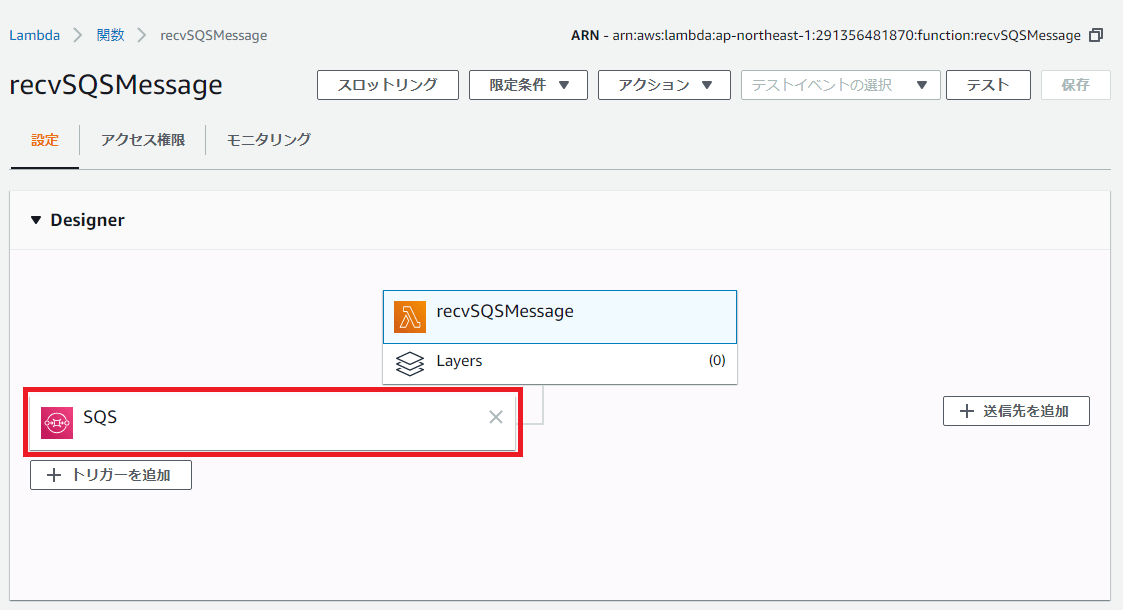
PNG形式の画像ファイルをS3へアップロードし、S3のアップロード先の情報をAmazon SQSへ送信するプログラムをPythonで作成します。
今回はAmazon EC2環境で実施します。
EC2からAWSの各サービスにアクセスするにはAWSから発行されたアクセスキー(アクセスキーID、シークレットアクセスキー)の設定が必要になります。
以下の手順で認証情報の設定を実施してください。
下記のURLにアクセスします。
https://console.aws.amazon.com/iam/home?#/security_credentials![]()
以下の手順でアクセスキーIDとシークレットアクセスキーを取得します。
「アクセスキーの作成」ボタンを押下します。
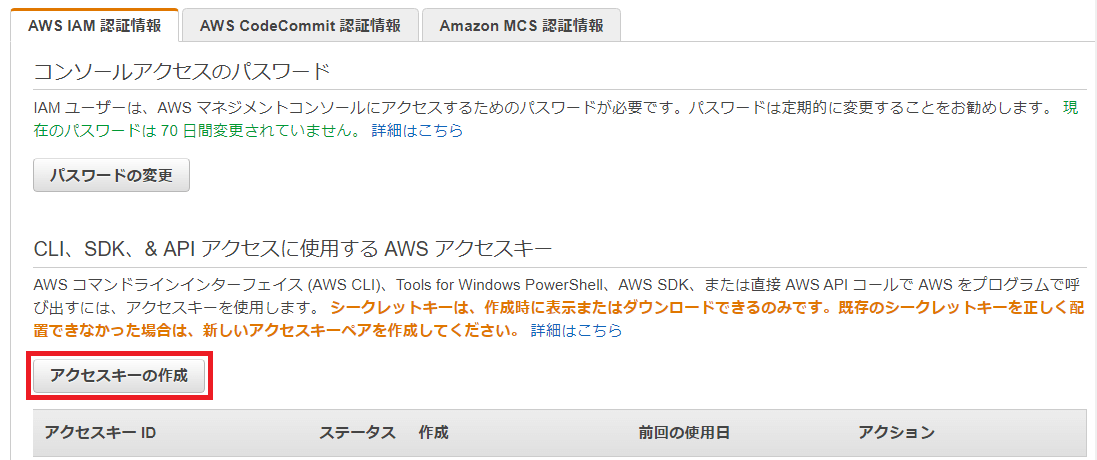
「アクセスキーの作成」画面が表示されるのでアクセスキーIDの右端にあるコピーボタンを押下して発行されたアクセスキーIDをコピーします。
同様にしてシークレットアクセスキーもコピーします。
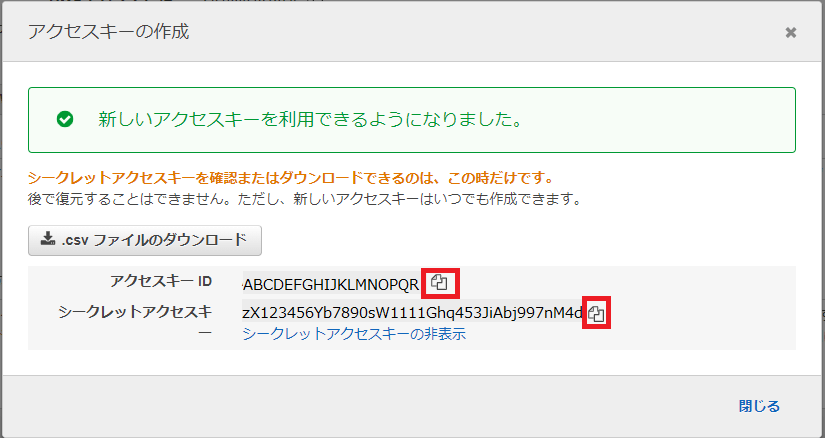
上記画像の表示の通り、シークレットアクセスキーは作成時以外で確認することができません。「.csvファイルのダウンロード」ボタンを押下して、アクセスキーを記録したcsvファイルをローカル環境に保存するようにしてください。
取得したアクセスキーIDとシークレットアクセスキーを使って認証情報の設定を実施します。
仮想環境を起動します。
$. v-env/bin/activate
仮想環境にAWS CLI(Command Line Interface)をインストールします。
(v-env) ubuntu: $ pip install awscli
aws configureコマンドを実行してAWS CLIの設定ファイルを生成します。
(v-env) ubuntu: $ aws configure
対話形式でアクセスキーIDの入力を要求されます。アクセスキーIDを入力します。
AWS Access Key ID [None]: XXXXXXXXXXXXXXXXXXXX
AWS Secret Access Keyの入力を要求されます。シークレットアクセスキーを入力します。
AWS Secret Access Key [None]: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
デフォルトリージョンの入力を要求されます。AWSサービスを利用しているリージョンを入力します。東京の場合は「ap-northeast-1」となります。
Default region name [None]: ap-northeast-1
コマンド出力結果の表示形式を指定します。json、table、textの3種類から選択します。ここでは「json」を選択します。
Default output format [None]: json
送信プログラムを作成します。
viなどのエディタを使用してimageDataUp.pyを作成します。
$(v-env) ubuntu: $ vi imageDataUp.py
imageDataUp.pyのコードを以下に示します。
import boto3
import os
import sys
import json
bucketName = 'lambda-test-2020' //S3のバケット名'lambda-test-2020'を設定
folderName = 'pngfiles' //フォルダ名に'pngfiles'を設定
queueName = 'imgFileConvReq' //SQSのキュー名に'imgFileConvReq'を設定
s3 = boto3.resource('s3') //S3の高レベルAPIの利用
bucket = s3.Bucket(bucketName) //S3.Bucketオブジェクトで'lambda-test-2020'をアクセス
sqs = boto3.resource('sqs') //SQSの高レベルAPIの利用
args = sys.argv //コマンドライン引数を抽出
filePath = args[1] //引数から画像ファイルパスを取得
splitPath = filePath.split('/') //ファイルパスを’/’で分離。フォルダとファイル名に分割
key = folderName + '/' + splitPath[1] //S3のフォルダ名にファイル名を連結し、S3のkeyを作成
print(key) //作成したkeyの確認
bucket.upload_file(filePath, key) //S3のbucketのkeyへfilePathで示されたファイルをupload
try:
queue = sqs.get_queue_by_name(QueueName=queueName) //SQSキューオブジェクトを取得
except:
print("SQS_No_Exeist.") //SQSキュー獲得失敗時のエラーメッセージ
message = json.dumps({'bucket': bucketName, 'key': key}) //バケット名とkeyをメンバーにJSON形式でメッセージを作成
response = queue.send_message(MessageBody=message) //SQSのキューにメッセージを送信
print(response) //実行応答を表示
PNG形式の画像ファイルを用意し、EC2に転送します。
作成したimageDataUp.pyを実行します。引数として画像ファイルのパスを設定します。
(※)下記は画像ファイルsampleImage.pngをimageDataUp.pyと同一フォルダ上に置いた場合の実行例になります。
$(v-env) ubuntu: $ Python imageDataUp.py ./sampleImage.png
imageDataUp.pyを実行すると、以下のようなSQSのqueue.send_message()の実行応答が表示されます。ここで‘HTTPStatusCode’が200であることを確認してください。
{'MD5OfMessageBody': 'c3ad2ff13e031c5010f8859fbe386921', 'MessageId': '4968fa87-ed39-47f0-a72e-1b43e6f50155', 'ResponseMetadata': {'RequestId': '0210f833-9b18-5a1a-abfc-aec7604261be', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '0210f833-9b18-5a1a-abfc-aec7604261be', 'date': 'Wed, 25 Mar 2020 06:24:26 GMT', 'content-type': 'text/xml', 'content-length': '378'}, 'RetryAttempts': 0}}
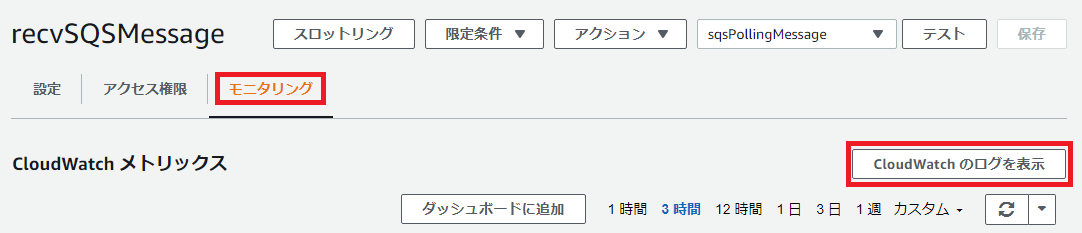
CloudWatchのLambdaのログを確認します。
Lambda関数「recvSQSMessage」のコンソール画面から「モニタリング」タブを開き、「CloudWatchのログを表示」ボタンを押下してください。
自動的にCloudWatch のLambda関数「recvSQSMessage」のロググループにジャンプします。
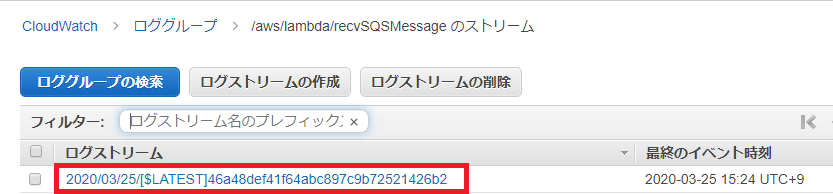
ログストリームのリストに表示されているファイルをクリックすると、Lambda関数のログ詳細を見ることが出来ます。
ログには以下の情報を記録しています。

実際にJPGファイルがS3に保存されているか確認します。
S3コンソールを開き、バケット一覧から「lambda-test-2020」を選択します。
正常実行されると、以下のように「jpgfiles」と「pngfile」フォルダが作成されます。
先ず「pngfile」フォルダを選択し、フォルダを開きます。
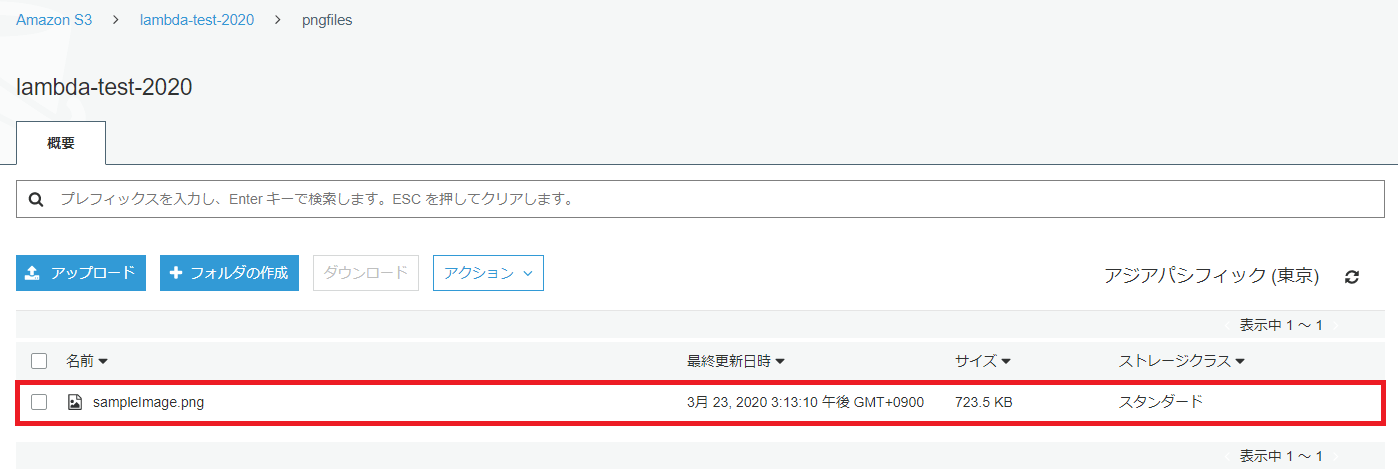
「pngfile」フォルダ上に「sampleImage.png」ファイルが保存されていることを確認します。画像ファイルをダウンロードしてアップロードしたファイルか確認してください。
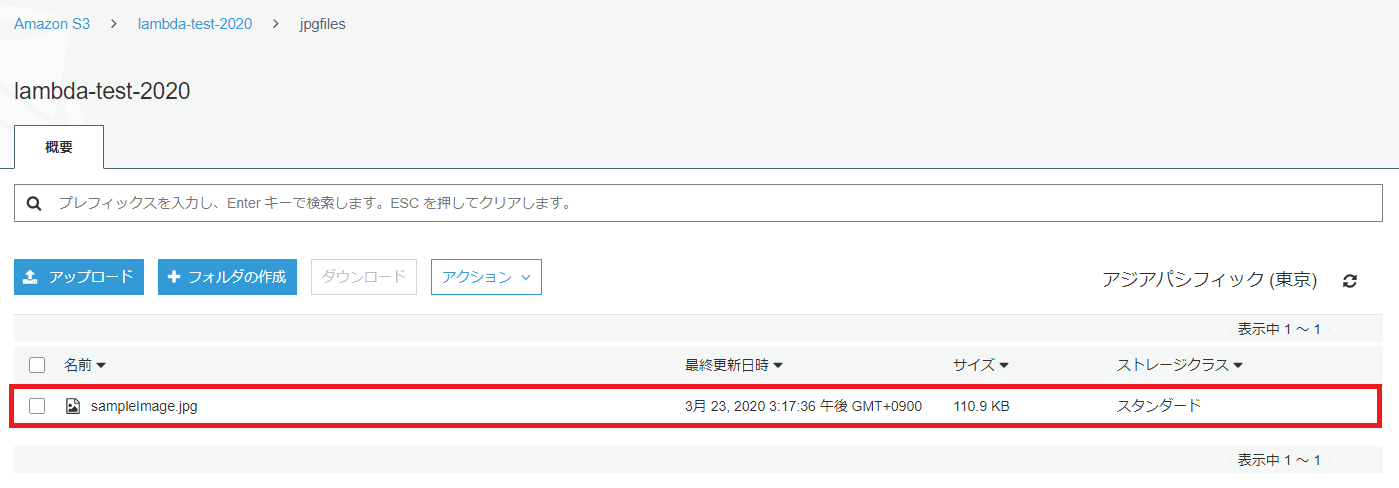
次に「jpgfile」フォルダを選択し、フォルダを開きます。
「jpgfile」フォルダ上に「sampleImage.jpg」ファイルが保存されていることを確認します。画像ファイルをダウンロードしてjpg変換された画像ファイルか確認してください。
動作確認後は、EC2の仮想環境から抜けてください。
(v-env) ubuntu: $ deactivate
今回はAmazon Simple Queue Service (Amazon SQS)を使用した非同期処理を実行するLambdaについて解説しました。Amazon SQSへのメッセージの送信手順とLambdaでのAmazon SQSからのメッセージの取得方法およびそれらの実行環境の構築手順が理解できたと思います。
今回はサンプルということで単発のメッセージの受け渡しの紹介でしたが、実際の運用では複数のメッセージの受け渡しが発生します。ケースによってはメッセージの送信順に処理する必要が生じる場合があります。その場合はAmazon SQS のFIFOキューを使用するようにしてください。





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


