
Azure Application Gatewayとは?機能・構成要素や作成手順も解説
本コラムでは、Azure Application Gateway v2とは、Azure Load Balancerとの違いなどの基礎知識をはじめ、構成要素や作成手順、料金などをわかりやすく解説します。
![]()


多くのユーザーが頻繁に訪れて利用するオンラインサービスは、大量のデータを滞りなく処理し、さらに拡張していく必要があります。では、このようなデータ管理を効率的に行うにはどうすればいいのでしょうか? AWSではそのひとつの答えとして、数ミリ秒台のパフォーマンスを実現するデータベースである「Amazon DynamoDB」を提供しています。本コラムではその特徴や利用例を紹介します。

インターネット上で展開される、広告やゲーム、メディア配信、ショップ、金融、予約、IoTなど、非常に多くのユーザーの要求に対応しデータ処理を迅速に行うことが必要なビジネスが急成長しています。これらの事業者は、業務に必要不可欠な仕事量を適切に処理し、同時に拡張するデータに対して、効率的な対処を行うためのさまざまなデータ管理手法やサービスを採用しています。AWSのAmazon DynamoDBはそのひとつであり、数ペタバイトのデータや、秒間数千万回の読み書きリクエストをサポートするNoSQL (非リレーショナル)データベースサービスです。
Amazon DynamoDBの特徴のひとつが応答速度です。規模に関係なく、数ミリ秒台の応答時間を実現します。また、水平的に拡張(台数増加による拡張)できるため、パフォーマンスを維持しながら、事実上無制限にスケールできるという特徴も持っています。しかも、サーバーレスなので、データベースの構築の前にサーバーを用意したり、ソフトウェアをインストールしたり、運用中にパッチの適用や管理をしたりといった手間もありません。多くのAWSサービスと同様に、使用に応じてテーブルを柔軟に伸張して処理能力やコストを最適化できます。
NoSQLデータベースと比較されるのが、リレーショナルデータベース(RDBMS)です。両者にはどのような違いがあるのでしょうか。RDBMSでは、データを行と列で構成されるテーブルに正規化します。行・列・テーブル間の関係などの要素は厳密に定義され、データベースの参照整合性を維持していきます。拡張には、ハードウェアの演算処理能力を増強するか、読み取り専用の処理のレプリカを増やしていく必要があり、高コストとなることが懸念されます。
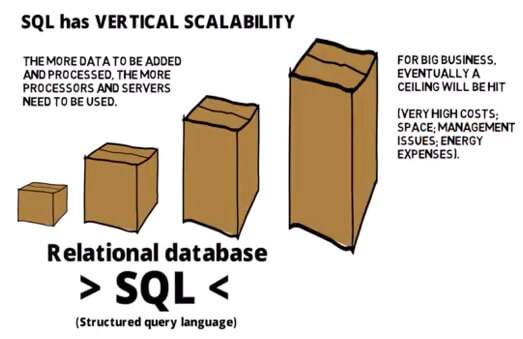
リレーショナルデータベースは扱うデータや処理が増えるとコンピューティング能力を増強しなければならないため、スケールに限界が訪れる
Amazon.comではかつてすべてのアクセスパターンをRDBMSで処理していました。しかし、そのスケールの限界からDynamoが開発されたといいます。DynamoDBが採用するNoSQLでは、キー/値、ドキュメント、グラフなどのさまざまなデータモデルを利用できます。
分散型アーキテクチャーを採用しており、テーブルのデータをパーティションに小分けして割り当てられるようになっています。パーティションは、設定した値以上になったり、容量がいっぱいになったりしたら追加されます。このため、ほぼ無限の規模で一貫したパフォーマンスの維持が期待できるのです。
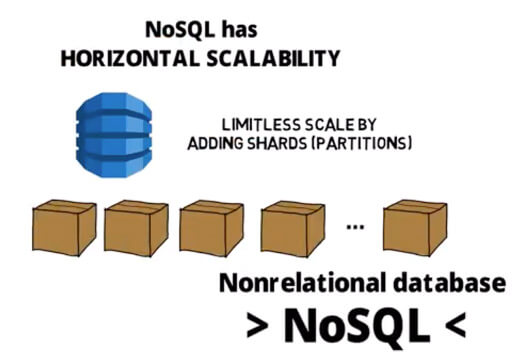
パーティションを追加することによって、水平方向に柔軟に拡張していけるため、パフォーマンス維持ができる
Amazon DynamoDB のテーブルは高速に動作するようSSDに格納されており、ほかのAWSサービスと同様に、複数のアベイラビリティーゾーンに自動的に複製されるため、可用性の高いシステム構築が可能です。
なお、AWSは決してRDBMSを否定しているわけではなく、用途に応じて選択できるように、RDMSサービスも提供しています。本サイトの別コラムでもAWSのRDBMSについて紹介していますので参考にしてみてください。
パーティション化して水平拡張できるというAmazon DynamoDB のテーブルの構造を見てみましょう。
テーブル内には、さまざまな属性を持つアイテムが展開されています。Amazon DynamoDBのテーブルで管理できるアイテムの数は無制限です。分散したデータを管理するために各アイテムには必ず「Partition Key」が必要です。また、これに加え、演算子を使うなどして関連情報をひとつの場所にまとめ、効率的に検索などの命令を実行できる 「Sort Key」もあります。
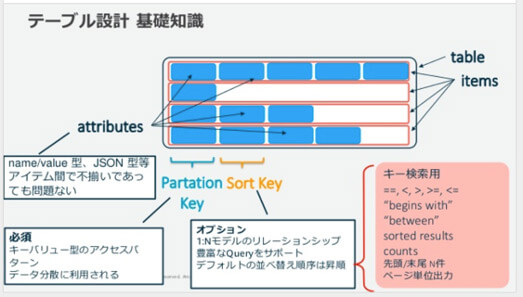
Sort Keyでは「begins with」「between」などの演算子を使用して、関連項目のグループを絞り込みできる
Amazon DynamoDBのインデックスには、LSI(Local Secondary Index)とGSI(Global Secondary Index)の2種類があります。LSI は、Partition Keyが同一なアイテムを、ほかのアイテムからの検索するために利用します。テーブルとインデックスの合計サイズは、Partition Keyごとに最大10GBに制限されています。
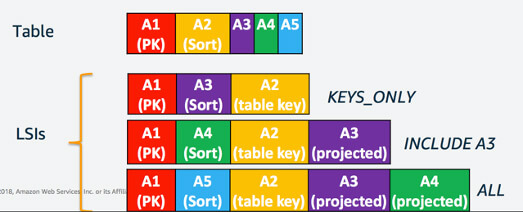
LSIのPartition Keyは同じで、Sort Key以外に絞り込み検索できるKeyを持てる
GSIは、異なるPartition Keyをまたいで検索できるインデックスです。アイテム群のサイズは10GB以上でも扱うことができます。なお、一定時間内に送信できるリクエスト数を制限するために、読み取りユニットと書き込みユニットを別々に準備する必要があります。
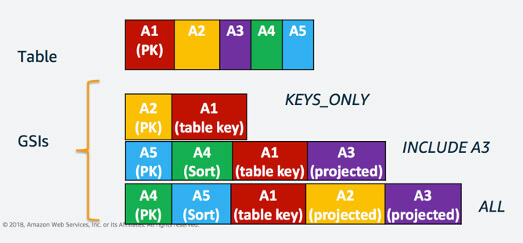
GSI はテーブルの並列バージョンを作成することによりPartition Key属性の代わりになる
リレーショナルデータベースでは、データを行と列で構成されるテーブルで管理され、基本的にそれらで検索します。
一方、NoSQLには多様なデータモデルと絞り込み方法があります。ここでいくつか紹介してみます。
Partition Keyを使ったテーブルやGSIで使うモデルです。ユーザーIDやE-mailアドアドレスなどから、それに応じた要素を抽出したい場合に使います。

Partition Keyに応じた要素を抽出
Partition KeyとSort Keyを使ったテーブルやGSIで使うモデルです。たとえば、ひとりのユーザーがN個のサービスを利用していてそれぞれのサービスの情報を管理する場合に使います。
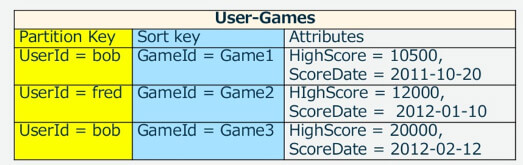
あるユーザーが複数のゲームを利用して、そのスコアやスコア取得日を管理
テーブルやGSIでPartition KeyとSort Keyの要素を入れ替えるモデルです。たとえば、ひとりのユーザーが複数のサービスを利用し、またひとつのサービスで複数のユーザーがいる場合で、各情報を管理したいときに使います。

Partition KeyとSort Keyの要素をスイッチして設計する
複数の条件からデータを絞り込むアプローチとして、filterの条件を指定する方法があります。たとえば、Partition Keyでユーザーを特定し、さらにそのユーザーの情報の要素をfilterによって抽出するのです。
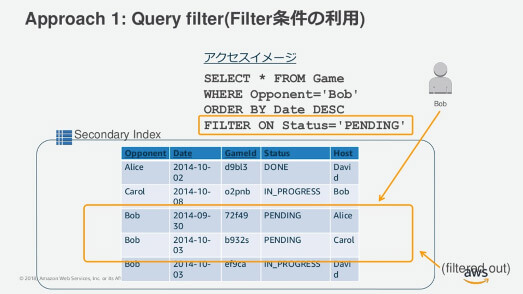
特定のユーザーの要素をfilterで導き出す
別のアプローチとして、キーを結合してその値から絞り込む方法があります。たとえば、「Status」と「Date」の二つのキーを結合して「StatusDate」というキーを作り、そこから特定の状態を絞り込みます。

結合によりできた新たなKeyの特徴から絞り込みする
データベースの項目内にSort Keyのある場合にのみ、データが書き込まれます。あるSort Keyがすべてのテーブル項目に現れない場合、そのインデックスはスパースであると定義されます。GSIをスパースに設定することで、必要な属性を含む項目のみ抽出することができます。
たとえば、複数のプレイヤーによる複数のゲームプレイ結果が保存されているデータベースの場合、Sort Keyがチャンピオン(Champ)の属性はテーブルすべてには現れず、ゲーム(特定の期間)ごとにひとつのはずです。それなら、チャンピオンの属性だけのインデックスにて処理することで、全体からスキャンするよりも処理のコストを少なくできるのです。
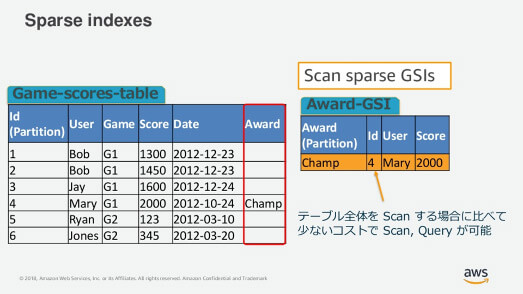
特定のSort KeyのGSI を利用することで、少ないコストでの処理を実現
DynamoDBテーブルでは、異なるデータをひとつのアイテムとして保持できます。ここから、ひとつのGSIで、複数の用途に利用できるような定義ができます。たとえば、従業員名簿などで、社員ID、名前、勤務地、役割、成績、住所などを管理しているとします。リレーショナルデータベースの場合には、社員を勤務地、職種などで検索したければ、その都度必要なインデックスが必要になります。
DynamoDBテーブルでは、GSIを多重に定義(Overloading)することで、新たなPartition Key、Sort Keyを使った複数の条件を検索することができます。ただし、テーブル構造が複雑になってしまう可能性があるので、実現したい要件をしっかり見極めて設計する必要があります。
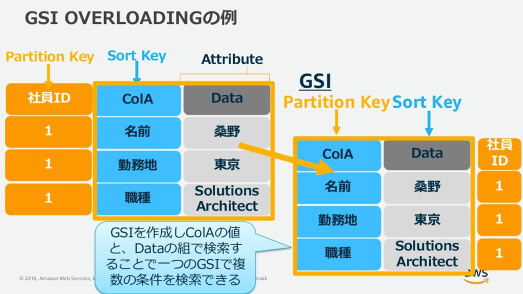
GSIの多重定義は、多数の異なるデータを処理したい場合に効果的
Amazon DynamoDBを利用すると、サーバー管理が不要で、自動的にスケールするWebアプリケーションやマイクロサービス、リアルタイム更新・同期を備えたモバイル/Webアプリケーションの構築が可能です。これらのアプリケーション構築の参考として、データベースへの書き込みに応じて処理を変更する、時系列データを扱う、特定のPartitionにアクセスが集中した場合の読み込み/書き込みなどのベストプラクティスを見てみましょう。
Amazon DynamoDBに対する項目の追加や削除、変更をイベントとして検出できる機能「DynamoDB Streams」と、イベントの発生に応じてプログラムを実行する環境を提供するサービス「AWS Lambda」を連携させたシステムの構築が可能です。たとえば、Amazon DynamoDBへの書き込みをきっかけとした、別テーブルの更新やログを保存するモバイルクライアント向けのプッシュ通知などを実行できます。これを「DynamoDB Triggers」と呼んでいます。
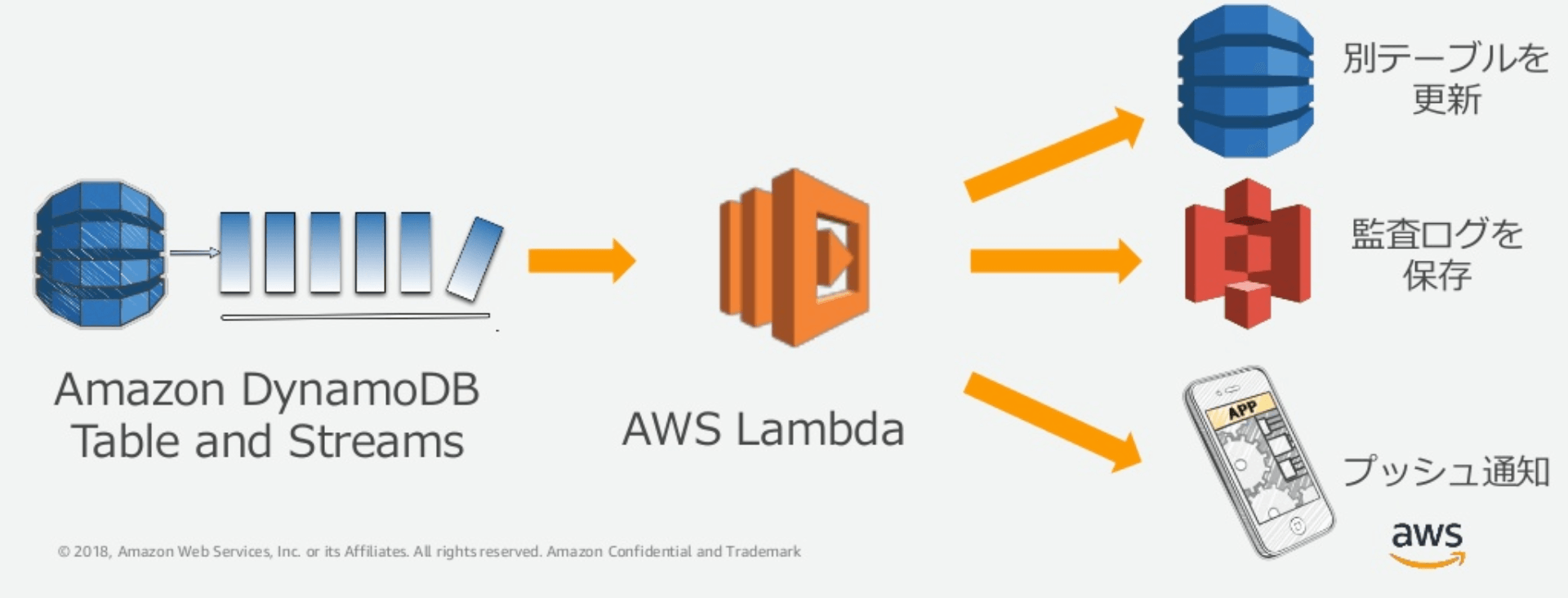
プレイヤーごとのゲームの得点に応じてランキング集計を非同期に実施できる
DynamoDB のアイテムには、TTLと呼ばれる有効期限を設定できます。DynamoDB Streamsを活用し、有効期限が切れデータベースから削除されるタイミングをきっかけとした、AWS Lambdaの処理が構築できます。関連性がないデータを処理が必要なデータベースから削除し処理済みデータをアーカイブするなどして、すべてまたは大量のアイテムを効率よく処理しながらリソースの最適化ができます。
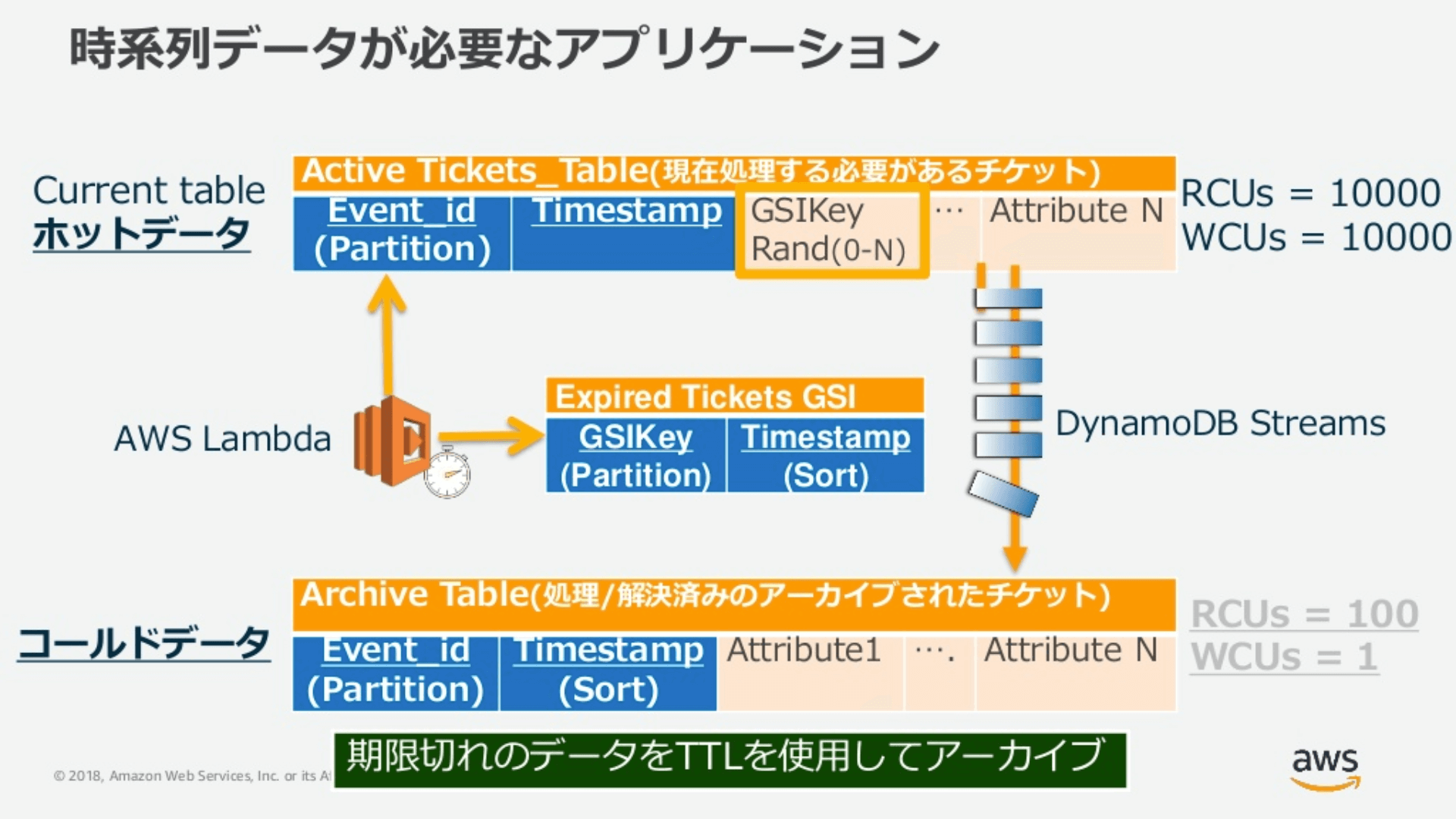
処理が必要なデータベース(ホットデータ)は読み書きのキャパシティを増やし、処理済みのデータベース(コールドデータ)のほうは限定してコストを抑える
また、本サイトの以下のコラムでもAWS Lambdaとの連携の具体例を紹介していますので、ご覧ください。
DynamoDBが高速なSSD上に展開されるとはいっても、特定の期間にアクセスが集中して応答が遅くなってしまう局面もあるでしょう。たとえば、リアルタイム入札や、人気ソーシャルゲームの期間限定イベント、人気商品やチケットの限定販売などです。
このような厳しい局面でもパフォーマンスを損なわないように、DynamoDB専用のインメモリキャッシュシステムとして提供されているのが「Amazon DynamoDB Accelerator (DAX)」です。DynamoDBの応答時間がミリ秒単位であるのに対し、DAXではマイクロ秒単位まで応答時間を短縮できます。なお、DAXはすでに別のキャッシュシステムを利用している環境や、読み出しに特化しているため書き込みの負荷が高いアプリケーションには向いていません。
DynamoDBへの書き込みが増えた場合の処理は、命令を受渡しするサービス「Amazon SQS」や、ストリーミングデータをリアルタイムで収集・処理・分析する「Amazon Kinesis」を使います。受け取ったデータをSQSやKinesisがいったん受け取り、DynamoDBへ書き込みを行う処理へ送信。この処理の部分(下図の「Workers」の部分)を必要に応じてスケールさせることで対処する方法です。
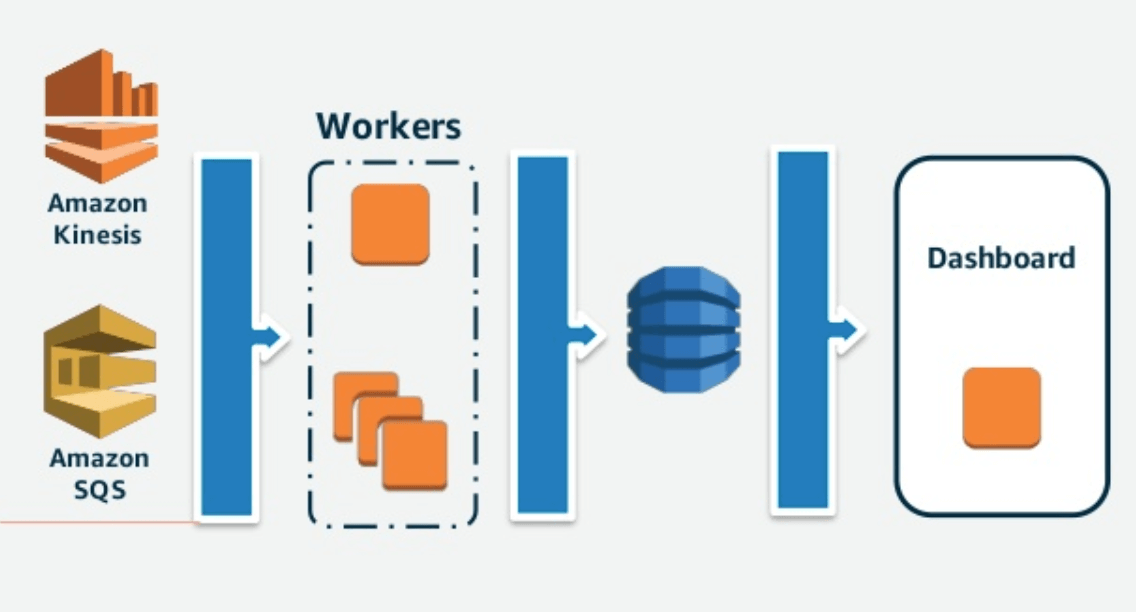
データベースに直接書き込みせず、中間の処理を増減して処理していく方法
また、書き込み操作をPartition Keyの値に乱数を連結するなどして複数のPartition Keyに分散させることによって、Partition Keyあたりの書き込みスループットを向上させる手法もあります。たとえば、同じ日付の「2020-05-10」のPartition Keyを、乱数を末尾につけて「2020-05-10.1」「2020-05-10.2」……「2020-05-10.10」のようにランダムに数値をつけて書き込むのです。ただし、「2020-05-10」自体のデータをすべて読み組むには、関連するすべてのPartition Keyの値を読み込んでマージする必要があります。
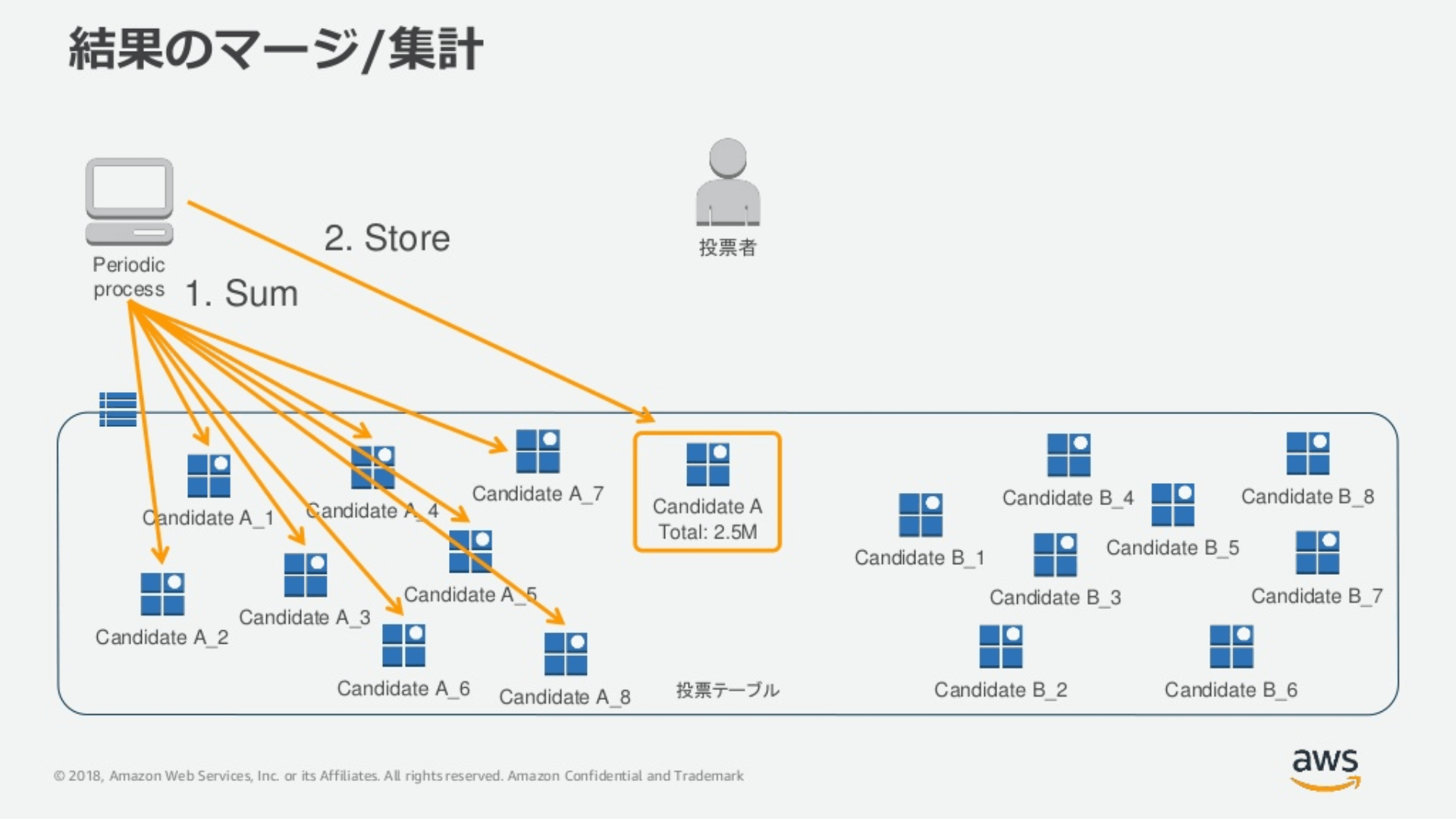
パーティションキーに乱数をつけて書き込みを分散化させたあと、トータルのデータを求める
DynamoDBの課金対象は、データベーステーブル内のデータの読み取り、書き込み、保存に加え、利用したオプションです。利用には「オンデマンド」と「プロビジョニング済み」の2種類のモードがあり、それぞれのモードにおけるテーブルの読み書き処理についてそれぞれ別の請求オプションがあります。
オンデマンドモードでは、アプリケーションがテーブルに対して実行したデータの読み取り/書き込みに対して料金が発生します。主にトラフィックが予想できない場合に向いています。プロビジョニング済みモードでは、アプリケーションに必要と予想される1秒あたりの読み込みと書き込みの回数を指定します。アプリケーショントラフィックが予測してコストを調整したい場合に向いています。
詳しくは、AWS公式サイトの料金ページをご覧ください
Amazon DynamoDB 料金
https://aws.amazon.com/jp/dynamodb/pricing/![]()
DynamoDBは、多様なデータモデルを利用でき、なおかつデータを分割して分散処理できるデータベースです。サーバー不要で、AWS内のSSDに展開されているため、高速かつ高い可用性のもとで利用できます。テーブルで管理できるアイテム数は無制限で、データ管理や抽出のためにPartition Key、Sort Keyを利用します。柔軟なデータ構造により、データの抽出をより効率的に実現することができます。
また、DynamoDBのイベントをきっかけに他の処理ができるよう、DynamoDB Streamsという機能があります。これとAWS Lambdaなど、AWSのほかのサービスと連携して別テーブルの作成、ログの保存、通知の送信といったさまざまな自動処理を行うことができます。
より高速な読み出し処理を求める場合には、インメモリキャッシュのAmazon DynamoDB Accelerator (DAX)があり、大量な書き込みを処理するために他のAWSサービスと連携したり、Partition Keyを分割したりするなどの工夫もなされています。
オンラインの広告技術やリアルタイム入札や、ソーシャルゲーム、メディア配信、人気商品やチケットの販売など、大量のユーザーやリクエストを即座に処理しなければならない事業やサービスには必要不可欠のデータベースといえるでしょう。





自社のクラウド導入に必要な知識、ポイントを
この1冊に総まとめ!
初めての自社クラウド導入、
わからないことが多く困ってしまいますよね。
クラウド化のポイントを知らずに導入を進めると、以下のような事になってしまうことも・・・
など、この1冊だけで自社のクラウド化のポイントが簡単に理解できます。
またNTT東日本でクラウド化を実現し
問題を解決した事例や、
導入サポートサービスも掲載しているので、
ぜひダウンロードして読んでみてください。
NTT東日本なら貴社のクラウド導入設計から
ネットワーク環境構築・セキュリティ・運用まで
”ワンストップ支援”が可能です!
特に以下に当てはまる方はお気軽に
ご相談ください。
クラウドを熟知するプロが、クラウド導入におけるお客さまのLAN 環境や接続ネットワーク、
クラウドサービスまでトータルにお客さまのお悩みや課題の解決をサポートします。
相談無料!プロが中立的にアドバイスいたします
クラウド・AWS・Azureでお困りの方はお気軽にご相談ください。


