
生成AIを独自にカスタマイズする方法~ファインチューニングとRAGについて詳しく解説~

生成AIは、人工知能技術の中でも特に注目されている分野であり、文章や画像、音声などのコンテンツを自動生成する能力を持っています。近年では、OpenAIのChatGPTやMetaのLlama 3といった大規模言語モデルが登場し、その高度な対話能力や文章作成能力がビジネスや日常生活に広く活用されています。本コラムでは、生生成AIを特定の用途に適応させるためのカスタマイズ手法である「ファインチューニング」と「RAG(Retrieval-Augmented Generation)」の両者についても紹介し、企業が生成AIを効果的に活用するための方法を探ります。
1. 生成AIとは
生成AIとは、人工知能(AI)の中でも、文章や画像、音声などのコンテンツを自動生成する技術のことを指します。例えば、文章生成AIであれば、人間のように自然な文章を作成したり、要約や翻訳を行ったりすることができます。近年では、OpenAIのChatGPTやオープンソースではMetaのLlama 3といった大規模言語モデルが登場し、高度な対話や文章作成が可能になっています。
こうした生成AIは、事前に膨大なテキストデータを学習しており、その中から適切な単語や表現を選んで文章を作り出します。しかし、初期状態のままでは特定の業務や用途に最適化されていないことが多く、企業や個人が実際に活用するためには、何らかの方法でカスタマイズする必要があります。そこで、生成AIのカスタマイズ手法として注目されているのが「ファインチューニング」と「RAG(Retrieval-Augmented Generation)」という技術です。
NTT東日本では、生成AIソリューションの導入支援を提供しています。生成AIソリューションの導入・運用にお悩みがある方は、ぜひ気軽にお問い合わせください。
2. カスタマイズ手法の紹介
生成AIを特定の用途に適応させる方法には、いくつかのアプローチがあります。その中でも、特に有効な方法として「ファインチューニング」と「RAG」があります。
2-1. ファインチューニングとRAG
ファインチューニングとは、事前学習された大規模言語モデル(LLM)のパラメータを追加のデータで再学習させ、特定のタスクやドメインに適応させる手法です。
一方、RAGは、AIが生成する文章に対して外部の情報を検索し、その情報をもとに回答を作る仕組みです。この二つの方法は、それぞれ異なるメリットを持っており、用途に応じて使い分けることが重要です。
ファインチューニングとRAGのイメージを定期テストに例えると、ファインチューニングしたモデルは一生懸命テスト勉強して試験に回答しており、RAGはカンニングペーパーを持ち込んでテストに回答しているといえそうです。
どちらも回答の精度を上げる取り組みですが、それぞれ得意とする用途が異なります。
特定の用途にモデルを特化させたい場合や、デプロイ後に追加の外部処理を避けたい場合はファインチューニングを使うのが望ましいです。一方で、広範な知識を扱うQAや情報更新が頻繁なシステムではRAGを使うのが望ましいです。また、両者を組み合わせることも可能です。
例えばまずRAGで外部知識を与え、その上でその文脈下での回答能力を微調整する、といったアプローチも考えられます。プロジェクトの要件(精度、応答速度、開発コスト、維持管理性など)を踏まえて適切な手法を選択・組み合わせることが重要と言えます。
以降でそれぞれの特長を紹介します。
2-2. ファインチューニングとは
ファインチューニングは、すでに学習済みのAIモデルを特定の目的に合わせて再学習させる手法です。例えば、医療分野での診断補助や、特定の企業のFAQ対応など、専門的な知識を求められる場面で有効です。通常の生成AIは汎用的な知識を持っていますが、医療や法律などの専門的な情報を詳細に理解しているわけではありません。そこで、その分野のデータを追加で学習させることで、より正確で適切な回答ができるようになります。
ただし、ファインチューニングを行うには、高性能なコンピュータや大量のデータが必要になることが多く、実施には一定のコストがかかります。例えばGPT-3(1750億パラメータ)のようなモデルをタスクごとに完全に微調整すると、高コストになる可能性が高いです。また、一度学習させた内容を変更するには再びトレーニングが必要になるため、頻繁に情報を更新しなければならない用途には向いていません。
一方でファインチューニングには、全てのパラメータを更新するFull fine-tuningや、ほとんどのパラメータを変更せず、一部の追加パラメータのみを更新するLoRA(Low-Rank Adaptation)などコンピューティングリソースを節約しつつファインチューニングを行う手法も存在します。
ファインチューニングを行う際には手元で用意できるコンピューティングリソースが手法を決める上で大きな制約となると言えるでしょう。
2-3. RAGとは
RAGは、AIが文章を生成する際に、外部のデータベースや検索システムを活用する方法です。例えば、企業の社内文書や新しいニュース記事など、モデルが事前に学習していない情報を参照しながら回答を作成できます。これにより、生成AIの持つ知識を補完し、より正確で新しい情報を提供することが可能になります。
RAGの大きな流れは以下になります。
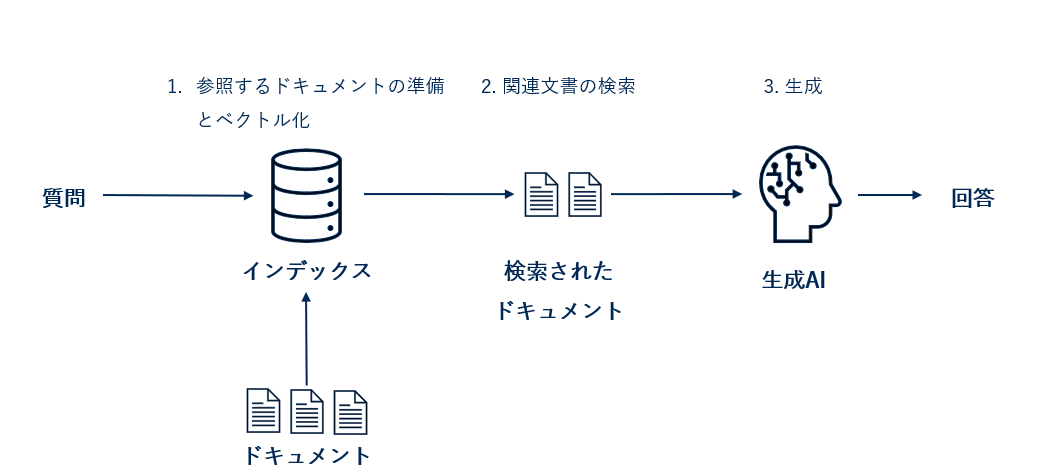
1. 参照するドキュメントの準備とベクトル化
まず、外部知識となるドキュメント群(例えば企業の資料や、新しいの記事など)を用意し、それらをベクトル埋め込み(高次元ベクトル表現)に変換します。埋め込みにはembedding modelというテキストをベクトルに変換する用途専用のモデルを用いて各文書を意味空間にマッピングします。
2. 関連文書の検索(Retrieval)
ユーザからの質問やプロンプトに対し、その埋め込みと事前に用意した文書埋め込み集合との類似度検索を行います。例えばベクトルデータベース(FAISS等)を使用して類似度の高い上位の文書を数件取得します。これにより、モデルが必要とする外部知識を動的に収集できます。
FAISSはMetaが開発したオープンソースのベクトルデータベースです。
3. 生成 (Generation)
上記コンテキスト付きプロンプトを生成AIに与え、回答を生成させます。モデルは提供されたコンテキストを参照しながら回答を作るため、事前知識に無い内容でもコンテキストに基づいた事実に即した回答を生成しやすくなります。
RAGの利点は、AIモデル自体を再学習する必要がないため、新しい情報をすぐに反映できることです。例えば、法律が改正された場合でも、データベースの情報を更新するだけで、AIの回答内容も自動的に新しいものになります。また、検索結果を引用することで回答の根拠を示しやすくなるため、情報の信頼性を向上させることもできます。
しかし、RAGにも課題があります。検索システムの精度が低いと、AIが適切な情報を取得できず、誤った回答を生成する可能性があります。また、検索対象のデータが整理されていないと、AIがどの情報を使うべきか判断しにくくなるため、事前にデータを整理する必要があります。
NTT東日本では、生成AIソリューションの導入支援を提供しています。生成AIソリューションの導入・運用にお悩みがある方は、ぜひ気軽にお問い合わせください。
3. 生成AIのカスタマイズならNTT東日本にお任せください
NTT東日本では、自治体向けに生成AIの環境提供や活用促進に関するコンサルティング、生成AIのユースケース創出に向けた技術支援を行っております。
また、企業の資料やデータに基づいた回答を行うためのRAGの活用についてもご支援しております。
NTT東日本の提供する生成AIソリューションの詳細はこちらの資料をご覧ください!
4. まとめ
生成AIを特定の用途に適した形にするには、ファインチューニングとRAGのどちらを選択するかが重要になります。ファインチューニングは、専門分野に特化した精度の高いモデルを作るのに適しており、一度学習させた知識を長期間活用できます。ただし、学習には時間とコストがかかるため、頻繁な情報更新が必要な場面には向きません。
一方、RAGは外部のデータを活用することで、新しい情報をリアルタイムに取り込めるという利点があります。特に、日々変化する法律やニュースをもとにAIを活用したい場合には、RAGが適しています。ただし、検索システムの精度やデータの整理が重要な課題となります。
どちらの手法も、それぞれの特長を理解した上で適切に活用することが求められます。企業や個人が生成AIを効果的に活用するためには、自分たちの目的や環境に応じたカスタマイズ手法を選択することが大切です。
NTT東日本では、生成AIソリューションの導入支援を提供しています。生成AIソリューションの導入・運用にお悩みがある方は、ぜひ気軽にお問い合わせください。
生成AIの活用に向けて、地域DXアドバイザーや生成AIエンジニアが徹底サポートいたします。
